Moonshot AI is rewriting the rules of artificial intelligence with Kimi K2 Thinking: a one-trillion-parameter open-source model that challenges GPT-5 and Claude, costing less than $5 million. On November 6, 2025, as the AI developer community casually scrolled through notifications on Hugging Face, a release appeared that might have seemed like just another Chinese language model. Kimi K2 Thinking, created by the Alibaba-backed startup Moonshot AI, promised the usual wonders: advanced agentic capabilities, a Mixture-of-Experts architecture, and a total of one trillion parameters.
But when the first benchmarks began to circulate, something unexpected emerged from the numbers: 44.9% on Humanity’s Last Exam, beating both GPT-5 and Claude Sonnet 4.5. Not by a little, not by a statistical error, but by margins that forced even the most skeptical to recalculate.

For those who don’t deal with the alphabet soup of AI acronyms daily, Humanity’s Last Exam is what happens when experts decide to halt the triumphant march of language models: three thousand questions crowdsourced from over a thousand specialists, designed to be too difficult even for the most advanced systems. Advanced mathematics, molecular biology, analytical philosophy, quantum physics. The kind of exam where GPT-4o stammers at 9% and even the most recent reasoning models struggle to surpass 30%. Kimi K2 Thinking crossed that threshold with a naturalness reminiscent of heist movies when the impossible job becomes routine: no spectacle, just methodical precision.
But this isn’t a story about a single exceptional model. It’s the chronicle of a moment when the impossible becomes the new normal, and the economic and geopolitical rules of AI are being rewritten by those who, theoretically, were supposed to be left behind.
Inside the Machine
To understand what makes K2 Thinking different, one must delve into its architecture, where engineering choices become declarations of intent. The model is built on a Mixture-of-Experts architecture with a total of one trillion parameters, but it only activates 32 billion for each token processed. It’s a strategy reminiscent of modular power plants: all that power exists, but it’s only called upon when necessary, drastically reducing operational costs without sacrificing capabilities.
The real innovation, however, is in the native INT4 quantization. While most models are trained in higher precision and then compressed, K2 Thinking was designed from the outset to operate in INT4, halving memory requirements and doubling inference speed without the typical accuracy losses that plague post-hoc compression. It’s the kind of choice that prioritizes operational efficiency over the vanity metric of total parameters, a philosophy that will become central when we talk about costs.
K2’s MoE architecture distributes the load across 384 specialized experts, compared to DeepSeek V3’s 256, allowing for greater granularity in skill selection. Each request activates a dynamic subset of these experts, and the system autonomously chooses which neurons to engage based on the type of problem. In practice, when K2 needs to write Python code, it activates a different set of experts than when it needs to solve differential equations or translate Sanskrit.
But the element that distinguishes K2 Thinking from its predecessors is test-time scaling, a technique that allows the model to “think longer” about complex problems. It’s not simple trial-and-error: the system can allocate more computational cycles to difficult questions, exploring alternative chains of reasoning before converging on an answer. This is what researchers call “thinking mode,” and it’s the reason K2 can tackle multi-step problems that would normally require human supervision.
On the agentic front, K2 demonstrates capabilities that until a few months ago were the prerogative of closed and expensive systems: it can execute 200-300 sequential tool calls without human intervention, navigating external APIs, processing structured data, and orchestrating complex workflows. The 256k token context window allows it to maintain coherence over extended conversations or lengthy technical documents, while the cache memory system reduces latency in repeated interactions.
