
Do you really need the latest state-of-the-art model to do your daily work? If your answer is “yes,” are you sure you haven’t been misled by big tech marketing? Anthropic has just launched Claude Opus 4.8, OpenAI already has the next version of ChatGPT in the works, and everyone is pushing us to chase the most recent model as if our productivity depended on that last decimal of a benchmark. Yet, for 90% of daily activities, an efficient model like, for example, DeepSeek V4 Flash costs a fraction of the price and does exactly the same thing. Does this remind you of something? It does to me, and I will try to tell you about it.
On May 28, 2026, Anthropic released Claude Opus 4.8, presented with the usual tone of a cosmic event. And looking closely, there are certainly improvements, but not so sensational: the SWE-bench Verified benchmark rises from 87.6 to 88.6 percent, while SWE-bench Pro goes from 64.3 to 69.2. The model surpasses GPT-5.5 in most published tests, with a margin of about 121 ELO points on the GDPval-AA score. So far, so good—progress is there, but by how much? And above all, do you need it?

Then you look at the price, and that’s where the real story begins. Opus 4.8 costs 5 dollars per million input tokens and 25 for output, identical to Opus 4.7. There is also a “fast” mode at 10 and 50 dollars respectively, for those who want maximum speed without looking at their wallet. Rate stability is a choice designed for the enterprise market, where those who have integrated Claude into production pipelines don’t have to rewrite quotes or renegotiate IT budgets. But for the individual user, even those with a Pro subscription, that rate translates into quotas that run out quickly, especially for intensive tasks. And here begins the paradox: the most powerful model available is also the one that many users can use less freely.

The reaction of the communities was, as always in these cases, an interesting thermometer. On Reddit and X, excitement for coding improvements mixed with frustration over practical limits. The implicit question in the most critical posts was always the same: is it really worth paying this price for a few more percentage points on a benchmark? It is a question that deserves to be taken seriously, not dismissed as the complaint of someone who doesn’t understand the value of technology.
The release machine
Open the LLM model timeline and look at it carefully. What you see is no longer the orderly succession of distinct generations—a GPT-3 then a GPT-4 then the next step, each years apart and with radical improvements. What you see today looks much more like the release calendar of a high-end smartphone manufacturer: continuous releases, numbering that goes up in decimal steps, every announcement built to seem like a breakthrough while introducing incremental adjustments.
In May 2026 alone, just to give a sense of scale, Claude Opus 4.8, Qwen3 Coder Next, MiniMax M2.5 Highspeed, MiniMax M2.7, and Gemini 3.5 Flash were released. In April, DeepSeek V4 Pro and Flash, Xiaomi’s MiMo V2.5, and Qwen3.6 in its variants arrived. In March, GPT-5.5 Pro. The pace is that of an industry that has transformed the release of models into a communicative act even before a technical one: demonstrating vitality, responding to competitors, fueling media attention.
The parallelism with the smartphone market is not a lazy metaphor; it is an industrial structure that is replicating itself almost point for point. Apple launches iPhones every September. Samsung responds with Galaxy S a few months later. Google in between with Pixel. Every year, for every device, the presentation is built around that slightly improved camera, that processor a few percentage points faster, that screen with a few more nits of brightness. The cycle has become a marketing mechanism before one of innovation, and those who study it from the outside have begun to wonder if it’s time to slow down, both for the real utility of the updates and for the environmental implications of production and disposal.
In AI, the mechanism is analogous but more accelerated, because the production costs of a new model, though enormous, do not include the physical logistics of millions of hardware devices. The result is an even more frantic pace, with the difference that here you don’t throw away the old phone but continue to pay a subscription, while being told that last month’s model is already obsolete.
It’s worth asking who is really driving this acceleration. Anthropic released Opus 4.8 five months after Opus 4.7, and the timing of the launch doesn’t seem accidental: GPT-5.5 had come out a few weeks earlier, and DeepSeek V4 was gaining ground with an aggressive quality-price ratio. The race is dictated not only by technological progress but by the need to respond to competitors when they get too close. It is a dynamic that those who lived through the smartphone wars of the 2010s recognize perfectly.
