
There are names in the world of programming that carry a specific weight. Andrey Breslav is one of them. If millions of Android developers today write code in Kotlin instead of Java, it is largely thanks to him: Breslav was the lead designer of the language that JetBrains launched in 2011 and that Google officially adopted as the preferred language for Android in 2017, during the Google I/O that changed the mobile ecosystem forever. He is not an academic theorizing from a chair: he is one of those who have built tools used every day by hundreds of thousands of people in the real world, with all the compromises, production bugs, and pressures that this entails.
This premise is not a tribute for its own sake. It serves to understand why his new project, CodeSpeak, deserves attention far beyond the boundaries of the usual experimental language previews that proliferate on GitHub. When Breslav says he wants to rethink the way humans interact with code in the age of AI agents, he does so with the baggage of someone who has already traveled this road once and knows where the traps are hidden. As he told Gergely Orosz in the Pragmatic Engineer podcast, the deepest lesson of Kotlin is not about syntax or the type system, but about interoperability: a new language that cannot peacefully coexist with what already exists is destined to remain an experiment. It is a principle he has transferred directly into CodeSpeak.

The project is in Alpha Preview—a detail worth keeping in mind throughout the reading—and is built around an idea that, stated in one line, sounds almost provocative: what if we stopped maintaining code and started maintaining specifications?
Spec, Not Code: A Paradigm Shift
To understand what CodeSpeak proposes, we must first take a step back and look at the problem it seeks to solve. Anyone who has worked on a software project of medium complexity knows the feeling: code grows. It grows when features are added, it grows when bugs are fixed, it grows when new developers arrive and interpret specifications slightly differently than those who preceded them. With the arrival of AI agents that generate thousands of lines in seconds, this growth risks becoming uncontrollable. Not because the generated code is necessarily wrong, but because no one can keep it all in their head anymore.
The ground on which CodeSpeak takes root is not neutral. In February 2025, Andrej Karpathy, co-founder of OpenAI and former head of AI at Tesla, coined the term “vibe coding” to describe a practice already widespread: giving instructions in natural language to an AI agent and accepting the generated code without really reading it, trusting that it “works.” The original post on X garnered millions of views in days, and the label even made it into the Merriam-Webster dictionary by March of the same year, a speed that speaks volumes about how real the phenomenon already was. CodeSpeak is born precisely as a structured response to this trend: It doesn’t deny that LLMs can write useful code, but argues that letting agents generate freely without formal constraints produces codebases that no one truly understands anymore.
CodeSpeak proposes shifting the focus: instead of writing and maintaining implementation code, the team maintains specification files—compact, human-readable documents written in a structured Markdown with its own syntax. The system then takes care of translating those specifications into working code, using a language model (currently Anthropic’s Claude, which explains the requirement for an API key) as the generation engine.
The most useful analogy for those who don’t write code is with technical drawings in architecture. An architect doesn’t build the building brick by brick: they draw the floor plans, specify the materials, define the proportions and loads. The workers, or in this case, the LLM, take care of the concrete execution. When the architect wants to change the layout of a room, they don’t demolish and rebuild: they update the plans, and the construction site adjusts. CodeSpeak works exactly like this: you modify the specification, run codespeak build, and the code is updated accordingly.
This approach fits into a broader debate in the software development world that goes by various names: spec-driven development, intent-based programming, or more generally the idea that the next level of abstraction is not new programming languages in the traditional sense, but new ways of communicating intent to AI agents. The difference from simple “prompt engineering”—giving instructions to a chatbot—is that CodeSpeak introduces structure, versioning, and testability. Specifications live in a Git repository, are tracked like any other code artifact, and their effect is measured through existing test suites. It’s not vibe coding: it’s software engineering with a higher level of abstraction.
How It Works: From CLI to Takeover
Technically, CodeSpeak is installed with a single terminal command, uv tool install codespeak-cli, and requires an Anthropic API key that the user provides (the model is BYOK, Bring Your Own Key). From there, the workflow is structured into three main modes, designed for different scenarios.