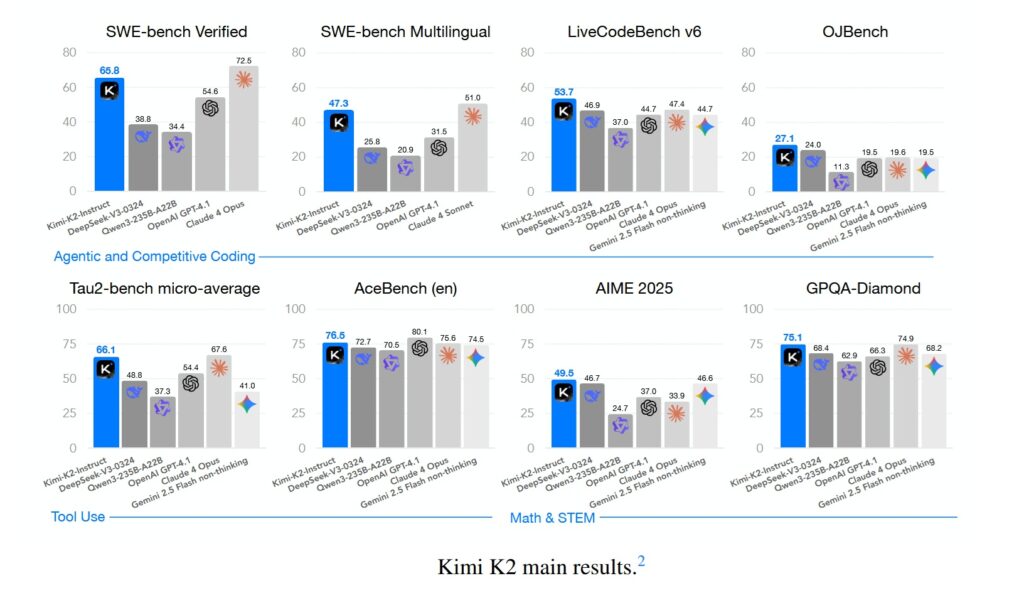
Image from the official paper on arxiv.org
The Numbers Speak
Benchmarks are the battleground where promises are measured against reality. On Humanity’s Last Exam, K2 Thinking achieves 44.9%, surpassing GPT-5 (42.1%) and Claude Sonnet 4.5 (41.7%). But the real differentiator emerges when looking at agentic tasks: on BrowseComp, which measures the ability to navigate the web and APIs autonomously, K2 gets 34.2% against GPT-5’s 28.5%. On SWE-Bench Verified, the benchmark for software engineering that requires solving real bugs in open-source codebases, K2 reaches 65.8%, surpassing practically every non-thinking model available.
Not everything shines equally. On GPQA Diamond, the dataset of graduate-level scientific questions, K2 stops at 75.1%, an excellent but not record-breaking result. And when GPT-5 is run in “heavy mode” with extended reasoning, it still manages to outperform K2 on some specific pure mathematics tasks. But what matters in the broader narrative is that these differences are marginal, and they disappear completely when considering the cost-performance ratio.
Because here emerges the data that has shaken Silicon Valley: K2 Thinking costs $0.33 per million input tokens and $1.33 for output. The standard GPT-5 stands at $1.25/$10, while GPT-5 in reasoning mode can go up to $50 per million output tokens. We are not talking about differences of 20-30%, but of an order of magnitude. For a company that processes tens of millions of tokens a day, the math becomes brutally simple.
And there’s a technical detail worth emphasizing: all of K2’s benchmarks were run in INT4, with no inflated precision tricks to gain percentage points. Some labs release impressive numbers in FP16, and then, when the model is actually deployed in production in a quantized form, performance plummets. K2 was tested under the same conditions it would be used in production, a transparency that should be standard but rarely is.
On LiveCodeBench v6, which tests the ability to write code for new problems never seen during training, K2 achieves 53.7%. On AIME 2025, the advanced mathematics exam for American students, it gets 49.5%. On OJBench, a Chinese benchmark for competitive programming, it reaches 27.1%. Numbers that individually might seem like technicalities, but which, when aggregated, paint the profile of a system that has crossed the threshold of practical utility across a very wide range of real-world applications.
