La visión artificial ha avanzado de manera exponencial con el advenimiento de los Vision Transformers (ViT) y el Segment Anything Model (SAM) de Meta. Estos modelos no solo están redefiniendo cómo entendemos la segmentación y la clasificación de imágenes, sino que también están marcando un cambio crucial respecto a las tradicionales redes convolucionales (CNN). En este artículo, exploramos cómo ViT y SAM, junto con el modelo DETR para detección de objetos, están revolucionando el panorama de la visión por computadora.
Durante casi una década, las Redes Neuronales Convolucionales (CNNs) fueron las reinas indiscutibles del Deep Learning en visión por computador. Desde el reconocimiento de imágenes en ImageNet hasta la detección de objetos y la segmentación semántica, las CNNs demostraron una capacidad sin precedentes para aprender jerarquías de características visuales. Su estructura, inspirada en el córtex visual de los mamíferos, utilizaba filtros convolucionales para extraer patrones locales, construyendo una representación robusta del mundo visual.

Sin embargo, a pesar de sus éxitos, las CNNs tenían una limitación inherente: su enfoque local y secuencial. Los filtros solo “veían” una pequeña porción de la imagen a la vez. Para capturar el contexto global, se requería una arquitectura muy profunda, lo que a menudo resultaba en una mayor complejidad computacional y la pérdida de información de gran escala.
El Giro del Transformer
En 2017, la publicación del paper “Attention Is All You Need” por un equipo de Google Brain cambió para siempre el panorama del Deep Learning. Introdujeron el concepto de Transformers, una arquitectura revolucionaria basada en el mecanismo de auto-atención. Originalmente diseñados para el procesamiento del lenguaje natural (NLP), los Transformers demostraron una capacidad asombrosa para modelar dependencias a largo plazo entre las palabras de una frase.
La idea era simple pero poderosa: en lugar de procesar la información de forma secuencial, un Transformer podía “atender” a todas las partes de la entrada simultáneamente, asignando un peso de importancia a cada una de ellas. Esto les permitía entender el contexto global de una frase de manera mucho más eficiente que los modelos recurrentes (RNNs) o convolucionales.
