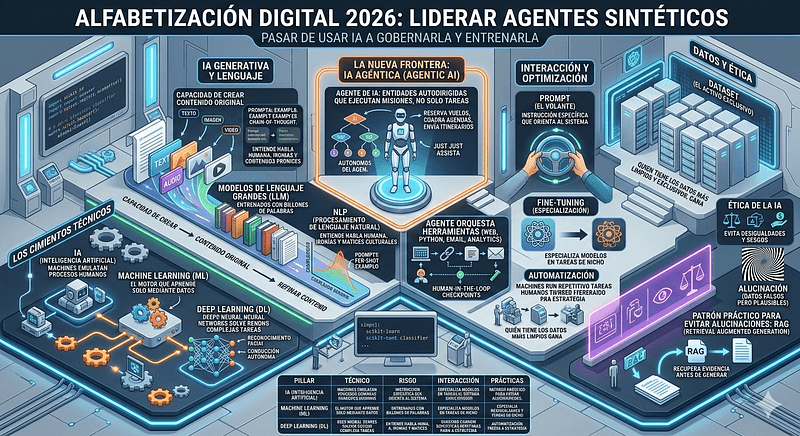
En 2026, la alfabetización digital y liderar Agentes Sintéticos es la nueva frontera competitiva. Ya no basta con saber que la IA existe: los equipos deben aprender a gobernarla, entrenarla y coordinar agentes autónomos capaces de ejecutar misiones completas.
Del Excel al liderazgo de agentes sintéticos
Hace años, “saber computación” era poner en tu CV que manejabas Excel. Hoy, esa habilidad es tan básica como respirar. En el presente, la verdadera frontera competitiva no es saber que la IA existe, sino aprender a liderar una orquesta de agentes sintéticos.

Si tu equipo aún ve la IA como un buscador glorificado, está operando con un mapa del 2010 en un mundo de conducción autónoma. La alfabetización digital ya no es un curso técnico: es el idioma de la estrategia, la lengua franca de la competitividad.
Los pilares de la alfabetización digital
Para los equipos de trabajo en 2026, la alfabetización digital ya no es territorio exclusivo de ingenieros, sino el lenguaje fundamental para la competitividad. Este artículo condensa los pilares, riesgos y prácticas que todo equipo debe dominar, para pasar de usar IA, a gobernarla y entrenarla. Los conceptos fundamentales se pueden agrupar en los siguientes pilares clave:
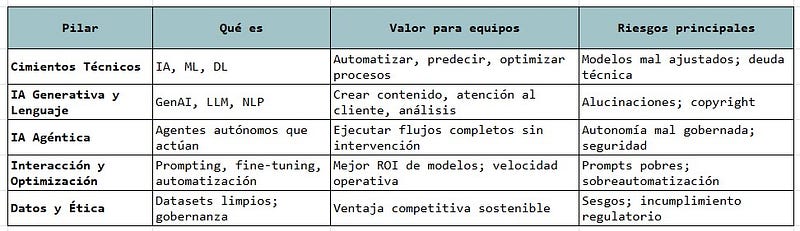
Los cimientos técnicos
- Inteligencia Artificial (IA): es la base tecnológica que permite a las máquinas emular procesos de pensamiento y acción humana de forma autónoma.
- Machine Learning (ML): rama de la IA dedicada al aprendizaje mediante datos para la mejora automática de procesos. El motor que aprende solo mediante datos.
- Deep Learning (DL): evolución del ML que utiliza redes neuronales profundas con múltiples capas para resolver tareas de alta complejidad, como el reconocimiento facial o la conducción autónoma. Redes neuronales complejas que resuelven lo “imposible”, como el reconocimiento visual avanzado.
Ejemplo: entrenamiento rápido con scikit-learn para clasificación (pipeline reproducible).
# Clasificador simple con scikit-learn
from sklearn.pipeline import make_pipeline
from sklearn.preprocessing import StandardScaler
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report
import pandas as pd
import numpy as np
# Generar datos de ejemplo si 'datos_ejemplo.csv' no existe
try:
df = pd.read_csv("datos_ejemplo.csv") # columnas: features..., label
except FileNotFoundError:
print("El archivo 'datos_ejemplo.csv' no fue encontrado. Generando datos de ejemplo...")
# Crear datos de ejemplo sintéticos
np.random.seed(42)
num_samples = 100
num_features = 5
data = np.random.rand(num_samples, num_features)
labels = np.random.randint(0, 2, num_samples) # 2 clases
df = pd.DataFrame(data, columns=[f'feature_{i}' for i in range(num_features)])
df['label'] = labels
df.to_csv('datos_ejemplo.csv', index=False)
print("Archivo 'datos_ejemplo.csv' generado con éxito.")
