La detección de tumores cerebrales es uno de los desafíos más complejos de la medicina moderna. Si bien la Resonancia Magnética (MRI) es la herramienta de diagnóstico estándar, el análisis manual requiere mucho tiempo. Como desarrolladores, nos preguntamos: ¿podemos automatizar esto con precisión y explicabilidad?
Introducción

En este proyecto, me alejé de las Redes Neuronales Convolucionales (CNN) estándar para explorar un enfoque más sofisticado: un Autoencoder Convolucional. En lugar de alimentar píxeles crudos directamente a un clasificador, entrené un autoencoder para aprender una representación estructural y comprimida del cerebro: el Espacio Latente. Este enfoque permite al modelo filtrar el ruido y centrarse en los patrones anatómicos antes de realizar un diagnóstico.
El sistema final alcanza una precisión del 96% y, lo que es crucial, implementa Grad-CAM para visualizar exactamente dónde se encuentra el tumor, añadiendo una capa de confianza para los entornos clínicos.
La Arquitectura: Aprendiendo la Anatomía
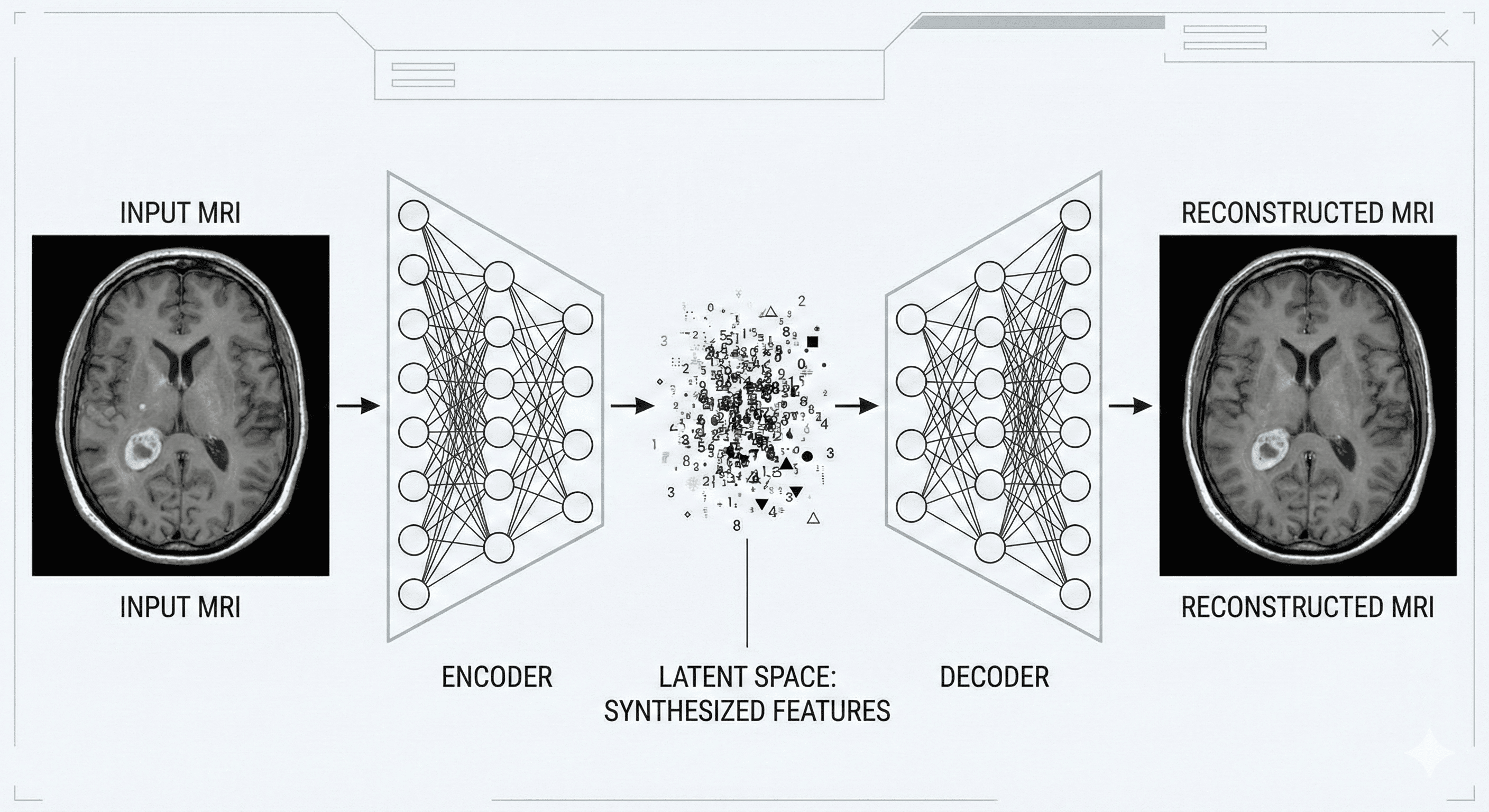
El núcleo de esta solución es el autoencoder. Esta red aprende a comprimir la imagen de entrada de 128 x 128 píxeles en un vector de características compacto y luego la reconstruye. Al forzar a la red a pasar información a través de un cuello de botella (bottleneck), nos aseguramos de que aprenda las características más destacadas de la estructura cerebral.
