
¿Necesitáis realmente el último modelo estado del arte para realizar vuestro trabajo diario? Si vuestra respuesta es «sí», ¿estáis seguros de que no os ha engañado el marketing de las grandes tecnológicas? Anthropic acaba de lanzar Claude Opus 4.8, OpenAI ya tiene en marcha la próxima versión de ChatGPT, y todos nos empujan a perseguir el modelo más reciente como si nuestra productividad dependiera de ese último decimal de un benchmark. Sin embargo, para el 90% de las actividades cotidianas, un modelo eficiente como, por ejemplo, DeepSeek V4 Flash cuesta una fracción del precio y hace exactamente lo mismo. ¿Os recuerda a algo? A mí sí, e intentaré contároslo.
El 28 de mayo de 2026, Anthropic lanzó Claude Opus 4.8, presentado con el tono habitual de evento cósmico. Y mirando de cerca, ciertamente hay mejoras, pero no tan sensacionales: el benchmark SWE-bench Verified sube del 87,6 al 88,6 por ciento, mientras que el SWE-bench Pro pasa del 64,3 al 69,2. El modelo supera a GPT-5.5 en la mayoría de las pruebas publicadas, con un margen de unos 121 puntos ELO en la puntuación GDPval-AA. Hasta aquí, todo bien: el progreso existe, pero ¿de cuánto? Y sobre todo, ¿lo necesitáis?

Luego miráis el precio, y ahí es donde comienza la verdadera historia. Opus 4.8 cuesta 5 dólares por millón de tokens de entrada y 25 de salida, idéntico a Opus 4.7. También hay una modalidad «fast» a 10 y 50 dólares respectivamente, para quienes quieren la máxima velocidad sin mirar la cartera. La estabilidad de tarifas es una elección pensada para el mercado enterprise, donde quienes han integrado a Claude en pipelines de producción no tienen que reescribir presupuestos ni renegociar presupuestos de IT. Pero para el usuario individual, incluso el que tiene una suscripción Pro, esa tarifa se traduce en cuotas que se agotan rápidamente, especialmente para tareas intensivas. Y aquí comienza la paradoja: el modelo más potente disponible es también el que muchos usuarios pueden usar con menos libertad.
La reacción de la comunidad ha sido, como suele pasar en estos casos, bastante reveladora. En Reddit y en X se ha mezclado el hype por las mejoras en programación con el típico enfado por las limitaciones reales del sistema.
La duda que se repite en los posts más críticos es siempre la misma: ¿de verdad compensa pagar ese precio solo por ganar unos pocos puntos porcentuales en un benchmark? Y no es una queja sin más ni algo que se pueda despachar como “no entienden la tecnología”; es una pregunta bastante razonable que merece tomarse en serio.
La máquina de los lanzamientos
Abrid la timeline de los modelos LLM y miradla con atención. Lo que veis ya no es la sucesión ordenada de generaciones bien diferenciadas, un GPT-3 luego un GPT-4 luego el siguiente paso, cada uno con años de diferencia y mejoras radicales. Lo que veis hoy se parece mucho más al calendario de lanzamientos de un fabricante de smartphones de gama alta: lanzamientos continuos, numeración que sube a saltos decimales, cada anuncio construido para parecer un avance mientras introduce ajustes incrementales.
Solo en el mes de mayo de 2026, para dar una idea de la medida, salieron Claude Opus 4.8, Qwen3 Coder Next, MiniMax M2.5 Highspeed, MiniMax M2.7 y Gemini 3.5 Flash. En abril habían llegado DeepSeek V4 Pro y Flash, MiMo V2.5 de Xiaomi y Qwen3.6 en sus variantes. En marzo, GPT-5.5 Pro. El ritmo es el de una industria que ha transformado el lanzamiento de modelos en un acto comunicativo antes incluso que técnico: demostrar vitalidad, responder a los competidores, alimentar la atención mediática.
El paralelismo con el mercado de los smartphones no es una metáfora perezosa, es una estructura industrial que se está replicando casi punto por punto. Apple lanza iPhone cada septiembre. Samsung responde con Galaxy S pocos meses después. Google en medio con Pixel. Cada año, para cada dispositivo, la presentación se construye en torno a esa cámara ligeramente mejorada, a ese procesador unos puntos porcentuales más rápido, a esa pantalla con unos nits más de brillo. El ciclo se ha convertido en un mecanismo de marketing antes que de innovación, y quienes lo estudian desde fuera han comenzado a preguntarse si no ha llegado el momento de frenar, tanto por la utilidad real de las actualizaciones como por las implicaciones ambientales de producción y eliminación.