X = df.drop("label", axis=1)
y = df["label"]
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
pipeline = make_pipeline(StandardScaler(), RandomForestClassifier(n_estimators=100, random_state=42))
pipeline.fit(X_train, y_train)
y_pred = pipeline.predict(X_test)
print(classification_report(y_test, y_pred))Lenguaje del código: PHP (php)Explicación: separa datos, normaliza y entrena un bosque aleatorio; el pipeline facilita reproducibilidad y despliegue.
IA generativa y lenguaje
- IA Generativa (GenAI): tecnología con capacidad de crear contenido original (texto, imagen, audio, video) basándose en patrones aprendidos de datos existentes.
- Modelos de Lenguaje Grandes (LLM): modelos masivos como ChatGPT, Claude o Gemini entrenados con billones de palabras para comprender, generar y razonar en lenguaje natural.
- NLP (Procesamiento de Lenguaje Natural): facilita que la tecnología entienda e interprete la complejidad del habla humana, incluyendo ironías y matices culturales.
La IA Generativa y los LLMs (como Gemini o Claude) han democratizado la creación. El NLP (Procesamiento de Lenguaje Natural) ahora entiende el sarcasmo, la cultura y el contexto. Tu equipo ya no escribe desde cero; ahora edita, refina y razona sobre volúmenes masivos de información.
Ejemplo: prompt few‑shot y técnica chain‑of‑thought para mejorar razonamiento.
# Ejemplo conceptual de prompt few-shot
prompt = """
Eres un asistente que resume artículos en 3 frases.
Ejemplo 1:
Texto: "La compañía X lanzó..."
Resumen: "X lanzó..."
Ejemplo 2:
Texto: "Un estudio muestra..."
Resumen: "El estudio muestra..."
Ahora resume:
Texto: "La nueva regulación exige..."
"""
# Mock de la API del LLM para propósitos de demostración
class MockLLM:
def generate(self, prompt, max_tokens):
# En un LLM real, esto procesaría el prompt y devolvería una respuesta
# Aquí, simplemente retornamos una respuesta simulada basada en el ejemplo.
if "La nueva regulación exige..." in prompt:
return type('obj', (object,), {'text': 'La regulación exige nuevos procedimientos de seguridad.'})
return type('obj', (object,), {'text': 'Respuesta simulada del LLM.'})
llm = MockLLM()
# Llamada a la API del LLM (pseudocódigo)
response = llm.generate(prompt=prompt, max_tokens=120)
print(response.text)Explicación: dar ejemplos guía al modelo; pedir pasos intermedios (chain‑of‑thought) mejora respuestas complejas.
La nueva frontera: IA agéntica
Este es el concepto más disruptivo para 2026, marcando el paso de tener “asistentes que escriben” a “agentes que actúan”.
- Agente de IA: un programa autónomo diseñado para ejecutar tareas y tomar decisiones. A diferencia de un chatbot, un agente puede navegar webs, escribir código y enviar correos sin intervención humana constante.
- IA Agéntica (Agentic AI): entidades autodirigidas capaces de planificar, razonar y ejecutar misiones complejas de principio a fin de forma independiente.
Este es el salto cuántico de 2026. Pasamos de chatbots que responden a IA Agéntica. La diferencia es clave: Un asistente te dice cómo planear un viaje; un Agente de IA entra a la web, reserva los vuelos, cuadra la agenda y te envía el itinerario final. Son entidades autodirigidas que ejecutan misiones, no solo tareas.
Ejemplo: agente básico con LangChain que usa herramientas (web, python) para completar una tarea.
# Pseudocódigo con LangChain style
# from langchain import Agent, Tool, LLM # This import is causing the error
# Mock classes for demonstration purposes
class MockTool:
def __init__(self, name, func):
self.name = name
self.func = func
def run(self, *args, **kwargs):
# In a real tool, this would call an external API or perform an action
return self.func(*args, **kwargs)
class MockLLM:
def __init__(self, model):
self.model = model
def invoke(self, prompt):
# Simulate an LLM response based on the prompt
print(f"LLM (model: {self.model}) invoked with prompt: {prompt[:70]}...")
if "tasa de crecimiento del mercado X" in prompt:
return "La tasa de crecimiento del mercado X es del 5% anual, segón el informe de 2023. Se proyecta un crecimiento del 7% para 2025."