When more powerful doesn’t mean more useful
There is a concept in economics called diminishing marginal returns: every additional unit of input produces an increasingly smaller increase in output. A field fertilized once produces much more than an unfertilized field. Fertilizing it a second time brings a benefit, but a smaller one. A third time, even less. At a certain point, adding fertilizer is useless or even damages the crop.
We are there. Or very close.
The frontier of language models technically continues to advance, benchmarks rise, and capabilities are refined in specific areas such as agentic coding or multi-step reasoning. But the perceived distance between one flagship model and the next narrows with each generation, while the cost to access them does not drop in step. The user who used GPT-4 in 2023 felt they were touching something radically new compared to GPT-3. The user switching from Opus 4.7 to Opus 4.8 today is unlikely to have the same feeling, unless they are working on very specific programming tasks where that jump from 64 to 69 points on SWE-bench Pro really makes the difference.
The problem is not that models stop improving. The problem is the growing misalignment between the launch narrative—built to seem like an epochal breakthrough—and the real experience of the majority of users who, for their daily tasks (writing, data analysis, workflow automation, medium-complexity code generation), would have practically identical results with a much less expensive model.
And here enters the side of the story that big tech prefers not to tell. While Anthropic and OpenAI were building their flagship models, the landscape of alternative models was becoming richer and more capable. DeepSeek launched V4 in two variants, Pro and Flash, both open source with an MIT license, with a Mixture of Experts architecture that brings 1.6 trillion total parameters to the Pro model, of which only 49 billion are active during inference. The price? A fraction of that of equivalent Western models. The declared ambition is not to win in every single metric, but to redefine the relationship between capability and cost. Looking at results on concrete tasks, the argument holds.
Then there is a direction worth following even if today it still requires hardware for the few. On May 7, 2026, Salvatore Sanfilippo, known in the open source community as Antirez, released DS4: a local inference engine written in pure C, specifically optimized for DeepSeek V4 Flash on Apple Silicon. Those who know software history recognize the name: Antirez is the same person who in 2009 created Redis single-handedly, the in-memory database that today runs under much of the global web infrastructure, and who led it for eleven years with the artisanal obsession of those who write code as an expressive act even before a technical solution.
Seven days of work at fourteen hours a day, 10,700 stars on GitHub within days of release. The project uses aggressive asymmetric quantization—2 bits for most parameters and 8 for critical ones—and allows running a model with 284 billion total parameters on a Mac with 128 GB of RAM, keeping the conversational context on the SSD instead of in unified memory. Antirez’s own verdict, as someone not prone to easy enthusiasm, was unequivocal: it’s the first time he’s found a local model he uses for serious things that he normally would have asked Claude or GPT. Today DS4 requires a Mac Studio or a Mac Pro with maximum configuration—hardware costing several thousand euros accessible to few. But when it’s Salvatore Sanfilippo charting a direction, it’s worth looking where it leads.
Big Pickle and the field test
Allow me to bring a modest recent and personal example, because sometimes theory is better understood when it has a strange name and a website to redo.
A few weeks ago, I found myself with some websites to update: dated appearance, oversized architecture for real needs, hosting on a platform designed for dynamic applications when they were actually static sites. Classic technical debt that accumulates silently until it becomes annoying enough that it can no longer be ignored.
I used OpenCode, an AI-assisted development environment that integrates various models and allows working directly on code with a command-line interface. I wrote an accurate but concise prompt, inserted the link to the old site as a visual and stylistic reference, and in a few minutes, I had the first working version of the new site: modern structure, clean code, drastically faster loading. A few iterations to fix details, and the job was done. Then I repeated the process for the other sites. Not even a full day’s work for tasks I could have procrastinated for months.
The interesting detail is not the tool itself but the model I used. Among the free options available, there was one with a name that would have made any marketing manager of a serious tech company laugh: “Big Pickle.” No presentation, no press release, no publicized benchmark. Who knows what model is hidden behind that pseudonym—probably something more well-known under a different name for licensing or experimentation reasons. Alongside it, also free, were DeepSeek V4 Flash, Xiaomi’s MiMo V2.5, and NVIDIA’s Nemotron 3 Super.