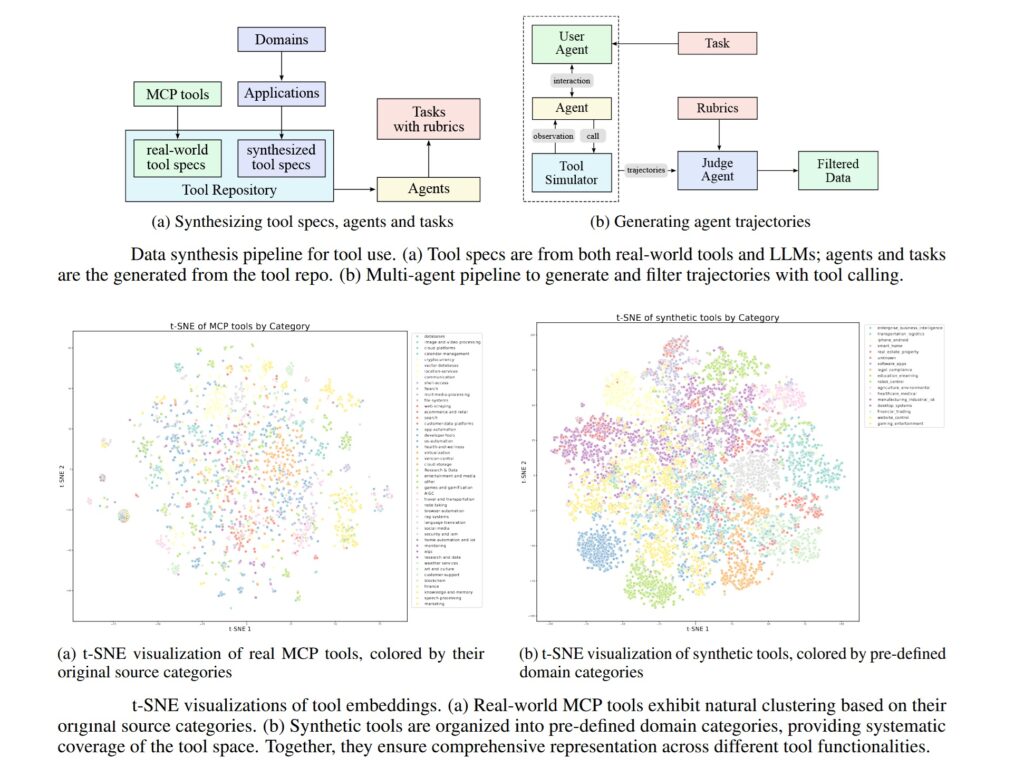
Image from the official paper on arxiv.org
The Critical Voice
Nathan Lambert is not the type to be easily impressed. An AI researcher at the Allen Institute for AI and author of the Interconnects newsletter, Lambert has spent years analyzing the gap between hype and reality in the industry. When he wrote his analysis of K2 Thinking, he posed a question that cuts like a scalpel: “What does it mean when a DeepSeek moment becomes routine?”
When DeepSeek V3 was released in late 2024 with a training cost of $5.6 million, the industry had a collective shudder. It was the anomaly that confirmed the rule: yes, it is possible to build competitive models with ridiculous budgets, but it remains an exception. Now, ten months later, we have Moonshot with K2, Qwen churning out releases, and a dozen other Chinese labs publishing open-source models every two weeks. Kimi’s servers are already saturated, a sign that we are not talking about tech demos but about systems that developers are actually deploying in production.
Lambert identifies five critical dynamics, and the first is the simplest but most devastating: Chinese labs release faster. Much faster. While Anthropic may take months to bring a model from the lab to production, and OpenAI positions itself somewhere in the middle, Chinese labs squeeze that cycle into weeks. When the pace of progress is high, being faster makes you seem better. Lambert estimates the raw performance gap between closed and open models at about four to six months, but then he poses the rhetorical question: if these closed models are not publicly available, do they really count?