Aquí está la implementación de la arquitectura del autoencoder usando TensorFlow y Keras:
def build_autoencoder(input_shape):
input_layer = tf.keras.Input(shape=input_shape)
x = layers.Conv2D(32, (3, 3), activation='relu', padding='same')(input_layer)
x = layers.MaxPooling2D((2, 2), padding='same')(x)
x = layers.Conv2D(64, (3, 3), activation='relu', padding='same')(x)
x = layers.MaxPooling2D((2, 2), padding='same')(x)
x = layers.Conv2D(128, (3, 3), activation='relu', padding='same')(x)
latent_space = layers.MaxPooling2D((2, 2), padding='same', name="latent_space")(x)
x = layers.Conv2D(128, (3, 3), activation='relu', padding='same')(latent_space)
x = layers.UpSampling2D((2, 2))(x)
x = layers.Conv2D(64, (3, 3), activation='relu', padding='same')(x)
x = layers.UpSampling2D((2, 2))(x)
x = layers.Conv2D(32, (3, 3), activation='relu', padding='same')(x)
x = layers.UpSampling2D((2, 2))(x)
reconstructed_output = layers.Conv2D(1, (3, 3), activation='sigmoid', padding='same')(x)
autoencoder_model = models.Model(input_layer, reconstructed_output)
autoencoder_model.compile(optimizer='adam', loss='binary_crossentropy')
return autoencoder_modelLenguaje del código: Python (python)¿Realmente entiende los cerebros? (Reconstrucción)
Antes de construir el clasificador, debemos verificar que nuestro autoencoder esté aprendiendo características significativas y no simplemente memorizando ruido. Para hacer esto, observamos la pérdida de reconstrucción y comparamos las imágenes de entrada con las salidas generadas.
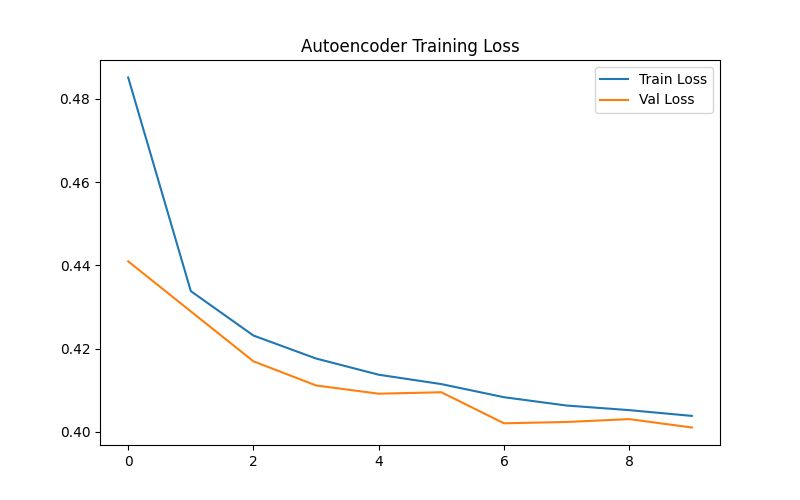
Pie de foto: La pérdida de entrenamiento muestra una convergencia constante, lo que indica que el modelo está aprendiendo efectivamente la estructura interna de las exploraciones de MRI.
