
Seamos fabulosos hoy y cada día
Si tu portal interno se parece más a una «wiki fandom» que a una verdadera plataforma de desarrollo, no estás solo. Muchas organizaciones, con buena intención, han invertido tiempo y recursos en construir interfaces bonitas pero poco útiles, creyendo que un listado de enlaces es suficiente para resolver todos los problemas del ciclo de vida del desarrollo o que resolverlo era cuestión de lanzar un proyecto limitado en el tiempo y luego olvidarse de ello. La experiencia del desarrollador mejora cuando reducimos la fricción entre roles y potenciamos la independencia y productividad de los equipos, no con más clics. Especialmente, cuando son clics que apuntan a enlaces muertos o contenido desfasado.
En esta cuarta entrega de mi serie sobre el futuro de DevOps, en directa continuación con la tercera, exploramos una de las estrategias más potentes para conseguir mejorar la DevEx de la organización: los portales y plataformas internas para el desarrollo. Veremos por qué, para que cumplan su promesa y evitar que se conviertan en otro «cacharro» inútil, es necesario entender qué significa diseñar una plataforma interna como si de un producto de mercado se tratara.

El espejismo del portal: de la documentación al producto
Durante años, muchas organizaciones han perseguido el sueño del portal interno ideal. Uno donde todo esté a un clic de distancia: documentación impecable, catálogos de servicios súper exhaustivos, formularios de onboarding, enlaces a pipelines para ver los resultados de una build, dashboards de observabilidad… Pero la realidad cotidiana es otra: portales desactualizados, difíciles de navegar y que en el fondo no resuelven el problema esencial de la experiencia del desarrollador.
El verdadero reto comienza cuando entendemos que el portal no está diseñado para servir a «usuarios genéricos», sino a personas frente al PC con roles muy específicos: desarrolladores, ingenieros de fiabilidad, responsables de QA, product managers técnicos y más. Cada uno con sus flujos de trabajo, necesidades y puntos de fricción. Por eso, así como en retail, banca o viajes hablamos de «customer journeys», en el mundo del software necesitamos asumir el diseño consciente de un «developer journey». Un recorrido pensado, no improvisado, donde el portal es el punto de entrada, no el destino final.
Ese recorrido cobra sentido si hay algo valioso detrás de la fachada: una plataforma interna de desarrollo capaz de responder a las necesidades de los equipos. Entendida como un producto aunque sus clientes sean personal interno y colaboradores. Además, construida bajo un enfoque API-first para ampliar su impacto a múltiples canales.
Esto significa no solo tener automatismos, sino asegurarse de que cada capacidad de la plataforma —desde desplegar una app hasta registrar un dominio; desde escalar una web hasta abrir un puerto en el firewall corporativo— esté expuesta como un servicio accesible mediante APIs públicas dentro de la organización. El portal entonces deja de ser una interfaz rígida y se convierte en uno de los varios canales posibles para interactuar con esa plataforma. Igual de válidos pueden ser una CLI, un asistente virtual en el IDE o integraciones automáticas vía GitOps. Como en los productos de mercado exitosos, la experiencia no depende tan solo de la idoneidad de un canal como es la web, sino de las opciones que se ofrecen a los usuarios y de la consistencia entre los distintos canales.
Aquí es donde podemos aprender de los grandes que brillan con sus plataformas de mercado. Plataformas como Amazon Web Services, Microsoft Azure, Google Cloud Platform o Salesforce no se limitan a ofrecer un portal web bonito. Lo que las hace exitosas es que han sido diseñadas desde el principio como productos API-first, donde el portal es solo una de las formas de acceso. Todas ellas ofrecen SDKs, CLIs, APIs REST, GraphQL, herramientas de automatización, y experiencias integradas en IDEs o pipelines. Y lo más importante: todas tratan su plataforma como un producto vivo, con métricas, feedback continuo, y una obsesión por la experiencia de sus usuarios, los equipos de desarrollo.
