
En esta segunda parte sobre DevOps, hablaré de la entrega continua o «Continuous Delivery» y de la ingeniería de fiabilidad de sitios o «Site Reliability Engineering».
Si DevOps nos guía en la promesa de construir software que está siempre en estado entregable y que una vez que se entrega se mantiene estable y fácil de operar, los principios DevOps se materializan mediante la adopción de ciertas prácticas de ingeniería de software y de herramientas de automatización. Estas prácticas son numerosas por lo que para estructurar mejor nuestro entendimiento las organizamos en dos grandes grupos, la entrega continua y la ingeniería de fiabilidad de sitios.

Ambos conceptos se definieron por primera vez en los libros homónimos, considerados clásicos de la literatura de la ingeniería del software. Me refiero a los libros «Continuous Delivery»1 de Jezz Humble y David Farley, publicado en 2010 exponiendo los fundamentos de los procesos de entrega de software con bajo riesgo, rápidos y fiables; y «Site Reliability Engineering»2 editado en 2016 por Betsy Beyer, Chris Jones, Jennifer Petoff, y Niall Murphy reflejando la perspectiva de cómo Google gestiona sus sistemas productivos.
Una manera sencilla de definir la entrega continua es como la habilidad de una organización o equipo para mantener el software siempre en un estado entregable, a través de cambios pequeños y frecuentes y un conjunto suficiente de validaciones automáticas que garantiza la calidad del software tras cada cambio, por pequeño que sea (se ponga o no ese cambio en producción).
La ingeniería de la fiabilidad de sitios se puede definir como la habilidad de una organización o equipo para mantener sistemas de software escalables y resistentes a los errores, adoptando prácticas propias de la ingeniería del software a las actividades de operación de las soluciones y gestión de las infraestructuras.
Es posible que hayáis leído o escuchado que la entrega continua es DevOps desde el «lado Dev» y que la ingeniería de fiabilidad de sitios es DevOps desde el «lado Ops», pero no solo es inapropiado hablar de lados en DevOps (recordad: sin silos) sino que esa visión tan simplista es muy inexacta.
Eso es así porque ambos conjuntos de prácticas son complementarios y están interrelacionados.
¿Por qué son complementarias la entrega continua y la fiabilidad de sitios?
No se puede ser una organización que cumple las expectativas de los principios DevOps si no se implementan armoniosamente las prácticas que promueven tanto la entrega continua como la ingeniería de fiabilidad de sitios. No tiene sentido ser una organización súper ágil en la manera en la que llevamos cambios de aplicaciones a producción si luego no podemos mantener un mínimo de estabilidad y operación de esas aplicaciones.
La entrega continua se centra en la cadencia del cambio y el tiempo a mercado. Se pone foco en tener una estrategia de puesta en producción clara con flujos de trabajo definidos, reducir las dependencias entre equipos, mantener la trazabilidad de todos los cambios, automatizar todas las tareas posibles mediante pipelines de integración y despliegue continuos, y adelantar tanto como sea posible (shift-left) todas las validaciones de calidad y seguridad de las aplicaciones, datos, plataformas e infraestructuras.
La ingeniería de fiabilidad de los sitios se centra en la disponibilidad de los sistemas. Se pone foco en el tiempo que el sistema está disponible, el rendimiento, la tolerancia a los fallos, la capacidad para degradarse grácilmente, la planificación de capacidad frente a eventos, o los planes de respuesta a emergencias.
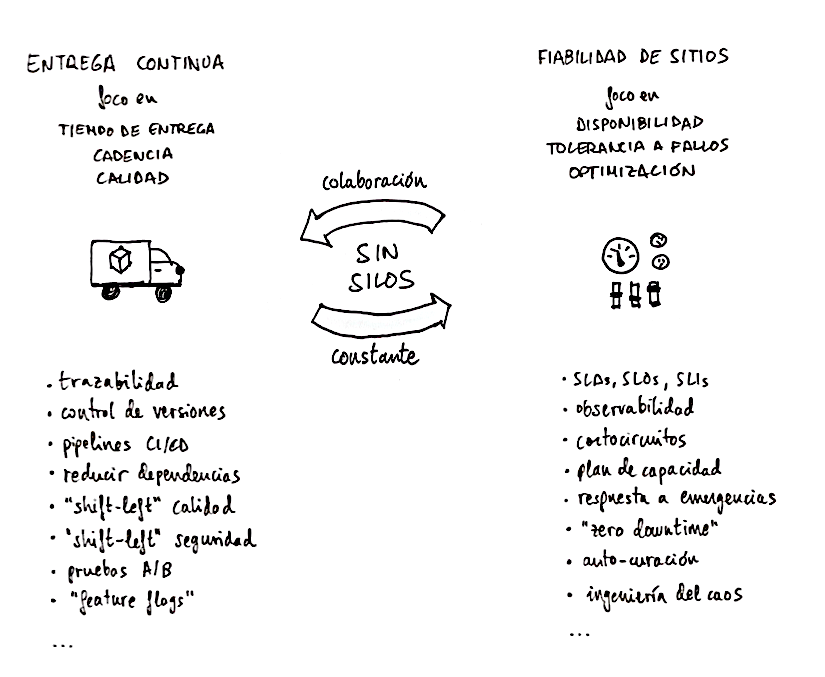
Diagrama sobre la relación entre la entrega continua y la fiabilidad de sitios.