En la AI el mecanismo es análogo pero más acelerado, porque los costes de producción de un nuevo modelo, aunque enormes, no incluyen la logística física de millones de dispositivos de hardware. El resultado es un ritmo aún más frenético, con la diferencia de que aquí no se tira el teléfono viejo sino que se sigue pagando una suscripción, mientras se nos dice que el modelo del mes pasado ya está obsoleto.
Vale la pena preguntarse quién guía realmente esta aceleración. Anthropic lanzó Opus 4.8 cinco meses después de Opus 4.7, y el momento del lanzamiento no parece casual: GPT-5.5 había salido pocas semanas antes y DeepSeek V4 estaba ganando terreno con una relación calidad-precio agresiva. La carrera no está dictada solo por el progreso tecnológico, sino por la necesidad de responder a los competidores en el momento en que se acercan demasiado. Es una dinámica que quienes vivieron las guerras de los smartphones de los años diez reconocen perfectamente.
Cuando más potente no significa más útil
Existe un concepto en economía que se llama rendimiento marginal decreciente: cada unidad adicional de entrada produce un incremento de salida cada vez más pequeño. Un campo fertilizado una vez produce mucho más que un campo no fertilizado. Fertilizarlo una segunda vez aporta un beneficio, pero menor. Una tercera vez, aún menos. En cierto punto, añadir fertilizante no sirve de nada, o incluso daña la cosecha.
Estamos ahí. O muy cerca.
La frontera de los modelos lingüísticos continúa técnicamente avanzando, los benchmarks suben, las capacidades se afinan en áreas específicas como el coding agéntico o el razonamiento multi-paso. Pero la distancia percibida entre un modelo flagship y el siguiente se estrecha con cada generación, mientras que el coste para acceder a ellos no baja al mismo ritmo. El usuario que usaba GPT-4 en 2023 tenía la sensación de tocar algo radicalmente nuevo comparado con GPT-3. El usuario que pasa de Opus 4.7 a Opus 4.8 hoy difícilmente tendrá la misma sensación, a menos que esté trabajando en tareas de programación muy específicas donde ese salto del 64 al 69 por ciento en SWE-bench Pro marca realmente la diferencia.
El problema no es que los modelos dejen de mejorar. El problema es el desajuste creciente entre la narrativa del lanzamiento, construida para parecer un avance de época, y la experiencia real de la mayoría de los usuarios que para sus tareas diarias (escritura, análisis de datos, automatización de flujos de trabajo, generación de código de complejidad media) obtendrían resultados prácticamente idénticos con un modelo mucho menos costoso.
Y aquí entra en escena el lado de la historia que las grandes tecnológicas prefieren no contar. Mientras Anthropic y OpenAI construían sus modelos flagship, el panorama de los modelos alternativos se estaba volviendo cada vez más rico y capaz. DeepSeek lanzó V4 en dos variantes, Pro y Flash, ambos open source con licencia MIT, con una arquitectura Mixture of Experts que aporta 1,6 billones de parámetros totales en el modelo Pro, de los cuales solo 49 mil millones están activos durante la inferencia. ¿El precio? Una fracción del de los modelos occidentales equivalentes. La ambición declarada no es ganar en cada métrica individual, sino redefinir la relación entre capacidad y coste. Mirando los resultados en tareas concretas, el argumento se sostiene.
Luego hay una dirección que vale la pena seguir aunque hoy todavía requiera hardware para unos pocos. El 7 de mayo de 2026, Salvatore Sanfilippo, conocido en la comunidad open source como Antirez, lanzó DS4: un motor de inferencia local escrito en C puro, optimizado específicamente para DeepSeek V4 Flash en Apple Silicon. Quienes conocen la historia del software reconocen el nombre: Antirez es el mismo que en 2009 creó Redis por sí solo, la base de datos in-memory que hoy funciona bajo gran parte de la infraestructura web global, y que dirigió durante once años con la obsesión artesanal de quien escribe código como acto expresivo antes que como solución técnica.