¿Por qué ir más allá de los CNN?
Las CNN capturan patrones locales con kernels, pero tienen limitaciones:
- Alcance de contexto fijo y creciente complejidad con capas profundas.
- Dificultad para modelar relaciones globales en la imagen sin aumentar parámetros.
- Rigidez en escalabilidad a diferentes resoluciones y dominios.
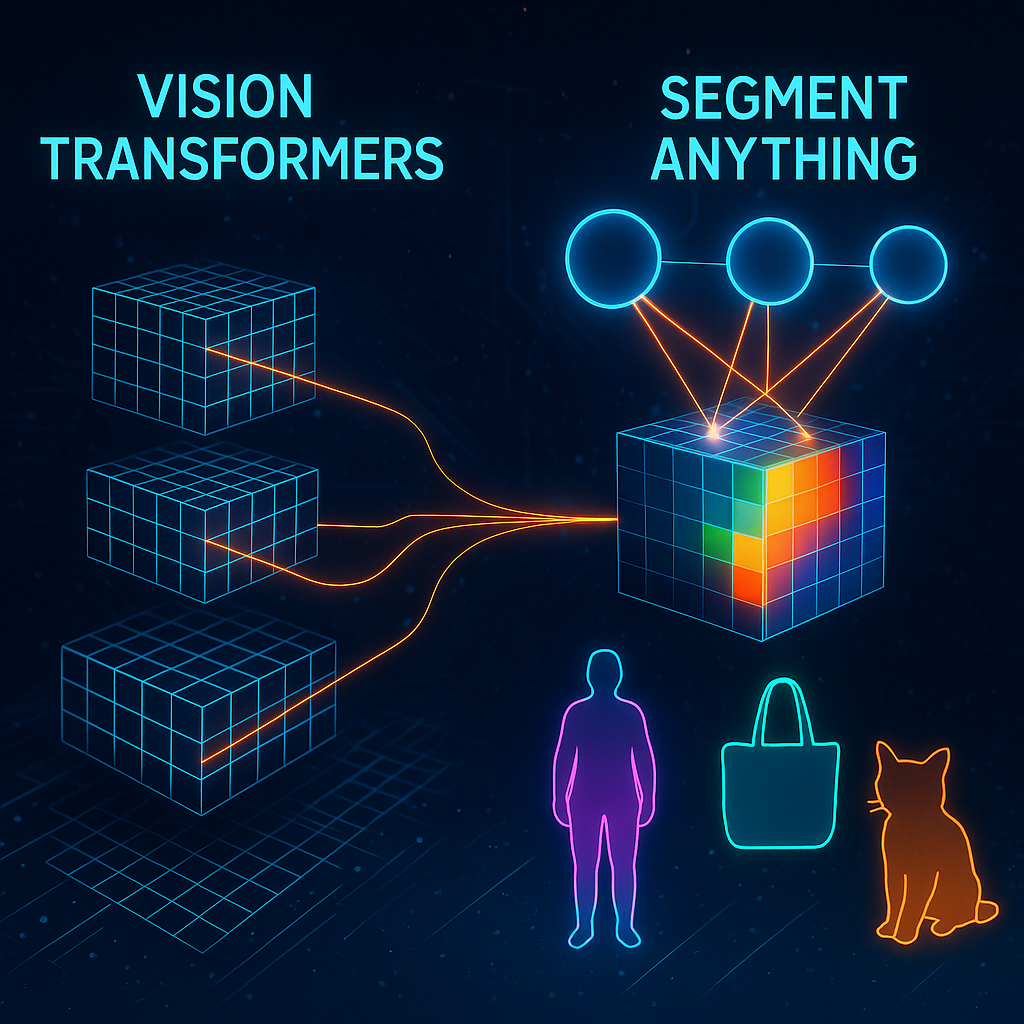
El Gran Salto: Vision Transformers (ViT)
La pregunta era inevitable: ¿podría esta arquitectura, tan exitosa en el lenguaje, ser aplicada a las imágenes? En 2020, un grupo de investigadores de Google lo hizo posible con su paper “An Image is Worth 16×16 Words: Transformers for Image Recognition at Scale”. Así nacieron los Vision Transformers (ViT).
La clave del éxito de ViT fue tratar una imagen como una secuencia de “parches” o “tokens”. Al igual que una frase se divide en palabras, una imagen se divide en pequeñas sub-imágenes (por ejemplo, de 16×16 píxeles). Cada uno de estos parches se aplanaba y se proyectaba a un espacio de incrustaciones de alta dimensión, similar a las incrustaciones de palabras en NLP. A partir de ahí, se aplicaba el mecanismo de auto-atención del Transformer, permitiendo que cada parche “viera” y entendiera el contexto de todos los demás parches en la imagen.
¿Por qué ViT fue tan disruptivo?
- Contexto Global: A diferencia de las CNNs, ViT podía modelar relaciones de largo alcance desde las primeras capas, sin necesidad de una arquitectura profunda. Esto le permitía comprender la escena completa y las relaciones entre los objetos de manera más holística. Atención global desde la primera capa.
- Escalabilidad: ViT demostró que, con suficientes datos de entrenamiento y una escala adecuada, podía superar a los modelos basados en CNNs en tareas de clasificación de imágenes. Escalabilidad sencilla, más capas y cabezas mejoran el desempeño.
- Transferencia de Aprendizaje: Al pre-entrenarse en vastos conjuntos de datos como JFT-300M (con más de 300 millones de imágenes), ViT podía aprender representaciones visuales extremadamente ricas y generalizables, que luego podían ser transferidas a tareas específicas con un fine-tuning mínimo. Flexibilidad para tareas variadas sin modificaciones drásticas al backbone.