¿Cómo se interrelacionan la entrega continua y la fiabilidad de sitios?
Ambos conjuntos de prácticas tienen muchos puntos en común, como no podía ser menos, puesto que abogamos por la colaboración constante entre desarrollo y operaciones, con objetivos y preocupaciones compartidas (sin silos; sí, ya sé que soy «muy pesado» con eso).
Un ejemplo de esas preocupaciones compartidas entre ambos conjuntos de prácticas es la capacidad para hacer pruebas en producción gracias a técnicas como las pruebas A/B, la activación de capacidades a demanda del negocio mediante «feature flags», o los despliegues de tipo «canary». Otro ejemplo habitual es la colaboración en la detección y resolución de incidentes gracias a la telemetría que se captura de los sistemas activos, la detección temprana de problemas, y a las capacidades de auto-escalado y de auto-curación de las aplicaciones, plataformas e infraestructura. También es un ejemplo de preocupación compartida el tener la habilidad para hacer despliegues de cambios sin caída del servicio y con una estrategia de vuelta atrás definida.
En la próxima sección entraré en detalle en las prácticas de automatización, desarrollando brevemente en qué consisten, y cómo están conectadas con la entrega continua y la ingeniería de fiabilidad de sitios.
Prácticas de Automatización de DevOps vs. CD vs. SRE
Hay muchas formas de clasificar las prácticas de automatización de DevOps pero a mí me ayuda mucho estructurarlas en 6 grupos de prácticas de la siguiente forma:
- Gestión del ciclo de vida de las aplicaciones (Application Life-cycle Management).
- Integración continua (Continuous Integration).
- Despliegue continuo (Continuous Deployment).
- Validación o «testing» continuo (Continuous Testing).
- Infraestructura continua (Continuous Infrastructure).
- Operaciones continuas (Continuous Operations).
En su mayoría, como podéis ver, se pone énfasis en «continuo» como sinónimo de que son prácticas que se aplican, de forma consistente, para cada cambio en el sistema (idealmente cuanto más pequeño mejor), sin intervención humana (o ésta es mínima) y sin disrupción en la prestación de los servicios.
Veamos ahora cada grupo con algo más de detalle.
Gestión del ciclo de vida de las aplicaciones
La gestión del ciclo de vida se refiere a la habilidad de tener completa trazabilidad de las actividades relacionadas con el ciclo de vida de los desarrollos, desde requerimientos a entregas, así como a las actividades de la operación, desde tareas periódicas de mantenimiento a la resolución de incidentes.
Se fundamenta en una gestión de la configuración exquisita, con estrategias de versionado y ramas consistentes, y que es inclusiva de todos los elementos del sistema, tanto aplicaciones como datos o piezas de la infraestructura (más sobre este último aspecto en el apartado sobre infraestructura continua).
Tendremos una identificación precisa sobre quién hizo qué, cuándo y por qué, independientemente de la capa o componente donde impactara el cambio. La gestión de dependencias será clara y evitaremos sorpresas como las que suceden, a modo de ejemplo, cuando no se han identificados ciertos artefactos software y solo se descubre su falta en el momento de una entrega o cuando los cambios ya están desplegado en producción y suceden errores imprevistos.
Por tanto, una gestión del ciclo de vida de las aplicaciones adecuada es imprescindible tanto para conseguir los objetivos de velocidad y éxito en las entregas como la fiabilidad, resiliencia y operabilidad de los sistemas.
Ejemplos de herramientas de ciclo de vida son: GitHub, GitLab, Jira, BitBucket, Azure DevOps, Nexus Repository, o Artifactory.