Siete días de trabajo a catorce horas diarias, 10.700 estrellas en GitHub a los pocos días del lanzamiento. El proyecto utiliza una cuantización asimétrica agresiva, 2 bits para la mayoría de los parámetros y 8 para los críticos, y permite ejecutar un modelo de 284 mil millones de parámetros totales en un Mac con 128 GB de RAM, manteniendo el contexto conversacional en el SSD en lugar de en la memoria unificada. El veredicto del propio Antirez, que no es dado a entusiasmos fáciles, fue inequívoco: es la primera vez que encuentra un modelo local que usa para cosas serias que normalmente habría pedido a Claude o GPT. Hoy DS4 requiere un Mac Studio o un Mac Pro con configuración máxima, hardware de varios miles de euros accesible para pocos. Pero cuando es Salvatore Sanfilippo quien traza una dirección, vale la pena mirar a dónde lleva.
Big Pickle y la prueba de campo
Permitidme traer un modesto ejemplo reciente y personal, porque a veces la teoría se entiende mejor cuando tiene un nombre extraño y un sitio web por rehacer.
Hace unas semanas me encontré con algunos sitios web que actualizar: aspecto anticuado, arquitectura sobredimensionada para las necesidades reales, alojamiento en una plataforma pensada para aplicaciones dinámicas cuando en realidad se trataba de sitios estáticos. Clásica deuda técnica que se acumula silenciosamente hasta que se vuelve lo suficientemente molesta como para no poder ser ignorada más tiempo.
Usé OpenCode, un entorno de desarrollo asistido por AI que integra diversos modelos y permite trabajar directamente sobre el código con una interfaz de línea de comandos. Escribí un prompt preciso pero sintético, inserté el enlace al sitio viejo como referencia visual y estilística, y en pocos minutos tenía la primera versión funcional del sitio nuevo: estructura moderna, código limpio, carga drásticamente más rápida. Unas pocas iteraciones para ajustar detalles, y el trabajo estaba hecho. Luego repetí el proceso para los otros sitios. Ni siquiera una jornada de trabajo total para actividades que podría haber pospuesto durante meses.
El detalle interesante no es la herramienta en sí sino el modelo que usé. Entre las opciones gratuitas disponibles había uno con un nombre que habría hecho reír a cualquier marketing manager de una empresa tecnológica seria: «Big Pickle». Ninguna presentación, ningún comunicado de prensa, ningún benchmark publicitado. Quién sabe qué modelo se esconde tras ese seudónimo, probablemente algo más conocido con un nombre diferente por razones de licencias o experimentación. Junto a él, también gratuitos, DeepSeek V4 Flash, MiMo V2.5 de Xiaomi y Nemotron 3 Super de NVIDIA.
Elegí Big Pickle, esencialmente por curiosidad. El resultado fue perfecto para el propósito. Ningún límite de cuota alcanzado, ningún coste, ninguna espera por un modelo demasiado cargado. Y sobre todo: ninguna necesidad de usar un modelo de frontera para ese tipo de tarea. ¿Podría haber abierto Claude con Opus 4.8 y gastar créditos valiosos para obtener exactamente el mismo resultado? Sí. ¿Tenía sentido hacerlo? En mi opinión, no.
Este es el punto central de la estrategia de switching que quiero introducir. No se trata de demonizar los modelos flagship o de sostener que son inútiles, porque no lo son. Se trata de desarrollar la conciencia crítica para entender cuándo son necesarios y cuándo son un lujo no requerido por la tarea que se tiene delante.