La inspección visual confirma que el «Espacio Latente» contiene suficiente información para reconstruir la anatomía mientras filtra algo de ruido de alta frecuencia.
[Insert Brain reconstruction.jpg here]
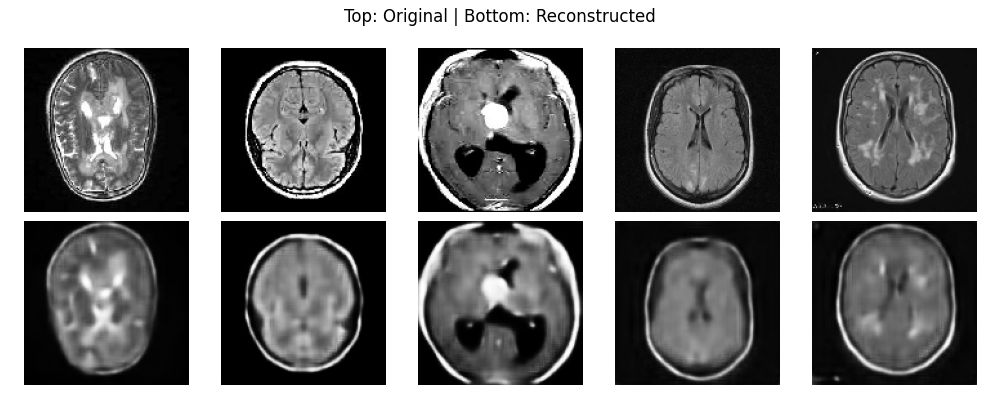
Pie de foto: Arriba: MRI original | Abajo: Imagen reconstruida. Observa cómo se preservan la estructura general y el área del tumor.
De la Compresión a la Clasificación
Una vez entrenado el autoencoder, la parte del «Decodificador» ya no es necesaria para el diagnóstico. Nos interesa el Codificador, que actúa como nuestro extractor de características. Congelamos los pesos del codificador y adjuntamos un cabezal de clasificación denso a su salida.
Este enfoque transforma el problema: en lugar de clasificar una imagen compleja de 128 x 128, la red densa clasifica las características comprimidas de alto nivel extraídas por el codificador.
[insertar aqui diagrama autoencoder con clasificador.png]
Aquí está el código para el clasificador que se asienta sobre el espacio latente:
def build_classifier(latent_shape):
classifier_model = models.Sequential([
layers.Flatten(input_shape=latent_shape[1:]),
layers.Dense(256, activation='relu'),
layers.Dropout(0.3),
layers.BatchNormalization(),
layers.Dense(64, activation='relu'),
layers.Dense(1, activation='sigmoid')
])
classifier_model.compile(
optimizer='adam',
loss='binary_crossentropy',
metrics=['accuracy']
)
return classifier_modelLenguaje del código: Python (python)El proceso de entrenamiento para este clasificador es rápido y estable porque el trabajo pesado (extracción de características) ya fue realizado por el autoencoder.
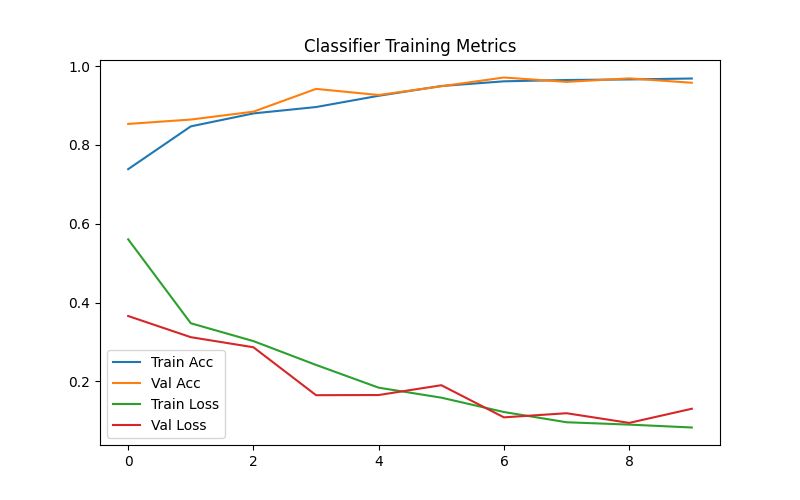
Los Resultados
El rendimiento en la tarea de detección de tumores cerebrales fue robusto. El modelo logró una precisión general del 96%, con un rendimiento muy equilibrado entre la identificación de casos positivos (Tumor) y casos negativos (Sin Tumor).