Si aspiramos a que nuestra plataforma interna tenga impacto real, debemos aplicar los mismos principios de diseño que observamos en estas plataformas líderes: pensar en producto, diseñar para múltiples canales, exponer capacidades vía APIs, y construir con foco en la experiencia. Solo así dejaremos de construir portales que son «desvanes» de enlaces olvidados, y empezaremos a entregar plataformas que realmente dan autonomía a nuestros equipos.
¿Qué significa realmente «plataforma» en este contexto?
Como hemos introducido en la sección anterior, cuando hablamos de «plataforma interna para el desarrollo» aún hay cierta confusión en muchas organizaciones. Se confunde un portal bonito con una plataforma funcional. O se piensa que una plataforma interna no es más que un proyecto puntual de infraestructura o una iniciativa puntual de un equipo entusiasta.
Se olvida, o no se conoce, que es, ante todo, un producto digital interno, con su propia estrategia, equipo, ciclo de vida y usuarios a los que debe servir (¡y presupuesto propio también!). Cuando miro atrás a los últimos 5 años y busco los elementos comunes en las organizaciones que conozco y que han tenido éxito en su camino hacia la DevEx encuentro justamente eso: la visión producto.
Y eso exige algo que muchas veces falta: esponsorización real por parte de los líderes ejecutivos de la organización. No basta con decir «apostamos por mejorar la DevEx». Una plataforma como producto requiere visión a largo plazo, respaldo presupuestario sostenido y voluntad explícita de escalarla como infraestructura crítica. No estamos hablando de un experimento aislado: estamos hablando del sistema nervioso de la ingeniería interna. Si la plataforma no tiene dueño claro, no tiene hoja de ruta ni mecanismos de mejora continua, está condenada a convertirse en un «cajón» más de herramientas olvidadas.
Otro elemento clave del éxito es la flexibilidad. Si la plataforma no ofrece flexibilidad real, los equipos se la buscarán por su cuenta. Cuando los estándares se imponen de forma rígida, sin espacio para la adaptación, lo que se genera no es alineamiento, sino plataformas en la sombra: soluciones paralelas, no soportadas, que nacen de la necesidad de avanzar. Y cuando eso ocurre, fallamos en el objetivo de escalar la adopción de la plataforma oficial. Nadie quiere usar una herramienta que no resuelve sus problemas reales, y eso acaba conduciendo la plataforma al desuso y al abandono.
Por eso, el equilibrio entre prescripción y flexibilidad es esencial. Y para que funcione, necesitamos guardarraíles claros. Mecanismos que permitan a los equipos moverse con autonomía, pero dentro de un marco que garantice la resiliencia, la seguridad y el cumplimiento normativo. Esto es especialmente relevante en sectores regulados o en organizaciones sujetas a marcos como la Ley de Resiliencia Operativa Digital (DORA) o la Ley de Ciberresiliencia (CRA) de la Unión Europea, que exigen trazabilidad, control de riesgos y cumplimiento de políticas de ciberseguridad en todo el ciclo de vida del software.
Veamos a modo de ejemplo qué significa esto considerando la adopción de arquitecturas nativas para la nube. Cuando trabajamos con aplicaciones contenerizadas, muchas organizaciones facilitan el trabajo de sus equipos mediante registros de imágenes curadas: catálogos internos con componentes comunes, debidamente asegurados (hardening), y versiones sin vulnerabilidades conocidas.
¿Qué ocurre cuando un equipo necesita una imagen que aún no está en ese catálogo, o una versión diferente?
- Si la plataforma es rígida, se bloquea la innovación. Aumentan los costes al necesitar un equipo de plataforma dimensionado para resolver cada pequeña necesidad. Inevitablemente, porque los recursos humanos y económicos son limitados, el equipo de plataforma se convierte en cuello de botella. Y eso conduce a la fricción, entregables de peor calidad y a peor tiempo a mercado. Justo lo contrario de lo que quería resolverse con una plataforma interna. Además, crece el riesgo de que alguien cometa un error grave.
- Si es flexible sin control, se compromete la seguridad. El riesgo es, sencillamente, inasumible.