I chose Big Pickle, essentially out of curiosity. The result was perfect for the purpose. No quota limit reached, no cost, no waiting for an overloaded model. And above all: no need to use a frontier model for that type of task. Could I have opened Claude with Opus 4.8 and spent precious credits to get the exact same result? Yes. Did it make sense to do so? In my opinion, no.
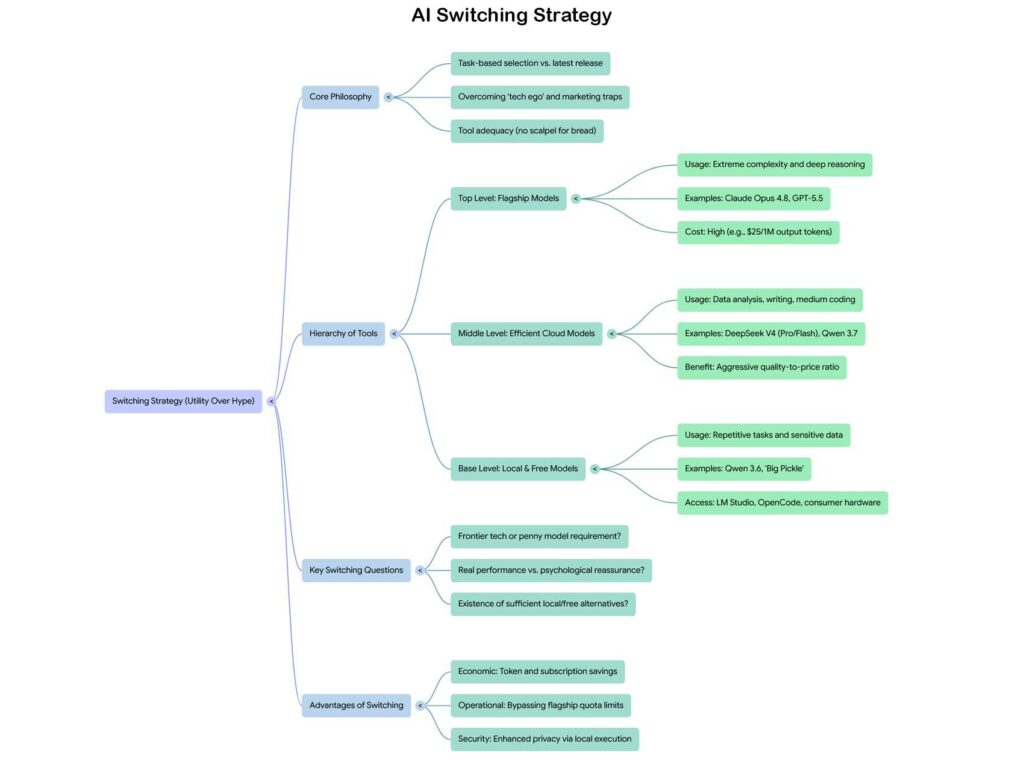
This is the central point of the switching strategy I want to introduce. It’s not about demonizing flagship models or claiming they are useless, because they are not. It’s about developing the critical awareness to understand when they are necessary and when they are an unrequested luxury for the task at hand.
AI Switching Strategy Map
The tool map
Thinking of AI as a single monolithic tool to be updated periodically is the conceptual error that big tech marketing wants us to make. It’s like thinking of your set of kitchen utensils as a single entity to be replaced every time the latest model of chef’s knife comes out, ignoring that a peeler is enough to peel a potato and that using a 300-euro Shun knife for that purpose doesn’t produce better potatoes.
The switching strategy starts from a simple question: what am I trying to do, and what level of capability is really necessary to do it well?
For tasks of extreme complexity—writing critical systems, reasoning about multi-step problems with many interdependent variables, analyzing long and dense documents that require deep context understanding—flagship models still have a real and measurable advantage. If you’re writing the kernel of an operating system or building an autonomous agent for enterprise production pipelines, that advantage is worth the cost.
For everything else, which covers the vast majority of daily use, the alternative landscape is rich and often free or nearly so. DeepSeek V4 Flash handles data analysis, scraping, dataset reconstruction, and structured text generation excellently at a fraction of the cost. The models from Alibaba’s Qwen family, having reached versions 3.6 and 3.7, compete with the best Western models on many benchmarks while being available for free via API or runnable locally on consumer hardware.