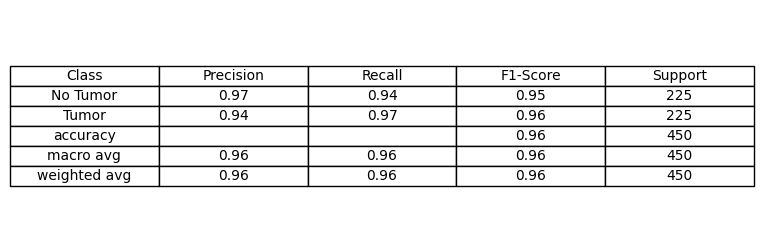
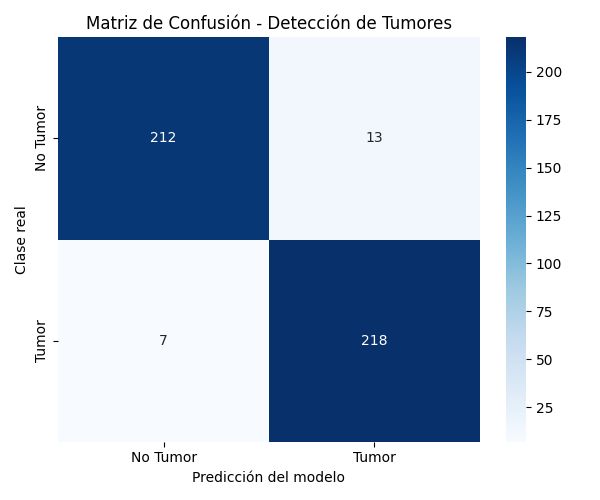
Como se muestra en la matriz de confusión, los falsos positivos y falsos negativos son mínimos (13 y 7 respectivamente de 450 imágenes de prueba). En un contexto médico, minimizar los falsos negativos es crítico, y nuestro recall (sensibilidad) para la clase «Tumor» es excelente, situándose en 0.97.
Abriendo la «Caja Negra» con Grad-CAM
Los números de precisión son buenos, pero en sanidad, la confianza es mejor. «¿Por qué dijo el modelo que este paciente tiene un tumor?»
Para responder a esto, implementé Grad-CAM (Gradient-weighted Class Activation Mapping). Esta técnica nos permite visualizar qué partes de la imagen original llevaron al modelo a tomar su decisión. Calculamos los gradientes de la puntuación de clasificación con respecto a los mapas de características convolucionales finales en el codificador.