Una posible solución intermedia es permitir la ejecución de imágenes arbitrarias fuera del catálogo central estableciendo como guardarraíl que no se permita ejecutar imágenes con vulnerabilidades críticas o de severidad alta, así como tener herramientas que activamente validen todas las cargas de trabajo y nos ayuden a mantener los entornos seguros.
Este tipo de enfoque —flexibilidad con responsabilidad— es el que permite que la plataforma otorgue autonomía sin perder el control. Es clave para su adopción, escalado y éxito.
El impacto de las plataformas en la DevEx
En un entorno ideal, desarrollar software debería ser una experiencia enfocada en la lógica de negocio, la resolución de problemas y la entrega de valor. Pero la realidad moderna se parece más a una carrera de obstáculos: herramientas desconectadas, requisitos de infraestructura cambiantes, despliegues complejos, arquitecturas distribuidas, multi-cloud, resiliencia, cumplimiento regulatorio y tecnologías políglotas que multiplican la complejidad de las soluciones en las que trabajamos.
Todo esto desemboca en un concepto cada vez más relevante: la carga cognitiva del desarrollador. Y precisamente una de las grandes promesas de la DevEx es ayudar a reducirla —no escondiendo la complejidad, sino gestionándola—. La plataforma interna tiene aquí un papel fundamental: debe convertirse en el sistema nervioso que conecta todas las piezas y ofrece interfaces consistentes, automatismos reutilizables y experiencias coherentes a través de los distintos canales.
Una plataforma bien diseñada reduce fricción al proporcionar:
- Puntos de entrada unificados: ya sea a través de un portal, una CLI, un SDK o una integración en el IDE, el acceso a capacidades comunes debe ser homogéneo y predecible.
- Abstracciones útiles y componibles: integraciónde servicios, despliegues, monitorización o gestión de secretos convertidos en flujos reutilizables que no requieren entender en detalle cada herramienta individual.
- Documentación contextual e integrada: no es solo tener «la wiki al día», sino proveer explicaciones, ejemplos y uso real desde el mismo flujo de trabajo del desarrollador.
- Automatización con sentido del negocio: no basta con crear pipelines genéricos; necesitamos workflows que entiendan las políticas, estándares y prioridades reales de cada organización.
- Observabilidad orientada al usuario: más allá de logs y métricas, visibilidad sobre el estado y rendimiento de los flujos de trabajo (ya sea de un proyecto, una build, aspectos de calidad, seguridad, etc.), dependencias entre sistemas y feedback del runtime, accesible sin necesidad de ser un SRE.
Pero todo esto solo es posible si dejamos de construir portales para «mostrar cosas» y empezamos a construir plataformas para reducir la complejidad operativa. Lo contrario nos deja desarrolladores frustrados, saltando entre contextos, sin una narrativa clara del flujo de trabajo.
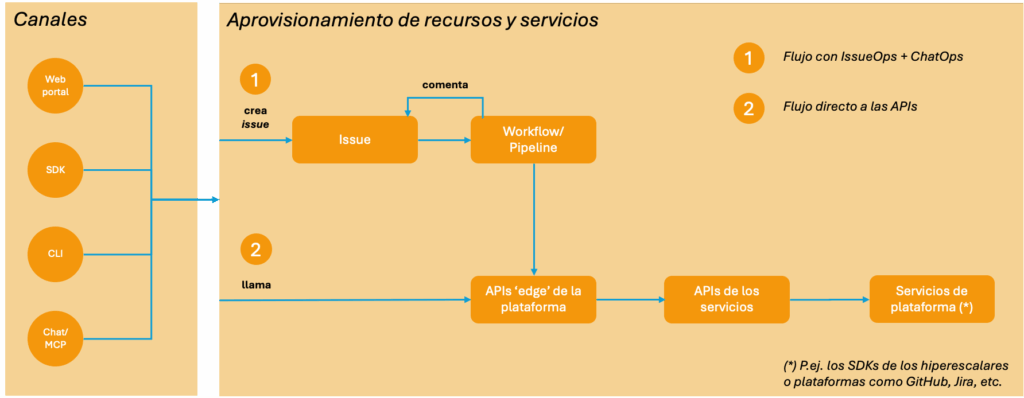
Dos posibles estrategias multi-canal para los servicios de plataforma: una con IssueOps y ChatOps, otra con uso directo de las APIs de la plataforma
Una analogía útil es pensar en una torre de control de aeropuerto: no elimina el tráfico aéreo, ni lo simplifica, pero ofrece a los controladores y pilotos (nuestros equipos de desarrollo) la información precisa y el soporte necesario para tomar decisiones en un entorno que, de por sí, es complejo y crítico. La plataforma debe jugar ese mismo rol: guiar, organizar y proteger sin entorpecer.