Ejemplo: Fine-tuning de ViT con PyTorch
import torch
from torchvision import transforms, datasets
from timm import create_model
from torch import nn, optim
import os
# Configuración
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = create_model('vit_base_patch16_224', pretrained=True, num_classes=10).to(device)
# Data loaders
transform = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(),
])
train_ds = datasets.CIFAR10('data', train=True, download=True, transform=transform)
train_loader = torch.utils.data.DataLoader(train_ds, batch_size=32, shuffle=True)
# Optimización y pérdida
optimizer = optim.AdamW(model.parameters(), lr=1e-4)
criterion = nn.CrossEntropyLoss()
# Entrenamiento
epochs = 5 # Puedes aumentar si quieres
model.train()
for epoch in range(epochs):
running_loss = 0.0
for batch_idx, (images, labels) in enumerate(train_loader):
images, labels = images.to(device), labels.to(device)
optimizer.zero_grad()
outputs = model(images)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
if (batch_idx + 1) % 100 == 0:
print(f"[Época {epoch+1}/{epochs}] Batch {batch_idx+1} - Loss: {loss.item():.4f}")
print(f"===> Fin de época {epoch+1}, Loss promedio: {running_loss / len(train_loader):.4f}")
# Guardar el modelo entrenado
os.makedirs("checkpoints", exist_ok=True)
torch.save(model.state_dict(), "checkpoints/vit_cifar10.pth")
print("✅ Modelo guardado en 'checkpoints/vit_cifar10.pth'")Lenguaje del código: PHP (php)¿Qué hace este código? Entrena un modelo ViT (Vision Transformer) para reconocer imágenes de la base de datos CIFAR-10, que contiene fotos pequeñas (32×32) de: aviones, autos, pájaros, gatos, ciervos, perros, ranas, caballos, barcos y camiones. Y al final, guarda el modelo entrenado.
Segment Anything Model (SAM) de Meta
Mientras ViT transformaba la clasificación de imágenes, otro gigante de la industria, Meta AI, estaba trabajando en una revolución similar para la segmentación de imágenes. El resultado fue el Segment Anything Model (SAM), una demostración asombrosa del poder de los prompts y el aprendizaje a gran escala.
Tradicionalmente, la segmentación requería entrenar modelos para reconocer y delinear clases de objetos específicas (perros, gatos, árboles, etc.). SAM rompió este paradigma. En lugar de predecir clases, SAM fue diseñado para segmentar cualquier objeto en una imagen, basándose en prompts interactivos. Estos prompts podían ser puntos, recuadros, o incluso descripciones de texto.
¿Cómo funciona SAM?
Se entrena con un conjunto de datos masivo de más de mil millones de máscaras de segmentación, generadas automáticamente a partir de 11 millones de imágenes. La arquitectura de SAM consiste en tres componentes principales:
- Image Encoder (Codificador de Imagen): Un Vision Transformer (ViT) pre-entrenado que extrae las características visuales de la imagen.
- Prompt Encoder (Codificador de Prompt): Un módulo que procesa los prompts de entrada, ya sean puntos, cajas o texto.
- Mask Decoder (Decodificador de Máscara): Un módulo que, basándose en las características de la imagen y las incrustaciones del prompt, genera dinámicamente la máscara de segmentación del objeto deseado.
Casos de uso de SAM
- Segmentación interactiva en edición de imágenes.
- Análisis rápido en medicina, industria y robótica.
- Preprocesamiento para entrenar modelos especializados.
El impacto de SAM es inmenso. Al separar la tarea de segmentación de la necesidad de reconocer clases predefinidas, SAM democratiza la segmentación. Ahora, un solo modelo puede ser utilizado para una infinidad de tareas, desde el análisis médico hasta la creación de contenido digital, simplemente proporcionando un prompt interactivo.