And this is where the conversation gets really interesting, because local is no longer an option for nerds with server racks in the basement. As I explored with Qwen 3.6 with 35 billion parameters, a PC with 32 GB of RAM and a GPU with 16 GB of VRAM—a configuration no longer extraordinary in 2026—manages to run models of that size with surprising performance on real tasks. LM Studio has made the installation and management of local models accessible to anyone who knows how to use a graphic interface, without losing an afternoon in terminal configurations. The advantage of local is not just economic: it’s complete data privacy, the absence of quota limits, and offline availability.
The practical hierarchy that emerges from this analysis is stratified. At the top, for tasks that truly require it, paid flagship models. In the middle, for most daily work, models like DeepSeek V4 Pro or Flash, accessible via API at low costs or through interfaces like OpenCode that aggregate multiple providers. At the base, for repetitive, fast tasks, or those involving sensitive data, local models on mid-range hardware. And transversally, for those who want to explore without spending, a series of free options that a year ago would have been considered of excellent quality and which today, for many scenarios, are simply more than enough.
It’s worth doing this mental exercise at least once a year, even if it’s just with pen and paper. Take a task you perform frequently say, summarizing long documents or generating structured text drafts and ask yourself how much it costs you to do it with the model you usually use. Then look at the cost of the same task on an alternative model capable of handling it equally well. The difference, multiplied by your monthly volume, is your opportunity cost: what you’re paying not for better performance, but simply for not having done the comparison.
Specific numbers change constantly, providers adjust prices, new models come out, promotions expire, and any comparison table published today is already partially obsolete tomorrow. But the logic behind the calculation remains valid regardless of who wins the race at a given time: the right model isn’t the most powerful one available, it’s the one whose cost truly reflects the value it produces for you, on that task, with that volume.
Choosing, not chasing
There is a scene in the video game Disco Elysium in which the protagonist, a detective with destroyed memory, must reconstruct his own identity piece by piece by consciously choosing which skills to develop, which values to embrace, what kind of person to become again. The game puts dozens of options in front of you—all plausible, all with their own advantages—and asks you to resist the temptation to want them all. The ability to choose with criteria, not to accumulate, is what builds a coherent and capable character.
The parallel with the choice of AI tools is less forced than it seems. The market today offers us dozens of models, all presented as indispensable, all with something to offer. The instinctive response, fueled by years of tech marketing, is to chase the best available at all times. The intelligent response is to build one’s own conscious hierarchy, based on the real tasks faced every day.
This doesn’t mean ignoring progress. Opus 4.8 is a better model than Opus 4.7, and it will be even more so for those working on advanced agentic coding or on enterprise pipelines where the reduction of hallucinations is alone worth the migration cost. Improvements are there, even when they are incremental. The question is not whether the models improve, but whether that improvement is worth it for your specific use case, now, with the budget you have.
The questions worth asking before every upgrade are few and direct. Does the task I have to perform truly require reasoning capabilities at the limits of the technological frontier, or is it something that a model costing a cent per million tokens solves just as well? Am I paying for objectively better performance on my real workflow, or am I paying for the psychological reassurance of having the latest model? Is there a local or free version that handles this task sufficiently for my expectation?
Big tech companies have every interest in making us always answer “yes, I need the latest model released.” It is the mechanism that fuels subscriptions, renewals, and dependency on the provider. It is not necessarily bad faith; it is simply the logic of a market that has learned to monetize technological performance anxiety in the same way that smartphone manufacturers have monetized that of status symbols. The cycle self-sustains because it works, at least for those who sell it.
The alternative is not Luddism or nostalgia for models from two years ago. It is the lucidity of those who understand that the value of a tool is not measured in its position in the rankings, but in its adequacy for the task. A Titanium scalpel doesn’t cut bread better than an ordinary kitchen knife. A model costing 25 dollars per million output tokens doesn’t produce better emails than one that costs two.
The real competence this historical moment requires is not knowing how to use the most powerful model available. It is knowing how to choose, every time, the right one.
All prices and benchmarks cited refer to information available at the time of publication, May 2026. The landscape of AI models evolves rapidly: always check the primary sources of individual providers for updated data.