return "Respuesta simulada del LLM para la pregunta o tarea.\n"
class MockAgent:
def __init__(self, llm, tools):
self.llm = llm
self.tools = {tool.name: tool for tool in tools}
def run(self, mission):
print(f"Agente recibe misión: {mission}")
# Simplified agent logic for conceptual example
if "Investiga la tasa de crecimiento del mercado X" in mission:
print("Agente decide usar la herramienta de bósqueda para investigar la tasa de crecimiento.")
search_result = self.tools["search"].run("tasa de crecimiento mercado X")
print(f"Resultado de bósqueda: {search_result}")
# Simulate LLM processing search result and mission
llm_response = self.llm.invoke(f"Basado en: {search_result}\nResponde a la misión: {mission}")
if "generar un gráfico" in mission:
print("Agente decide usar la herramienta de Python para generar un gráfico.")
python_code_output = self.tools["python"].run("import matplotlib.pyplot as plt; plt.plot([1,2,3]); #... (graph generation logic)")
return f"{llm_response}\nGráfico generado: {python_code_output}"
return llm_response
return f"Agente conceptual: Misión '{mission}' completada con respuesta simulada.\n"
# Definir herramientas
def web_search(query):
# retorna texto de bósqueda simulado
return f"Resultado de bósqueda web para '{query}': Informe XYZ indica una tasa de crecimiento del 5% para el mercado X en 2023."
def run_python(code):
# ejecuta código seguro en sandbox y devuelve salida simulada
return f"Ejecución de código Python simulada: '{code[:30]}...' (gráfico creado)"
tools = [MockTool(name="search", func=web_search), MockTool(name="python", func=run_python)]
llm = MockLLM(model="gpt-like")
agent = MockAgent(llm=llm, tools=tools)
# Misión: "Investiga la tasa de crecimiento del mercado X y genera un gráfico"
result = agent.run("Investiga la tasa de crecimiento del mercado X y genera un gráfico")
print(result)Explicación: el agente orquesta herramientas; el equipo debe definir límites, permisos y checkpoints humanos para evitar acciones no deseadas.

Interacción y optimización
- Prompt: la instrucción o entrada específica que orienta al sistema hacia la generación de una respuesta deseada. Saber redactarlos es la habilidad más valiosa para dirigir la potencia de la IA.
- Fine-Tuning: proceso de entrenamiento especializado que permite a un modelo preexistente dominar una tarea de nicho específica (como especializar a un médico general en cardiología).
- Automatización: delegar en la IA tareas repetitivas para liberar tiempo humano para actividades creativas y estratégicas.
Si la IA es el motor, el Prompt es el volante. Pero en 2026, saber pedir no es suficiente. Los equipos líderes utilizan el Fine-Tuning para especializar modelos genéricos en expertos de nicho. Es la diferencia entre tener un médico general y un cardiólogo especializado en tu historial clínico exacto.
Ejemplo: fine‑tuning simplificado con Hugging Face para especializar un LLM en respuestas médicas (esquema).
!pip install -U transformers datasets accelerateimport torch
from datasets import load_dataset
from transformers import (
AutoTokenizer,
AutoModelForCausalLM,
Trainer,
TrainingArguments,
DataCollatorForLanguageModeling
)
# Verificar GPU
print("GPU disponible:", torch.cuda.is_available())
# ----------------------------
# 1. Cargar dataset
# ----------------------------
dataset = load_dataset("csv", data_files={
"train": "train.csv",
"validation": "val.csv"
})
# ----------------------------
# 2. Cargar modelo base
# ----------------------------
model_name = "gpt2"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name)
# GPT2 no tiene pad_token → lo igualamos al eos_token
if tokenizer.pad_token is None:
tokenizer.pad_token = tokenizer.eos_token
model.config.pad_token_id = tokenizer.eos_token_id
# ----------------------------
# 3. Tokenización
# ----------------------------
def tokenize(batch):
tokens = tokenizer(
batch["text"],
truncation=True,
padding="max_length",
max_length=512
)
tokens["labels"] = tokens["input_ids"].copy()
return tokens
dataset = dataset.map(
tokenize,
batched=True,
remove_columns=dataset["train"].column_names
)
# ----------------------------
# 4. Data collator
# ----------------------------
data_collator = DataCollatorForLanguageModeling(
tokenizer=tokenizer,
mlm=False
)
# ----------------------------
# 5. Argumentos de entrenamiento
# ----------------------------
training_args = TrainingArguments(
output_dir="./ft",
num_train_epochs=3,
per_device_train_batch_size=4,
per_device_eval_batch_size=4,
eval_strategy="epoch", # ← nuevo nombre
save_strategy="epoch",
logging_steps=50,
weight_decay=0.01,
fp16=True,
report_to="none"
)
# ----------------------------
# 6. Trainer
# ----------------------------
trainer = Trainer(
model=model,
args=training_args,
train_dataset=dataset["train"],
eval_dataset=dataset["validation"],
data_collator=data_collator
)
# ----------------------------
# 7. Entrenamiento
# ----------------------------
trainer.train()
# ----------------------------
# 8. Guardar modelo
# ----------------------------
trainer.save_model("./ft_model")
tokenizer.save_pretrained("./ft_model")
print("✅ Entrenamiento finalizado y modelo guardado.")
