
Digital transformation is changing the business world, making the role of IT and information technology more and more central and inalienable. The new needs and the new technologies required by the product teams to the technical teams are creating contaminations of roles, skills and knowledge, bringing together people who until now have never worked too closely together.
A recent example of this contamination comes from the increasing requests and solutions based on Artificial Intelligence and Machine Learning, which led to teams incorporating a “new” technical figure: the data scientist.
Over the years, we have witnessed the birth and consolidation of practices and tools designed to encourage conversation between all the different components of the team (product, development, operations). The advent of a new figure like the data scientist introduces into the choir a new voice that, by custom, is moulded to work in a different way.

Thiago De Faria, in his talk at Codemotion Milan 2018, highlighted how the DevOps culture, based on experimentation, continuous evaluation, sharing and automation, can be the key to unlocking the full potential of ML, AI, and data scientists within a company.
What data scientists do for AI
The traditional approach to solutions based on AI and ML involves a phase of exploration and cleaning of the available data and, in the event that there is something useful in the data, the construction and the development of a model based on this data.
The solutions based on AI and ML are obviously characterised by not relying on a predefined set of “if then else” conditions, which makes them on the one hand more difficult to debug (it is not possible to identify the point of the error) and, on the other, heavily dependent on the validity of the starting data.
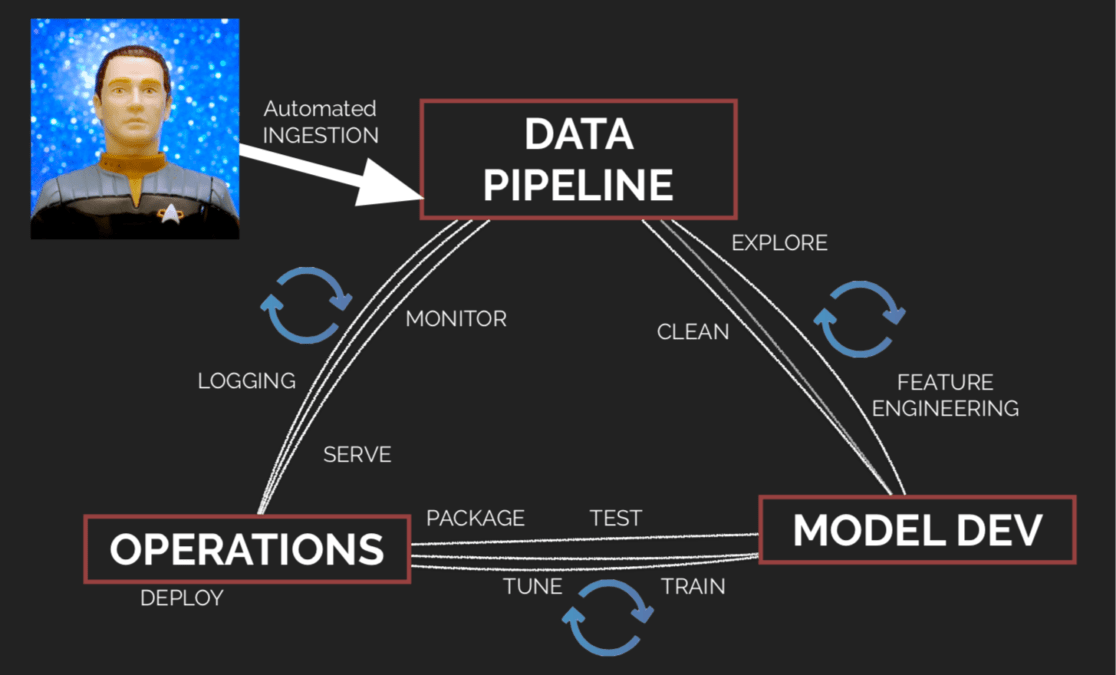
When an AI / ML solution is implemented in and for the “business”, in addition to the most common known issues – brownfield, data change, businesses not knowing what they want/need, deployment and monitoring – more specific issues are added.
Most of those new issues are largely attributable to the different methodologies with which data scientists are used to work. For instance, data scientists could have a poor approach towards code management; they are more accustomed with local development and without versioning. Working within a business-driven organisation requires documenting your work for the next people, packaging it to deploy on production and measuring its effectiveness from end-user feedback.
Of course, there is no silver bullet, as Thiago said, but a cultural change and new ways of working can really save the day. The most effective source of inspiration is the DevOps culture.
Fighting Bias, Drift and Fragility with Culture, Automation, Measurement and Sharing
The DevOps movement has taught us that collaboration – cross-functional collaboration – is the foundation of successful teams. Involving data scientists in discussions is the first necessary step. Likewise, data scientists must allow team members to understand the specificity of their role and knowledge.
Furthermore, data scientists can take advantage of the methodologies and practices refined in the past decades by software development teams and bring them back into their workflow. The first step to do this is to admit, as Thiago says, that “local data science is dead”.
It is, therefore, useful and necessary to leave your laptop and move to the cloud, or at least to a shared environment, and set a ML development pipeline from day one to allow continuous evaluation of the model.
Coding at Room 3 with @thiagoavadore @LINKITGroup #AI #MachineLearning #DeepLearning #codemotion pic.twitter.com/KyrCbTZHLX
— Codemotion (@CodemotionIT) November 29, 2018
Such an approach allows you to face with greater certainty typical bugs related to ML: bias (i.e. “dirty” datasets that lead to incorrect blackbox models), drift (i.e. the need to recalibrate or resync the model based on new data) and fragility (i.e. all external variables that can change without control) are all ML bugs that are usually difficult to identify before putting the model into production.
This is the reason why the practices derived from the DevOps are useful both to identify and to manage these situations in time and efficiently.
In recent times, several tools, especially open source tools, have been created and consolidated specifically designed for ML’s development lifecycle. Spark can now run on Kubernets. Tensorflow, kubeflow, MLflow and other ML toolkits allow us to train, package, deploy and serve models on cloud.