Integración continua
La integración continua fue definida en septiembre del año 2000 por Martin Fowler en un famoso blog considerado todo un clásico3. Desde entonces, aunque ha mantenido esa pieza en constante revisión (la última de enero de 2024) y se ha expandido tanto en el libro homónimo como en múltiples otros lugares, se ha mantenido intacto el significado de lo que es y lo que no es integración continua.
En breve: la integración continua es el proceso por el cual de forma frecuente (al menos una vez al día) los miembros de un equipo integran los cambios de sus compañeros sobre sus propios cambios, validan que el funcionamiento tras la integración de esos cambios sigue siendo el esperado («green tests») y se comparte el código al repositorio común («git push») para que un entorno centralizado (el motor de integración continua) realice un proceso de construcción automático (lo que normalmente llamamos una «build») y ejecutará de nuevo todas las pruebas concluyendo en un producto candidato para ser entregado («shippable product») o en un aviso a los desarrolladores de que algo no funciona como se espera.
Practicar integración continua implica, entre otras cosas, que los miembros de los equipos validan sus cambios e integran los cambios de sus compañeros de forma frecuente para evitar que se acumulen los cambios pendientes de integrar. De forma implícita promueve una estrategia de ramas sencilla con múltiples ramas de tipo «feature» de vida corta además del tronco o «main» donde está la versión más actual del código. Finalmente, practicar integración continua implica que si una «build» falla, el equipo para todo el trabajo en curso para resolverlo, antes de retomar el trabajo planificado. De ese modo, el estado del tronco o «main» será siempre estable (aunque no necesariamente entregable; más sobre esto cuando se trate la validación continua).
Mediante la integración continua conseguimos detectar de forma temprana problemas derivados de la integración de cambios que se han realizado de forma independiente por distintos miembros del equipo (o del mismo desarrollador para dos peticiones diferentes) sobre cualquier componente software del sistema. Se gana en calidad de los entregables y en productividad del equipo ya que resolver esas situaciones en pequeños lotes es mucho más óptimo que integrar cientos de cambios a la vez.
Si además complementamos la integración continua con otro tipo de validaciones como la inspección de código y configuración, el análisis de dependencias o la identificación de vulnerabilidades de seguridad, se consigue aumentar aun más la calidad del software mediante la detección temprana de ese tipo de defectos.
La integración continua tiene además otro beneficio adicional: el proceso que transforma código y configuración en software que funciona es un proceso bien conocido, repetible, automático, mucho más fiable que los procesos manuales que suelen tener una alta tasa de fallo, que no están documentados o que directamente requieren del conocimiento «tribal» de algunos (pocos) miembros del equipo. A la secuencia que transforma el código en un producto candidato es a lo que normalmente llamamos el «pipeline» de integración continua.
Por tanto, la integración continua ayuda fundamentalmente a cumplir con los objetivos de la entrega continua.
Ejemplos de herramientas de integración continua son: Jenkins, GitHub Actions, GitLab CI/CD, Azure Pipelines, o CircleCI.
También son muy relevantes para los «pipelines» de CI las herramientas que interactúan con los distintos lenguajes y plataformas, ya sea para gestionar dependencias, compilar, transformar, empaquetar, validar la calidad del código, ejecutar pruebas unitarias, o identificar vulnerabilidades. Por ejemplo: Maven, Gradle, Grunt, npm, webpack, pip, SonarQube, Checkstyle, SpotBugs, ESLint, OWASP Dependency Track, y un largo etc.
Despliegue continuo
Consiste en la capacidad para desplegar cambios de forma automática a todos los entornos incluido el productivo, de forma orquestada incluyendo dependencias (con otras aplicaciones, sistemas externos, datos), así como cualquier tipo de umbral («gate») como son, por ejemplo: verificación de momento del despliegue frente a las ventanas definidas, la validación del éxito de pruebas de aceptación y regresión en un entorno previo, o un paso de aprobación manual por parte de un responsable de negocio.
Una práctica de despliegue continuo saludable además cuenta con procesos de marcha atrás («rollback») bien definidos y que se ejecutan ya sea automáticamente o de forma manual. Un ejemplo de «rollback» automático sería el que se hace sin intervención cuando fallan las pruebas realizadas en producción post-despliegue, como pruebas operacionales o pruebas de humo.