Ejemplo: Segmentación con SAM en Python
!pip install git+https://github.com/facebookresearch/segment-anything.git
!pip install opencv-python matplotlib
!git clone https://github.com/facebookresearch/segment-anything.git
%cd segment-anything
!wget https://dl.fbaipublicfiles.com/segment_anything/sam_vit_h_4b8939.pth -O sam_vit_h.pthLenguaje del código: PHP (php)Instalación de dependencias: primer paso a seguir.
from google.colab import files
uploaded = files.upload()
from segment_anything import sam_model_registry, SamPredictor
import cv2
import numpy as np
import matplotlib.pyplot as plt
# Cargar modelo SAM
sam = sam_model_registry["vit_h"](checkpoint="sam_vit_h.pth")
predictor = SamPredictor(sam)
# Cargar la imagen
image = cv2.imread("nombre_de_tu_imagen.jpg")
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB) # Convertir a RGB
predictor.set_image(image)
# Definir punto para segmentar (x, y)
input_point = np.array([[100, 150]])
input_label = np.array([1]) # 1 para objeto, 0 para fondo
# Hacer predicción
masks, scores, logits = predictor.predict(
point_coords=input_point,
point_labels=input_label,
multimask_output=True,
)
# Mostrar máscaras
for i, mask in enumerate(masks):
plt.figure()
plt.title(f"Máscara {i+1} - Score: {scores[i]:.2f}")
plt.imshow(image)
plt.imshow(mask, alpha=0.5)
plt.axis('off')
plt.show()Lenguaje del código: PHP (php)¿Qué está haciendo?: Define un punto de entrada ([100,150]) en la imagen, luego el modelo genera una o más máscaras que representan lo que cree que hay en ese punto y visualizas esas máscaras encima de la imagen.
DETR: Detección de Objetos con Transformers
La influencia de los Transformers no se detuvo en la clasificación y la segmentación. El paper “End-to-End Object Detection with Transformers” (DETR) de Facebook AI Research (ahora Meta AI) reimaginó por completo la detección de objetos.
Los modelos tradicionales de detección de objetos, como Faster R-CNN o YOLO, se basan en una serie de heurísticas y componentes especializados, como anclajes de cajas (anchor boxes) y supresión no máxima (NMS). DETR eliminó todos estos componentes.
DETR (DEtection TRansformer) redefine la detección de objetos combinando un backbone CNN con un Transformer estándar y un set de queries fijas que predicen cajas y clases.
¿La innovación de DETR?
DETR formuló la detección de objetos como un problema de predicción directa de un conjunto de objetos. El modelo utiliza un Transformer para predecir, de una sola vez, un conjunto fijo de predicciones, cada una de las cuales contiene las coordenadas del recuadro del objeto y su clase. Para evitar predicciones duplicadas, utiliza un matching bipartito que asigna las predicciones del modelo a las etiquetas de verdad fundamental de la forma más óptima posible.
DETR simplificó drásticamente el pipeline de detección de objetos, haciéndolo más elegante y, lo que es más importante, eliminando la necesidad de componentes manuales que a menudo introducían hiperparámetros difíciles de ajustar.
Arquitectura y funcionamiento
- Backbone CNN extrae características espaciales.
- Transformer codifica relaciones globales entre parches.
- Queries aprenden a predecir objetos sin necesidad de anclas o NMS manual.