The simplest mode is from scratch (greenfield): you initialize a CodeSpeak project, write specifications in Markdown files with a .cs.md extension, run codespeak build, and the system generates the corresponding Python code, runs tests, and reports if everything works. A specification for a CLI application to manage notes could occupy literally ten lines of readable text and produce a functioning application complete with commands, storage management, and terminal interface.
The most interesting mode, and the one with more practical implications for those working on existing projects, is mixed mode. CodeSpeak doesn’t ask you to throw away existing code: it can coexist with it. You initialize with codespeak init --mixed, and from that moment the project becomes hybrid: some parts remain hand-written by developers, others are managed by specifications. The LLM “sees” both parts during generation and can use the manual code as context to correctly implement the specifications. It is a pragmatic compromise that recalls, not coincidentally, Kotlin’s choice to guarantee complete interoperability with Java from day one.
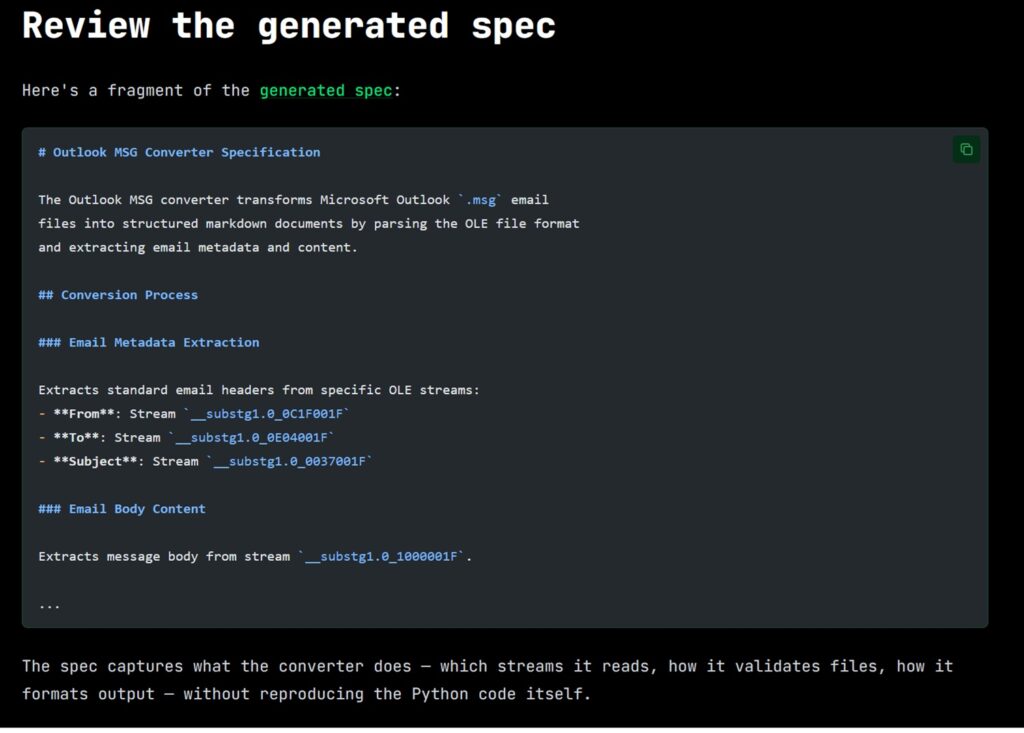
The third scenario, recently introduced with the codespeak takeover command, is perhaps the most suggestive: given an existing code file—even legacy, even written years ago by someone else—CodeSpeak reads the source and automatically extracts a compact specification. From that moment on, to modify that component, you no longer touch the Python code (or any other language): you modify the specification and relaunch the build. In the official blog post illustrating this feature, the team used Microsoft’s MarkItDown open-source project—a Markdown document converter—as a guinea pig, taking the file responsible for converting Outlook .msg files, extracting a specification of a few dozen lines, and then using that specification to fix a real bug reported on GitHub. All without touching a single line of Python. The modification to the specification—adding support for Cc, Bcc, Date fields, and missing attachments—was 23 lines; the resulting generated code was 221 lines. A ratio of about 10 to 1.