Desplegar continuamente es más que tener un automatismo. Un «shell script» que sube un fichero por scp y ejecuta un comando de reinicio por ssh es fácil de hacer. La dificultad, en algunos casos máxima, reside en orquestar procesos complejos, aplicaciones con muchos componentes, dependencias con librerías de terceros o con otras aplicaciones, ser consistentes en el despliegue de cambios de la aplicación junto con cambios en datos (y que se pueda hacer un «rollback» seguro de la aplicación considerando que seguramente no se podrá hacer marcha atrás de los cambios en los datos), o ser capaces de implantar un proceso de despliegue que no suponga interrupciones al servicio (como pueden ser despliegues «canary», «azul/verde» o «rolling»).
La práctica de despliegue continuo es terreno colaborativo tanto de Dev como de Ops, una preocupación de la entrega continua y de la fiabilidad de los sitios, y es por tanto de esperar que sea una de las prácticas donde mayor colaboración e interacción exista entre ambos grupos.
Disponer de un proceso automático y desatendido facilita en gran medida la trazabilidad de los cambios desplegados a través de todos los entornos, así como disponer de artefactos firmados digitalmente con los que podamos prevenir cambios no deseados por ataques en la «cadena de suministro» del software («secure software supply chain»).
Ejemplos de herramientas de despliegue continuo (y de orquestación de aplicaciones) son: Jenkins, CloudBees CD/RO, AutoRABIT, Flyway, Liquibase, Helm, Terraform, o Ansible. Y muchas, muchas, líneas de «shell script».
Validación continua
O como algunas veces me gusta llamarla: «esa gran desconocida».
Ironías aparte, en mi experiencia es una práctica muchas veces denostada, arrinconada o adoptada de forma muy incompleta en los proyectos del mundo real. ¿Qué pasa cuando un proyecto va mal en fecha? ¿Qué suele verse sacrificado lo primero? ¿Recortamos alcance? No; con mucha frecuencia, se reduce la carga de trabajo en tareas de aseguramiento de la calidad. Es aun muy común ver proyectos, incluso tecnológicamente punteros, con mínimas o ninguna pruebas unitarias automáticas, pruebas que «van de visita» sin validar ningún resultado, pruebas de aceptación testimoniales, o pruebas de regresión limitadas al «voy a darle una vuelta» de forma manual.
Sin validación continua no puede haber entrega continua. No importa cuánto y bueno sean la integración continua y el despliegue continuo, que sin un conjunto suficiente de pruebas de validación del software no podemos considerar si éste está o no en estado entregable. Y garantizar el estado entregable del software es la pieza angular de la entrega continua: ser capaces de llevar cambios a producción con bajo riesgo, rápida y consistentemente.
La validación continua implica la ejecución de pruebas automáticas de forma temprana y frecuente en entornos equivalentes al de producción. Debido al énfasis en que la validación es continua, de forma frecuente significa que las ejecutaremos tras cada cambio, o como mínimo una vez al día alineados a la práctica de integración continua. Que se hagan de forma temprana implica que desde la primera línea de código existen las pruebas necesarias para la validación. Se puede practicar TDD, BDD o no, pero todo cambio lleva emparejado el cambio en scripts y datos de prueba. Entornos equivalente al de producción significa que podemos aprovisionar un entorno efímero a partir de la misma definición del productivo, con las mismas piezas de infraestructura y versiones, cargarlo con datos significativos, y una vez ya no es necesario, eliminarlo para ahorrar en recursos.
Ejemplos de herramientas de validación continua son: JUnit, JaCoCo, Pitest, Karma, Mocha, Jasmine, Cypress, Selenium, SoapUI, JMeter, Gatling, y otro largo etcétera. Muchas de estas herramientas ya se habrán utilizado como parte de los «pipelines» de integración continua para la ejecución y validación de las pruebas unitarias, por lo que su uso es transversal y encajará más allá o acá según el tipo de pruebas que se automatizan y su lugar dentro de la pirámide del «testing».
Infraestructura continua
La infraestructura continua se basa en tres pilares: la infraestructura como código (o infraestructura definida por software); la integración de las capacidades de resiliencia, disponibilidad, o escalabilidad, en la propia definición de la infraestructura y no como una consideración posterior; y la capacidad de validar continuamente cambios en la infraestructura de modo análogo a como la integración continua lo hace para los componentes software (para que sea realmente continua).