The second point touches on something more nuanced: Chinese labs are dominating on key benchmarks, but there are “long-tail behaviors” for which they lack feedback loops. Lambert notes that Qwen, in the last year, has gone from being known for “benchmaxing” (obsessively optimizing benchmarks) to producing genuinely fantastic models that, incidentally, also have insane scores. DeepSeek and Kimi have what Lambert calls “good taste,” a quality that is hard to quantify but immediately perceptible when you use the models. But common user behaviors remain, especially Western ones, on which American companies have years of internal data and Chinese labs do not. These intangibles count for user retention, even if they don’t appear on Humanity’s Last Exam.
It’s here that Lambert acknowledges an often-overlooked technical detail: K2 Thinking was natively trained in INT4 during post-training, probably to make reinforcement learning scaling more efficient on long sequences. And all the reported benchmarks are in INT4, not inflated precision. It’s the honest way to make comparisons, Lambert notes, because that’s how the model will actually be served.
The third point is geopolitical and inexorable: at the beginning of 2025, most people following AI knew zero Chinese labs. Now, towards the end of the year, DeepSeek, Qwen, and Kimi are becoming common names. They all have seasons of better releases and different strengths. And the list will continue to grow: Lambert mentions Z.ai, Meituan, and Ant Ling as possible additions for 2026. Some of these labs started their foundation model efforts after DeepSeek, and in six months they have reached the ballpark of the open frontier. The question now is whether they can offer something in a niche of the frontier that has real user demand.
The fourth aspect concerns interleaved agentic capabilities: K2 Thinking can execute hundreds of sequential tool calls, a feature that has become standard in closed models like o3 and Grok 4. Technically, it’s not revolutionary; it emerges naturally during RL training, especially when the model has to search for information to answer correctly. But it is the first time this capability has appeared in an open model with this robustness, and providers hosting open weights will have to work hard to support it precisely. Lambert hopes there is enough user demand to mature the industry in serving open tool-use models.
The fifth point is the most worrying for American labs: the pressure is real. There is pressure on prices and expectations they have to manage. The differentiation and the narrative about why their closed services are better must evolve rapidly, moving away from benchmarks that even open-source now dominates. Lambert had anticipated this in his summer post “Some Thoughts on What Comes Next,” suggesting that future releases will increasingly resemble that of Claude 4, where gains on benchmarks are marginal but those in the real world are substantial. This transition will require much more nuance to understand if the pace of progress is continuing, especially when AI critics will exploit the plateau in evaluations to argue that AI no longer works.
Lambert’s final question is deceptively simple: are the existing distribution channels, products, and serving capacity sufficient to keep the value of all the major US AI companies stable? Lambert thinks they are safe, but Chinese models and companies are taking bigger slices of the growing AI pie. It won’t be a majority in terms of revenue, but it can be a majority in mindshare, especially in international markets.
What Lambert doesn’t say explicitly, but which emerges between the lines, is that we are witnessing not a competition but a bifurcation. Two parallel ecosystems that reinforce each other internally, but communicate less and less with each other. And when the question shifts from “who is ahead” to “who matters for which market,” the answers become unsettlingly geopolitical.
Geopolitics of Algorithms
To understand the broader context of K2 Thinking, one must look beyond Moonshot. China has six major AI labs that the specialized media have informally started calling the “AI Tigers”: DeepSeek, Moonshot, Alibaba (with Qwen), Baidu (with Ernie), ByteDance (with VolcEngine), and Tencent (with Hunyuan). Each releases major models every two to three months, creating a cadence that keeps the global industry in constant tension.
American export controls on advanced chips, designed to slow down Chinese AI development, have had a paradoxical effect. DeepSeek V3 was trained on the Nvidia H800, a less powerful version of the H100 that the US banned for China in 2022. The subsequent ban also hit the H800s in 2023, but by then the path was set: Chinese labs learned to extract frontier performance from suboptimal hardware through aggressive software optimizations.