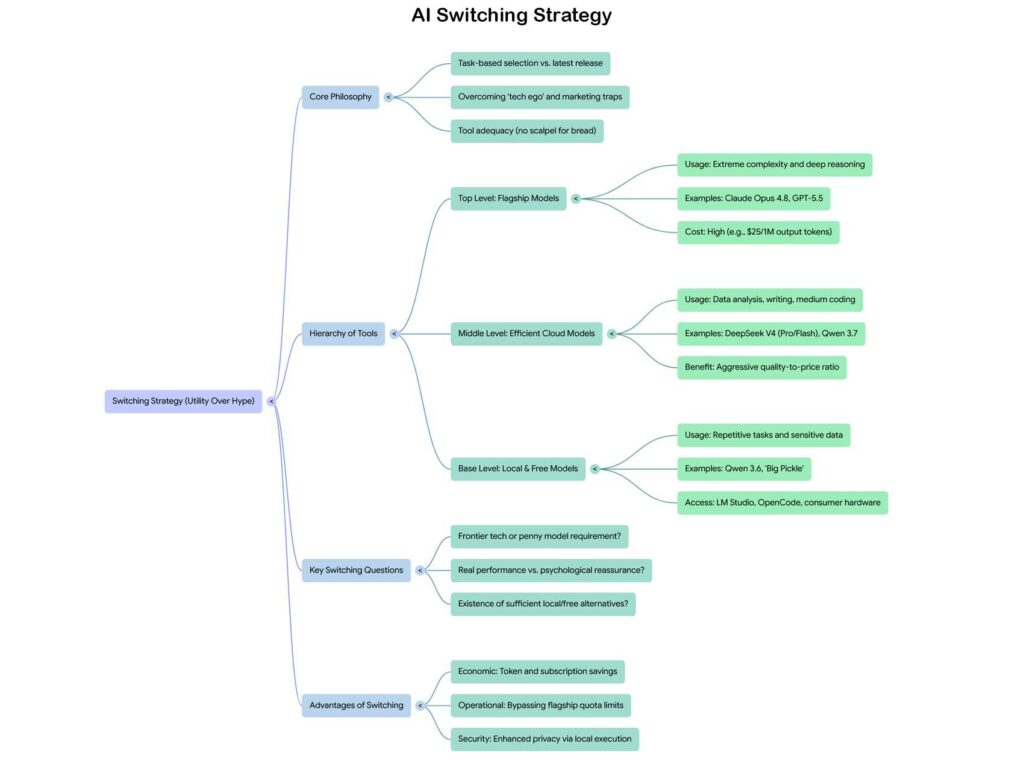
Mapa de estrategia de conmutación de IA
El mapa de las herramientas
Pensar en la AI como una única herramienta monolítica que actualizar periódicamente es el error conceptual que el marketing de las grandes tecnológicas quiere que cometamos. Es como pensar en vuestro juego de utensilios de cocina como una única entidad a sustituir cada vez que sale el último modelo del cuchillo de chef, ignorando que para pelar una patata basta un pelador y que usar un cuchillo Shun de 300 euros para ese propósito no produce mejores patatas.
La estrategia de switching parte de una pregunta sencilla: ¿qué estoy intentando hacer y qué nivel de capacidad es realmente necesaria para hacerlo bien?
Para tareas de extrema complejidad (escritura de sistemas críticos, razonamiento sobre problemas multi-paso con muchas variables interdependientes, análisis de documentos largos y densos que requieren comprensión profunda del contexto), los modelos flagship todavía tienen una ventaja real y medible. Si estáis escribiendo el kernel de un sistema operativo o construyendo un agente autónomo para pipelines de producción enterprise, esa ventaja vale el coste.
Para todo lo demás, que cubre la gran mayoría del uso diario, el panorama alternativo es rico y a menudo gratuito o casi. DeepSeek V4 Flash gestiona de forma excelente el análisis de datos, el scraping, la reconstrucción de datasets y la generación de texto estructurado, a una fracción del coste. Los modelos de la familia Qwen de Alibaba, que han llegado a las versiones 3.6 y 3.7, compiten con los mejores modelos occidentales en muchos benchmarks a pesar de estar disponibles de forma gratuita vía API o ser ejecutables en local en hardware de consumo.
Y aquí es donde la conversación se vuelve realmente interesante, porque el local ya no es una opción para nerds con racks de servidores en el sótano. Como exploré con Qwen 3.6 de 35 mil millones de parámetros, un PC con 32 GB de RAM y una GPU con 16 GB de VRAM (configuración que ya no es extraordinaria en 2026) logra ejecutar modelos de ese tamaño con un rendimiento sorprendente en tareas reales. LM Studio ha hecho que la instalación y gestión de modelos locales sea accesible para cualquiera que sepa usar una interfaz gráfica, sin perder una tarde en configuraciones de terminal. La ventaja del local no es solo económica: es la privacidad completa de los datos, la ausencia de límites de cuota y la disponibilidad offline.
La jerarquía práctica que emerge de este análisis está estratificada. En la cima, para las tareas que realmente lo requieren, los modelos flagship de pago. En medio, para la mayor parte del trabajo diario, modelos como DeepSeek V4 Pro o Flash, accesibles vía API a costes reducidos o mediante interfaces como OpenCode que agrupan a múltiples proveedores. En la base, para tareas repetitivas, rápidas o que involucran datos sensibles, modelos locales en hardware de gama media. Y transversalmente, para quienes quieren explorar sin gastar, una serie de opciones gratuitas que hace un año habrían sido consideradas de excelente calidad y que hoy, para muchos escenarios, son simplemente más que suficientes.