Modularity: When Specifications Become a System
A language that works only for small projects is a lab experiment. To become a professional tool, it must scale. And this is where the modularity features the team released on March 9, 2026, with version 0.3.4 come into play: spec dependencies and managed files.
The idea of spec dependencies is analogous to modules in traditional code: a specification can declare it depends on another through a simple directive in the Markdown file’s frontmatter. If the specification for an application’s command-line interface depends on the specification for the data storage layer, CodeSpeak first builds the storage layer, then the interface, ensuring the latter can correctly use what the former provides. And if you only modify the storage specification (changing, for example, the backend from JSON to SQLite with a single line of text), CodeSpeak rebuilds only that part, without touching the rest.
Managed files are instead a governance mechanism: each specification “knows” which code files are under its responsibility. When during a build CodeSpeak needs to modify a file that does not belong to the current specification—for example, the project’s dependency configuration file—it does so but explicitly warns the developer. The entire logic recalls the distinction between ownership and access in access control systems: each specification has its domain, and encroachments are reported, not silently tolerated. For teams working on large and complex codebases, it is a non-trivial guarantee against the unintended side effects of changes.
The Numbers: How Much Code is Really Reduced?
The case studies published on the official site are the most concrete and verifiable element of the entire proposal. The team took four real open-source projects—not toy examples built ad hoc—and generated corresponding specifications for significant portions of their code, measuring the reduction in terms of lines.
For yt-dlp, the famous video downloader, the WebVTT subtitle management component went from 255 lines of code to 38 lines of specification, with a reduction factor of 6.7 times. For Faker, the Python library for generating fake data, the Italian fiscal code generator dropped from 165 to 21 lines (7.9 times). For BeautifulSoup4, the HTML parsing library, the automatic encoding detection module is the most impressive case: 826 lines of code reduced to 141 lines of specification, a factor of 5.9. And for the already mentioned MarkItDown by Microsoft, the EML module went from 139 to 14 lines, with a factor of 9.9—almost 10 times.
The data that hits harder than the absolute numbers, however, is related to testing. In all four cases, the test suite not only continued to pass after code regeneration but saw the number of successfully passing tests increase: 37 tests added for yt-dlp, 13 for Faker, 25 for BeautifulSoup4, 27 for MarkItDown. Code reduction is not cosmetic—it’s not about compressing the source by removing comments and whitespace—but about eliminating conceptual redundancy by letting the LLM handle implementation details that are, as Breslav calls them, “obvious to machines.” What remains in the specification is only what is domain-specific: business rules, architectural choices, edge cases.
That said, it is honest to point out a methodological limitation: these tests were conducted by the CodeSpeak team themselves on selected portions of open-source projects. These are not independent benchmarks on arbitrary codebases. The question of how the system behaves on particularly intricate code, with circular dependencies or logic distributed across many files, remains for now without a documented answer.
More Human or Less Human?
There is a recurring temptation when talking about AI tools for software development to fall into one of two symmetrical traps: either triumphalism (“AI will do everything, programmers are obsolete”) or denialism (“it’s just a glorified autocomplete, nothing new under the sun”). CodeSpeak does not lend itself well to either narrative, and this is probably its most interesting trait.
To understand where it stands relative to existing tools, a direct comparison is worthwhile. GitHub Copilot and its analogs—Cursor, Junie by JetBrains, and the galaxy of assistants integrated into IDEs—operate on code as the primary artifact: they suggest lines, complete functions, sometimes generate entire blocks. They are extraordinarily useful tools, but their conceptual model doesn’t change: the developer writes code, AI helps write code faster. The most recent AI agents, like Claude Code or the “LLM + tools” pipelines that are proliferating, go a step further: they can navigate files, run commands, open pull requests. But even in this case, the artifact they produce and modify is code, and code generated by self-modifying autonomous agents is, as Breslav explicitly highlighted in the Pragmatic Engineer podcast, a source of increasing opacity. Who controls what when something stops working?