The training cost is the data point that continues to dominate the narrative. K2 Thinking required less than $5 million, according to official estimates. DeepSeek V3 had cost $5.6 million. For comparison, GPT-4 had required over $100 million in 2023, and rumors about GPT-5 speak of budgets in the order of billions. Emad Mostaque, former CEO of Stability AI, tweeted that with the new generation of Nvidia Blackwell chips, it would only take $3 million to train a model competitive with current frontier models.
These numbers have direct implications for the market. Companies like Airbnb have already publicly stated that they use Qwen for some internal applications, prioritizing the cost-performance ratio over brand recognition. And while OpenAI and Anthropic defend their pricing by arguing that operational costs remain high, the reality is that the market is discovering that “good enough and ten times cheaper” beats “perfect but prohibitive” in most real-world use cases.
The Modified MIT license under which K2 Thinking is released deserves a note. It is technically open source, allows for commercial use and modifications, but includes clauses that limit the use of the names “Moonshot” and “Kimi” in derivative products. It’s a compromise between genuine openness and brand protection, a strategy that Chinese labs are perfecting to maximize adoption without giving up narrative control.
Who wins and who loses in this scenario? Developers win, gaining access to technologies that until yesterday cost tens of thousands of dollars a month in API calls. Startups win, being able to compete with incumbents whose moat was based on privileged access to proprietary models. Western open-source labs lose relevance, crushed between Chinese speed and the (presumed) quality of American closed models. And the American giants themselves are in a delicate position: continuing with the closed strategy risks making them irrelevant in the long term, but opening up completely would mean cannibalizing the revenue streams that finance R&D.
The real loser, perhaps, is the very idea of a unified global AI ecosystem. We are witnessing the crystallization of parallel technological spheres of influence, each with its own standards, datasets, biases, and values. And when Lambert asks whether this is democratization or fragmentation, the honest answer is: probably both, simultaneously.
Near Future
K2 Thinking is not a tech demo released to make noise and then be forgotten. Moonshot’s servers are currently saturated, with waiting times that at peak times exceed ten minutes to get a response. It’s the kind of problem that startups dream of having: too much demand, not enough capacity. But it signals something deeper: developers are actually deploying these models in production, not just testing them out of curiosity.
The most immediate impact is on the client-supplier dynamic in AI. For years, the power relationship was unbalanced: if you wanted frontier capabilities, you had to accept the terms of OpenAI or Anthropic, including pricing, rate limits, and data policies. With K2 and its ilk, the calculation changes. A company can download the weights, deploy on-premise or on a cloud of its choice, and have complete control over latency, privacy, and operational costs. It’s not perfect for all use cases, but for a significant portion of the market, it’s more than enough.
Many open questions remain. Native multimodality, for example: K2 Thinking is still primarily text-based, while GPT-4 and Claude can process images, audio, and video in an integrated way. Reasoning traces, those explicit chains of thought that models like o1 and R1 show, are less transparent in K2, making debugging more difficult when the model makes a mistake. And the question of long-term sustainability: can Moonshot, with a fraction of OpenAI’s resources, maintain this pace of innovation?
But perhaps the most interesting question is the one Lambert implicitly leaves open: what happens when the impossible becomes routine? When K2 Thinking was released, many reacted with enthusiasm. The next Chinese model that beats the benchmarks will get less media coverage. The one after that, even less. Not because they are less technically impressive, but because the expectation curve will have shifted.
We are at that point in the heist movie where the protagonists have perfected the job to the point that it seems almost boring. Enter the vault, bypass the systems, get out clean. No drama, just execution. It is the most dangerous moment, the one where overconfidence leads to mistakes. And in the context of AI, mistakes don’t mean failing a benchmark, but deploying systems that will make critical decisions without us fully understanding how or why.
K2 Thinking is a remarkable technical achievement. But its true importance may be to mark the moment when we stopped being amazed, and started to assume that this level of capability is the new baseline. And when the exceptional becomes ordinary, that’s where the really interesting problems begin.