Lenguaje del código: PHP (php)from transformers import pipeline
generator = pipeline("text-generation", model="./ft_model", tokenizer="./ft_model")
print(generator("Érase una vez", max_length=50))Lenguaje del código: JavaScript (javascript)Explicación: prepara datos etiquetados, tokeniza y entrena poco a poco; siempre validar con datos reales y métricas relevantes.
Datos y ética
- Dataset: colección estructurada de datos indispensable para entrenar modelos. La ventaja competitiva real se desplazará hacia quien posea los datos más limpios y exclusivos.
- Ética de la IA: marco normativo que asegura que el desarrollo tecnológico sea justo, transparente y responsable, evitando que la IA amplifique desigualdades o sesgos.
- Alucinación: fenómeno donde la IA genera respuestas que parecen plausibles pero son factivamente incorrectas o sin sentido.
La ventaja competitiva ya no es el algoritmo (que es casi un commodity), sino el dataset. Quien tiene los datos más limpios y exclusivos, gana. Pero ojo: sin ética de la IA, corres el riesgo de escalar sesgos o caer en alucinaciones (datos que parecen reales pero son ficción).
Tabla resumen
Patrón práctico para evitar alucinaciones y errores factuales
- Retrieval Augmented Generation RAG: recuperar evidencia antes de generar.
- Verificación automática: pedir al modelo que cite fuentes y contrastarlas con un buscador.
- Human‑in‑the‑loop: checkpoints obligatorios para decisiones críticas.
Ejemplo RAG simplificado
# Flujo RAG conceptual
# 1. Indexar documentos con embeddings
# 2. Recuperar top_k documentos para la consulta
# 3. Construir prompt con evidencia y pedir respuesta verificada
# Mock de un vector store para propósitos de demostración
class MockVectorStore:
def search(self, query, top_k):
# En un sistema RAG real, esto buscaría en una base de datos vectorial
# Aquí, retornamos resultados simulados basados en la consulta.
if "tasa de crecimiento del mercado X en 2025" in query:
return [
type('obj', (object,), {'text': 'El informe de la industria de 2023 proyecta una tasa de crecimiento del 7% para el mercado X en 2025.', 'source': 'Informe XYZ'}),
type('obj', (object,), {'text': 'Un análisis reciente sugiere que el mercado X podría alcanzar un 8% de crecimiento anual para 2026.', 'source': 'Análisis ABC'})
]
return [type('obj', (object,), {'text': 'No se encontraron datos relevantes.', 'source': 'N/A'})]
# Mock de la API del LLM para propósitos de demostración (si aún no está definido)
class MockLLM:
def generate(self, prompt):
# Simula la respuesta de un LLM real
if "7%" in prompt and "mercado X" in prompt:
return type('obj', (object,), {'text': 'Según el Informe XYZ, la tasa de crecimiento proyectada para el mercado X en 2025 es del 7%.'})
return type('obj', (object,), {'text': 'Respuesta simulada del LLM basada en la evidencia.'})
vector_store = MockVectorStore()
llm = MockLLM()
query = "¿Cuál es la tasa de crecimiento del mercado X en 2025?"
docs = vector_store.search(query, top_k=5) # devuelve fragmentos con fuente
evidence = "\n".join([f"- {d.text} (fuente: {d.source})" for d in docs])
prompt = f"""
Evidencia:
{evidence}
Pregunta: {query}
Instrucción: Responde citando la evidencia exacta y marcando incertidumbres.
"""
answer = llm.generate(prompt=prompt)
print(answer.text)Explicación: la respuesta se ancla en evidencia recuperada; si el modelo inventa, el equipo detecta y corrige.
Para que un equipo sea digitalmente alfabetizado, no basta con saber que estas herramientas existen; deben entender la diferencia entre entrenar un modelo y simplemente usarlo, priorizando siempre la calidad del contexto y los datos que alimentan a sus sistemas.
En 2026, la alfabetización digital no se trata de saber programar. Se trata de entender la diferencia entre entrenar un modelo y simplemente consumirlo. Un equipo alfabetizado sabe que la calidad del output es un espejo directo de la calidad del contexto y los datos que suministramos.