Vale la pena realizar este ejercicio mental al menos una vez al año, aunque sea solo con lápiz y papel. Elija una tarea que realice con frecuencia por ejemplo, resumir documentos extensos o generar borradores de texto estructurado y pregúntese cuánto le cuesta realizarla con el modelo que usa habitualmente. Luego, compare el costo de la misma tarea con un modelo alternativo capaz de gestionarla igual de bien. La diferencia, multiplicada por su volumen mensual, es su costo de oportunidad: lo que paga no por un mejor rendimiento, sino simplemente por no haber realizado la comparación.
Las cifras específicas cambian constantemente, los proveedores ajustan los precios, aparecen nuevos modelos, las promociones caducan y cualquier tabla comparativa publicada hoy ya está parcialmente obsoleta mañana. Pero la lógica detrás del cálculo sigue siendo válida independientemente de quién gane la competencia en un momento dado: el modelo adecuado no es el más potente disponible, sino aquel cuyo costo refleja realmente el valor que le aporta, para esa tarea y con ese volumen.
Elegir, no perseguir
Hay una escena en el videojuego Disco Elysium en la que el protagonista, un detective con la memoria destruida, debe reconstruir su propia identidad pieza por pieza eligiendo conscientemente qué habilidades desarrollar, qué valores abrazar, qué tipo de persona volver a ser. El juego os pone ante decenas de opciones, todas plausibles, todas con sus propias ventajas, y os pide que resistáis la tentación de quererlas todas. La capacidad de elegir con criterio, no la de acumular, es lo que construye un personaje coherente y capaz.
El paralelo con la elección de las herramientas de AI es menos forzado de lo que parece. El mercado hoy nos ofrece decenas de modelos, todos presentados como indispensables, todos con algo que ofrecer. La respuesta instintiva, alimentada por años de marketing tecnológico, es perseguir el mejor disponible en cada momento. La respuesta inteligente es construir una jerarquía propia y consciente, basada en las tareas reales a las que os enfrentáis cada día.
Esto no significa ignorar los progresos. Opus 4.8 es un modelo mejor que Opus 4.7, y lo será aún más para quienes trabajan en coding agéntico avanzado o en pipelines enterprise donde la reducción de alucinaciones vale por sí sola el coste de la migración. Las mejoras existen, incluso cuando son incrementales. La pregunta no es si los modelos mejoran, sino si esa mejora vale para vuestro caso de uso específico, ahora, con el presupuesto que tenéis.
Las preguntas que vale la pena hacerse antes de cada upgrade son pocas y directas. ¿La tarea que debo realizar requiere realmente capacidades de razonamiento al límite de la frontera tecnológica, o es algo que un modelo de un céntimo por millón de tokens resuelve igual de bien? ¿Estoy pagando por un rendimiento objetivamente mejor en mi flujo de trabajo real, o estoy pagando por la tranquilidad psicológica de tener el último modelo? ¿Existe una versión local o gratuita que gestione esta tarea de forma suficiente para mi expectativa?
Las grandes empresas tecnológicas tienen todo el interés en hacernos responder siempre «sí, necesito el último modelo que ha salido». Es el mecanismo que alimenta las suscripciones, las renovaciones, la dependencia del proveedor. No es necesariamente mala fe, es simplemente la lógica de un mercado que ha aprendido a monetizar la ansiedad por el rendimiento tecnológico del mismo modo que los fabricantes de smartphones han monetizado la ansiedad por el símbolo de estatus. El ciclo se autosostiene porque funciona, al menos para quien lo vende.
La alternativa no es el ludismo ni la nostalgia por los modelos de hace dos años. Es la lucidez de quien entiende que el valor de una herramienta no se mide por su posición en la clasificación, sino por su adecuación a la tarea. Un bisturí de titanio no corta mejor el pan que un cuchillo de cocina ordinario. Un modelo de 25 dólares por millón de tokens de salida no produce mejores correos electrónicos que uno que cuesta dos.
La verdadera competencia que este momento histórico requiere no es saber usar el modelo más potente disponible. Es saber elegir, cada vez, el adecuado.
Todos los precios y benchmarks citados hacen referencia a la información disponible en el momento de la publicación, mayo de 2026. El panorama de los modelos de AI evoluciona rápidamente: verificad siempre las fuentes primarias de los proveedores individuales para obtener datos actualizados.