La infraestructura como código nos permite generar entornos completamente funcionales a partir de la nada. Mediante herramientas especializadas y scripts somos capaces de validar pre-requisitos y generar todas las capas de la infraestructura como son: redes, discos, computación, bases de datos, servicios «serverless», y un largo etcétera. La definición asume pocas o ninguna dependencias externas, idealmente agrupando consideraciones comunes en capas de abstracción como puede ser una «landing zone» de la que heredan propiedades el resto de entornos, o una estructura modular alineada con las capas conceptuales de la arquitectura.
La infraestructura como código permite adoptar estrategias de entornos efímeros, que existen solo cuando son necesarios lo que permite ahorrar en costes si lo comparamos con tener entornos 24×7 operativos se estén usando o no. Es clave para tener entornos equivalentes al de producción lo que facilita la detección temprana de problemas y la repetibilidad de incidentes en la producción cuando se repiten en entornos previos o creados específicamente para investigar el suceso.
Emparejada con el control de versiones, la infraestructura como código facilita las necesidades de trazabilidad y gobierno, incluyendo el mantenimiento de inventarios completos (SBOM o «software bill of materials») y la certificación de soluciones (clave en entornos regulados como son las infraestructuras críticas de un país).
Otro beneficio es que habilita la práctica de GitOps: la validación y despliegue de nuevas versiones de las infraestructuras y plataformas a partir de cambios en los repositorios, validar y propagar los cambios a través de tantos entornos como sea necesario. Es la fusión perfecta entre la integración continua y la validación continua pero para los componentes de infraestructura y plataforma.
Una práctica de infraestructura continua aporta una capa adicional de tranquilidad respecto a la estabilidad de los negocios. Poder generar un entorno productivo al completo desde cero, con todos los componentes necesarios en las versiones correctas (porque todo está bajo control de versiones y trazado) y con la última versión de los datos, y poder hacerlo en pocas horas, significa minimizar disrupciones incluso en casos severos de pérdidas de disponibilidad de servicios. Sobrevivir incluso a la pérdida completa de un centro de datos moviendo la producción a una región alternativa. Es decir: la «red de seguridad» definitiva.
Esta práctica es fundamental para los objetivos de SRE pero es también importante para la entrega continua al facilitar las actividades de validación de los cambios en entornos equivalentes al de producción y garantizar el estado entregable de una solución.
Ejemplos de herramientas de infraestructura continua son: VirtualBox, Vagrant, Docker, Kubernetes, Rancher, Terraform, Ansible, etc. Y, por supuesto, los proveedores de servicios de infraestructura y plataformas como: VMware, Amazon Web Services, Google Cloud, Microsoft Azure, OVHcloud, etc.
Operaciones continuas
Las operaciones continuas se basan en tres pilares: la observabilidad, o capacidad de recolectar información a través de todos los entornos y funciones de un sistema y tomar una posición proactiva en la detección y resolución de incidentes; la ingeniería del caos, que nos permite abordar la detección temprana de problemas de infraestructura de forma estructurada (y científica) en base a la ideación de experimentos y validación de las hipótesis sobre el comportamiento esperado del sistema; y los planos de control de la infraestructura que permiten a los sistemas auto-monitorizarse y actuar sin intervención humana para resolver situaciones de disponibilidad, escalado, degradación de servicios, contención de fallos, etc.
Mediante la introducción de una estrategia de observabilidad y herramientas de monitorización modernas podemos realizar una recopilación exhaustiva de telemetría de todos los componentes de un sistema y dejar de ser reactivos a incidentes. Estableciendo objetivos de nivel de servicio («service-level objectives», SLOs) e indicadores de nivel de servicio («service-level indicators», SLIs), podemos tener el control continuo sobre el rendimiento y disponibilidad del sistema, entender qué margen de actuación tenemos (la diferencia entre el SLO y el SLI, también conocido como el «error budget») y actuar proactivamente ante cualquier riesgo de que no pueda cumplirse el SLO.
Una estrategia adecuada de observabilidad también nos permite obtener métricas relevantes para el análisis del rendimiento del negocio como son: comportamiento de usuarios, uso de características específicas (muy potente si se alinea con pruebas A/B o la activación de características o «feature flags»), información en tiempo real de KPIs de negocio, etc.
Es posible optimizar los costes de las infraestructuras monitorizando el uso y adaptando en tiempo real los recursos a las necesidades reales, escalando en ambos sentidos según el momento, así como identificar características poco o nunca utilizadas y considerar su eliminación del sistema.