Aquí está la implementación de la lógica Grad-CAM:
def generate_grad_cam_heatmap(encoder_model, classifier_model, image_array, layer_name):
img_tensor = tf.expand_dims(image_array, axis=0)
grad_model = tf.keras.models.Model(
inputs=encoder_model.input,
outputs=[encoder_model.get_layer(layer_name).output, encoder_model.output]
)
with tf.GradientTape() as tape:
conv_outputs, latent_features = grad_model(img_tensor)
prediction = classifier_model(latent_features)
loss = prediction[:, 0]
grads = tape.gradient(loss, conv_outputs)
pooled_grads = tf.reduce_mean(grads, axis=(0, 1, 2))
conv_outputs = conv_outputs[0]
heatmap = tf.reduce_mean(tf.multiply(pooled_grads, conv_outputs), axis=-1)
heatmap = np.maximum(heatmap, 0)
max_heat = np.max(heatmap)
if max_heat == 0:
max_heat = 1e-8
heatmap /= max_heat
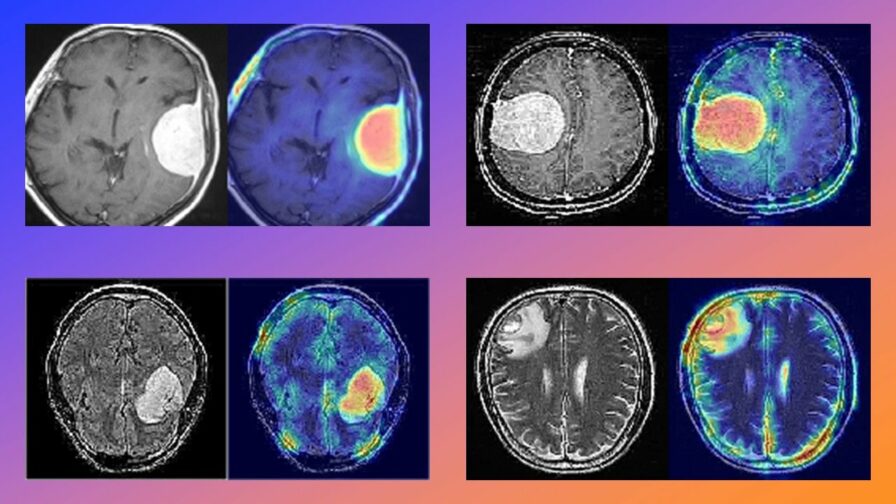
return heatmapLenguaje del código: Python (python)Los resultados son sorprendentes. Los mapas de calor muestran claramente que el modelo se centra específicamente en la región del tumor para hacer su predicción, en lugar de basarse en artefactos de fondo o contornos del cráneo.
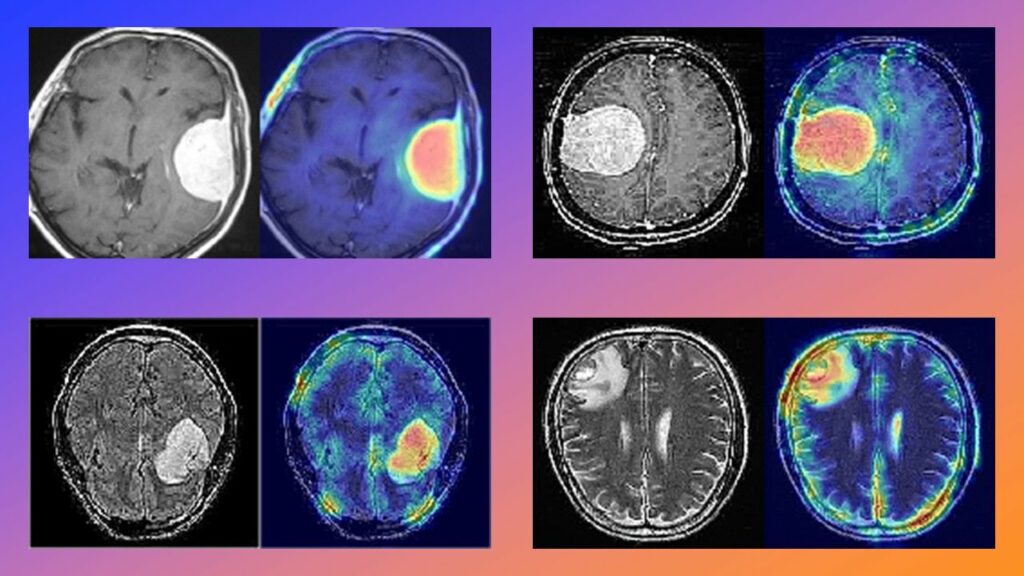
Pie de foto: Visualizaciones Grad-CAM. Las áreas «calientes» (rojo/amarillo) corresponden exactamente a la ubicación del tumor, validando la relevancia clínica del modelo.
Conclusión
Este proyecto demuestra que la detección automatizada de tumores cerebrales puede ser tanto precisa como transparente.
En el campo médico, un algoritmo de «caja negra» a menudo es inútil independientemente de su precisión. Herramientas como Grad-CAM tienden un puente entre las métricas de Deep Learning y la confianza clínica, demostrando que el modelo está observando la patología correcta.