Ejemplo: Detección con DETR en PyTorch
import torch
import matplotlib.pyplot as plt
from PIL import Image
import torchvision.transforms as T
import requests
# Define device
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 1. Cargar imagen
image = Image.open("/content/auto.jpg")
# 2. Preparar transformaciones
transform = T.Compose([
T.Resize(800),
T.ToTensor(),
T.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
])
img_tensor = transform(image).unsqueeze(0).to(device)
# 3. Pasar por el modelo
# Ensure the model is on the correct device
model.to(device)
outputs = model(img_tensor)
# 4. Aplicar softmax a logits
probas = outputs['pred_logits'].softmax(-1)[0, :, :-1] # quitar clase "no object"
boxes = outputs['pred_boxes'][0]
# 5. Filtrar predicciones con probabilidad > 0.9
keep = probas.max(-1).values > 0.9
filtered_boxes = boxes[keep]
filtered_scores = probas[keep]
filtered_labels = filtered_scores.argmax(-1)
# 6. Dibujar sobre la imagen original
def rescale_bboxes(bboxes, size):
img_w, img_h = size
b = bboxes.clone().cpu() # <- aquí se asegura que todo esté en CPU
scale = torch.tensor([img_w, img_h, img_w, img_h], dtype=torch.float32)
b = b * scale
b[:, :2] -= b[:, 2:] / 2
b[:, 2:] += b[:, :2]
return b
labels = filtered_labels.cpu().numpy()
scores = filtered_scores.max(-1).values.detach().cpu().numpy()
bboxes = rescale_bboxes(filtered_boxes.detach().cpu(), image.size).numpy()
# 7. Mostrar
plt.figure(figsize=(10, 10))
plt.imshow(image)
ax = plt.gca()
CLASSES = [
'N/A', 'person', 'bicycle', 'car', 'motorcycle', 'airplane', 'bus',
'train', 'truck', 'boat', 'traffic light', 'fire hydrant', 'N/A', 'stop sign',
'parking meter', 'bench', 'bird', 'cat', 'dog', 'horse', 'sheep', 'cow', 'elephant',
'bear', 'zebra', 'giraffe', 'N/A', 'backpack', 'umbrella', 'N/A', 'N/A', 'handbag',
'tie', 'suitcase', 'frisbee', 'skis', 'snowboard', 'sports ball', 'kite',
'baseball bat', 'baseball glove', 'skateboard', 'surfboard', 'tennis racket',
'bottle', 'N/A', 'wine glass', 'cup', 'fork', 'knife', 'spoon', 'bowl',
'banana', 'apple', 'sandwich', 'orange', 'broccoli', 'carrot', 'hot dog', 'pizza',
'donut', 'cake', 'chair', 'couch', 'potted plant', 'bed', 'N/A', 'dining table',
'N/A', 'N/A', 'toilet', 'N/A', 'tv', 'laptop', 'mouse', 'remote', 'keyboard',
'cell phone', 'microwave', 'oven', 'toaster', 'sink', 'refrigerator', 'N/A',
'book', 'clock', 'vase', 'scissors', 'teddy bear', 'hair drier', 'toothbrush'
]
for (xmin, ymin, xmax, ymax), label, score in zip(bboxes, labels, scores):
ax.add_patch(plt.Rectangle((xmin, ymin), xmax - xmin, ymax - ymin,
fill=False, color='red', linewidth=2))
ax.text(xmin, ymin, f'{CLASSES[label]}: {score:0.2f}',
fontsize=12, color='white', bbox=dict(facecolor='red', alpha=0.5))
plt.axis('off')
plt.show()Lenguaje del código: PHP (php)El modelo DETR preentrenado: Usa torch.hub para cargar un modelo DETR ya entrenado en COCO. Lee una imagen (example.jpg u otra) desde internet o desde el disco local. Redimensiona, normaliza y convierte la imagen en tensor para que el modelo pueda entenderla. El modelo devuelve una lista de objetos detectados con sus clases y cajas delimitadoras (bounding boxes). Dibuja las cajas con etiquetas sobre la imagen original para mostrar qué se ha detectado.