Los experimentos de ingeniería del caos nos facilitan validar el diseño de la resiliencia de nuestros sistemas comenzando por lo que sabemos o creemos saber («known knowns»), aumentando progresivamente la dificultad y alcance de los experimentos hasta cubrir todo lo que no sabemos o no hemos medido antes («known unknowns», «unknown unknowns»).
Un ejemplo de experimento sobre una base conocida es: si una réplica del servicio de autentificación falla no habrá pérdida de servicio porque el resto de réplicas podrán absorber la carga hasta 1.000 usuarios por minuto. O también: si un nodo de nuestro clúster Kubernetes falla otro nodo estará disponible y los servicios de vuelta en funcionamiento en menos de 2 minutos.
Un ejemplo de experimento sobre una base desconocidos puede ser: el tiempo de recuperación de servicios en caso de que sufriéramos la pérdida completa del centro de datos de Europa Sur debería ser inferior a las 4 horas para cumplir el objetivo (RTO o «recovery time objective»), pero no estamos seguros de ello ya que nunca se ha ejecutado ese escenario. No solo deberíamos validar los tiempos de recuperación sino si la monitorización es capaz de hacer detección temprana de un suceso de esa envergadura o si la automatización disponible actualmente puede recrear el entorno al completo sin intervención manual.
Contar con unas operaciones de este nivel es preocupación fundamental de SRE pero con enorme colaboración de los equipos de desarrollo en consideraciones de diseño de la resiliencia, exportar y disponibilizar los datos de telemetría, contar con registros operacionales como los logs de las aplicaciones, o la resolución rápida de incidentes.
Ejemplos de plataformas y herramientas ampliamente utilizadas en estas prácticas son: Elastic, Dynatrace, Grafana, Prometheus, New Relic, influxdata, DataDog, AppDynamics, Viewtinet, Nagios, Litmus Chaos, Gremlin, etc.
Conclusiones
Cerrando el círculo, el siguiente diagrama trata de recoger de un vistazo la relación entre las prácticas de automatización de DevOps y su impacto en conseguir los objetivos tanto de la entrega continua como de la ingeniería de fiabilidad de sitios.
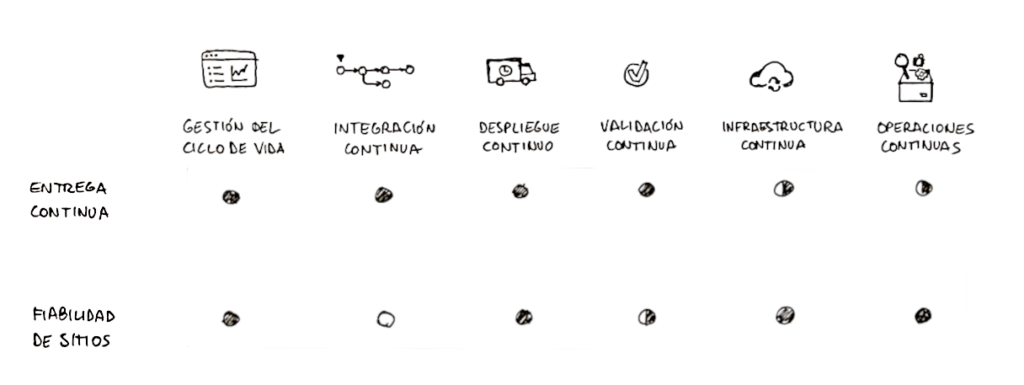
Diagrama con la relación entre los grupos de prácticas de DevOps,
la entrega continua y la fiabilidad de sitios.
En el próximo artículo de la serie continuaré profundizando en aspectos relacionados con DevOps hablando de la experiencia del desarrollador, o «Developer Experience».
¡Hasta pronto!
Sobre el autor
Jorge Hidalgo es director de ingeniería de software en Accenture, responsable de DevOps en Accenture Iberia y de la unidad de Arquitectura y Plataformas Cloud y DevOps en Accenture EMEA South Advanced Technology Center. Es también responsable en Accenture globalmente de la comunidad de práctica Java y Java Champion desde 2023.
Jorge cuenta con más de 25 años de experiencia en la industria, principalmente con tecnologías Java, web, cloud, DevOps, agilidad y ciberseguridad. Además de desarrollar su actividad profesional con clientes, es una figura activa en las comunidades tecnológicas, tanto como ponente en numerosos eventos locales e internacionales, como liderando la actividad de comunidades como Málaga JUG, Málaga Scala Developers y BoquerónSec, así como colaborando en la organización de eventos como OpenSouthCode o Codemotion.