CodeSpeak answers this question with a radical choice: remove generated code from the center of human attention and put specifications in its place. The LLM is not an assistant that suggests; it’s a compiler that executes. The difference is not just semantic: it profoundly changes the contract between developer and machine. The developer does not review generated code line by line (an activity that, on outputs of hundreds of lines produced in seconds, is in practice often illusory); they review the specification, which is compact, readable, and versioned in Git like any other document. The generated code is, in this vision, an intermediate artifact, similar to Java bytecode or assembly produced by a C compiler: something that can in principle be inspected, but in daily practice is not the point where thought is concentrated.
This has concrete implications for team workflows. In a mature CodeSpeak project, product managers and tech leads reason in terms of executable specifications—documents describing what the system should do, not how it does it. Developers care for the quality of these specifications and associated tests more than the detail of every single function. Code reviews shift: instead of commenting on variable names and implementation choices, teams discuss whether the specification correctly captures the expected behavior. It is a non-trivial conceptual leap, similar—to use a comparison from the design world—to the transition from freehand drawing to parametric design systems: you no longer draw every element; you define the rules that generate it.
There is, however, an issue that enthusiastic supporters tend to gloss over: is the specification really more readable and understandable than code? For simple and well-defined functions, the answer is almost certainly yes. But for complex logic, with subtle dependencies between components and behaviors emerging from the interaction of many parts, the specification risks becoming a dense and difficult-to-maintain document itself. It shifts the problem rather than solving it, and the risk is that complexity, removed from the code, reinstalls itself in the specification in less structured and therefore harder-to-reason-about forms. It is the same criticism directed at low-code and no-code systems over the last decade: abstraction does not eliminate complexity—it hides it, and when it resurfaces, it does so in places where the tools to manage it are scarcer.
Lock-in, Risks, and Open Questions
Being honest about an Alpha Preview project also means coming to terms with what doesn’t work yet, or what might never work as hoped. CodeSpeak raises a series of legitimate questions worth addressing without shortcuts.
The first risk is technological lock-in. Adopting CodeSpeak means relying on a proprietary language, a specific toolchain, and an LLM provider (currently Anthropic) for code generation. If tomorrow the project changes direction, the company developing it closes, or Anthropic’s API pricing model becomes unsustainable, what happens to the generated code? Technically, the Python code (or any other target language) continues to exist and is readable; the product of the work is not lost. But the ability to maintain it through specifications is lost, which means returning to the starting point, with the added difficulty of working on code that was not hand-written and may have non-obvious structures.
The second risk concerns the ambiguity of specifications. A traditional compiler is deterministic: given the same source code, it always produces the same output. An LLM is not. Two successive builds of the same specification can produce functionally equivalent but structurally different code, complicating debugging, versioning, and understanding what changed and why. The CodeSpeak team introduced tests as a stabilization mechanism (if tests pass, code is correct by definition), but this requires a sufficiently complete and well-designed test suite. In projects where tests are scarce or poorly written—and there are many more than admitted—the system loses one of its main safety nets.
The third risk is opaque debugging. When generated code doesn’t behave as the specification describes, where do you look for the problem? In the (ambiguous) specification, in the model (which misinterpreted), in the API version (silently changed), in the project context (which the LLM read partially)? The causal chain lengthens, and with it the time needed to isolate and correct the error. The team points to this as one of the priority improvement areas in the roadmap, but for now, it’s a real limit that anyone wanting to use CodeSpeak in production must account for.
Finally, there is the issue of portability. CodeSpeak currently supports Python, and only Python. Extension to other languages is on the roadmap but has no date yet. For the vast majority of enterprise projects using Java, TypeScript, Go, or polyglot stacks, this is a significant entry barrier.
That said, it would be unfair to use these limits to dismiss the project. They are the normal limits of an Alpha, not structural flaws of the idea. The more interesting question is not “does it work perfectly now?”—the answer is obviously no—but “does the idea hold up under pressure?”. And here the answer is less obvious and more interesting.
Roadmap and Perspectives
The public roadmap emerging from the blog posts is quite clear in its priorities. The theme of modularity, introduced with spec dependencies and managed files in March 2026, is the main construction site: making specifications composable and reusable is the prerequisite for scaling to real-sized projects. The codespeak takeover is being refined: the stated goal is to ensure the specification extracted from existing code is complete enough to regenerate an equivalent implementation from scratch, passing all original tests. There are no announcements yet regarding support for languages beyond Python or integrations with CI/CD systems.