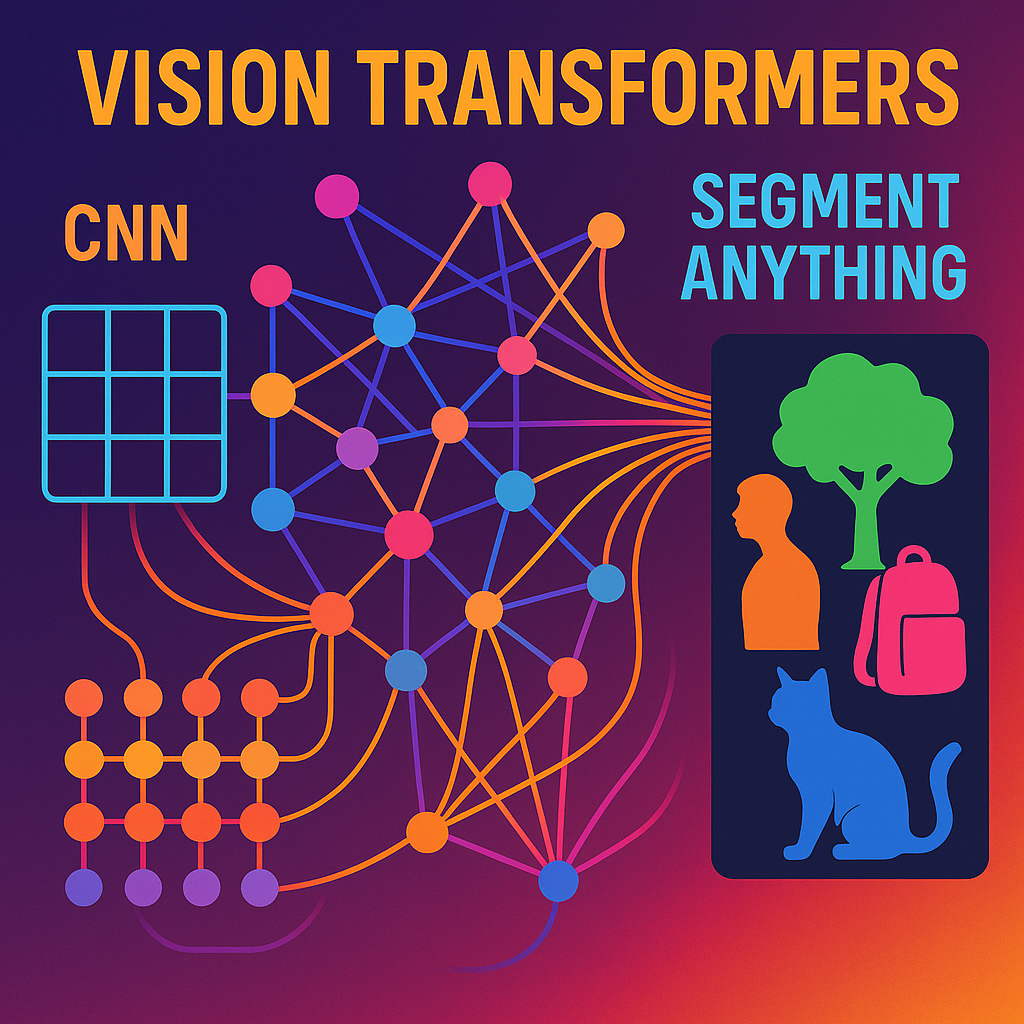
Comparativa: CNN vs. Transformers en visión

El Futuro: Más Allá de los CNNs
El auge de ViT, SAM y DETR no significa el fin de las CNNs, que siguen siendo extremadamente eficientes y potentes en muchas aplicaciones. Sin embargo, marca un cambio de paradigma. Los Transformers han demostrado ser excepcionalmente buenos en la comprensión del contexto global, la escalabilidad y la capacidad de generalización.
Hoy en día, las arquitecturas híbridas que combinan las fortalezas de las CNNs (eficiencia y capacidad de extraer características locales) y los Transformers (comprensión contextual) están ganando terreno. El futuro de la visión por computador se dirige hacia modelos más unificados, capaces de realizar múltiples tareas (clasificación, detección, segmentación) con una sola arquitectura.