The fundamental strategic question is whether CodeSpeak can aspire to become a de facto standard for what some already call “AI-native programming”—the design of languages and tools thought from the beginning for a world where part of the execution is delegated to language models—or whether it will remain a niche tool, adopted by teams with very high testing discipline and well-defined use cases. The answer will depend in part on the quality of execution, in part on the evolution of underlying models, and in part on ecosystem factors that are difficult to predict today.
Breslav has a clear position on the broader context. In the dialogue with the Pragmatic Engineer, he stated that 2026 will be the year of the rebirth of integrated development environments over terminal tools, not out of nostalgia, but because AI agents work better inside structured environments that offer rich context. It is a prediction that aligns perfectly with CodeSpeak’s philosophy: not the free prompt in the void, but human intention channeled into structures that the machine can reliably interpret.
The Changing Profession
There is a question hanging over all this that goes beyond technical considerations: what happens to developers’ work in a world where a tool like CodeSpeak works well?
The superficial answer, and the most common on social media, is that programmers become obsolete. Breslav explicitly rejects it with a sentence worth quoting in its entirety: “In the future, engineers will still be building complex systems. Keep that in mind: it’s not like we’re all going to disappear into thin air.” It’s not facade optimism: it’s the same logic that has guided every leap in abstraction in the history of computer science. Assembler did not eliminate programmers; C did not eliminate programmers; high-level languages did not eliminate programmers. They changed what they do, shifting the center of gravity of work from managing mechanical details to conceptual modeling of the problem.
CodeSpeak, if it delivers on its promises, shifts this center of gravity further. Less time writing boilerplate code, more time reasoning about what the system should do, designing the tests that verify its behavior, writing specifications that are precise without being rigid. It’s work closer to that of a software architect than a code craftsman, and historically, this type of transition has created more value than it has destroyed, even if it has redistributed roles and skills in a way that hasn’t been painless.
The real risk is not the disappearance of the programmer; it’s the concentration of opportunities. If maintaining a complex system requires only a tenth of the code lines, perhaps it also requires fewer developers to maintain it. The efficiency gained by more disciplined teams could translate into pressure on staff sizing, at least in the short term. It’s the classic paradox of technological productivity: it creates wealth in the aggregate but distributes it asymmetrically in the transition.
For younger developers, there is also a question of learning. Learning to program by writing code, with all the errors, debuggers open at three in the morning, the slow understanding of how memory or networking really work, is a formative path that has its own logic. A world where code is generated from specifications risks obscuring these layers of understanding. It’s not an insoluble problem—doctors still learn anatomy even if they no longer perform operations with bare hands—but it’s a question the sector will have to face consciously, not let it resolve itself.
A Language for Humans and Machines
Returning to where we started, to Breslav’s profile and the lessons of Kotlin, there is a red thread running through the whole story of CodeSpeak that is worth making explicit. Kotlin was born, among other things, from the realization that Java was stagnating: the language was not evolving at the speed required by developers, and the market was ready for something better. CodeSpeak is born from an analogous realization, but reversed: existing languages evolve too slowly compared to the speed at which AI agents are changing how code is produced. It’s not about a more ergonomic language for humans; it’s about the first language designed explicitly for a system where humans and LLMs collaborate, each doing the part for which they are best suited.
If this bet pays off, CodeSpeak could represent something more than a useful tool: it could be the first example of a new category, that of “AI-native” languages, designed from the start for a world where automatic code generation is not an exception but the norm. If it doesn’t pay off, due to technical limits, adoption issues, or because the evolution of models themselves makes the approach obsolete, it will still remain a valuable experiment that clarified what the right questions to ask are.
Breslav closes his interview with an invitation that sounds more like a challenge: “You shouldn’t blindly believe everything you read on Twitter: some people state absurd things. However, if used correctly, these tools can be very productive and it’s absolutely worth investing in them.” It’s the tone of someone who has already gone through a hype cycle—that of Kotlin—and knows that between initial enthusiasm and lasting utility there is always a stretch of difficult road to travel. CodeSpeak is at the beginning of that stretch. It’s worth following.