Otra analogía poderosa para entender este tipo de evolución en la experiencia del desarrollador es la que distingue entre orquestación y coreografía.
En un modelo de orquestación, como en una orquesta sinfónica, cada miembro del equipo espera instrucciones precisas de un director: cuándo entrar, qué tocar, durante cuánto tiempo. Este enfoque puede funcionar en contextos muy controlados o de pequeña escala, pero se vuelve insostenible a medida que crece la complejidad. La figura central del director se convierte en un cuello de botella, y requiere de mucha dedicación, maestría y tiempo de ensayo, que toda la orquesta funcione armoniosamente sin depender del director más que como recordatorio o para ajustes finos el día del concierto. Este enfoque exige un tiempo a mercado y un nivel de microgestión incompatible con la agilidad moderna.
En cambio, cuando diseñamos una plataforma pensando en reducir la fricción, en dar autonomía y en facilitar la colaboración, nos acercamos conceptualmente más a la coreografía de un gran ballet. Aquí también hay estructura, también hay reglas, pero cada intérprete —la analogía con cada equipo— conoce su papel, domina sus herramientas y entiende el ritmo del conjunto. Algunos momentos requieren interacción estrecha entre bailarines; en otros, el equipo actúa de forma autónoma. Y aun así, cuando se observa el ballet completo, el resultado es armonioso, fluido y bello. No porque alguien dicte cada paso, sino porque la arquitectura de colaboración está bien diseñada y entrenada.
Aplicado al mundo del desarrollo, la coreografía bien diseñada se traduce en una DevEx que reduce toda fricción innecesaria: menos tickets de soporte, menos dependencia de aprobaciones externas, menos tiempo invertido en «recordar cómo se hacen las cosas». Cada equipo puede ejecutar su parte sin sacrificar el todo, confiando en la plataforma como base sólida que guía sin estorbar, que da estructura sin imponer. Esa es la diferencia entre gestionar complejidad… y ser sobrepasado por ella.
Antipatrones comunes en la construcción de portales
Si algo nos ha enseñado la evolución del software es que las malas decisiones también escalan. Y con demasiada frecuencia, los portales internos terminan cayendo en patrones disfuncionales que entorpecen más que ayudan. Estos son algunos de los antipatrones más frecuentes (y peligrosos) que he llegado a «catalogar». Aviso a navegantes: no están exentos de una pizca de humor y exageración dramática:
El portal fachada
Se ve moderno, tiene fuentes tipográficas cuidadas, colores molones y un sistema de diseño muy cuco, pero tras el telón… nada. Enlaza a otras herramientas, pero no orquesta ni automatiza nada. Es como una recepción vacía con muchas puertas cerradas y sin recepcionista. Cuando el desarrollador llega ahí esperando una solución, se encuentra con una colección de PDFs y enlaces rotos.
La interfaz museo
Cada apartado está perfectamente maquetado, pero su contenido se actualizó por última vez durante el proyecto de migración a Kubernetes de 2019. Nadie se atreve a tocarlo por miedo a romper el diseño, y ya solo sirve para que los nuevos desarrolladores pierdan media mañana intentando entender qué parte del portal sigue siendo relevante. Resultado: el portal se convierte en un rincón olvidado de información olvidada.
El catálogo sin servicios
Ofrece un listado detallado de servicios y componentes disponibles… que nadie puede consumir. No hay APIs públicas, ni integración real con el backend, ni flujos de autoservicio. Lo único que puedes hacer es admirar lo que podrías hacer, si tuviera un botón de «solicitar» que funcionara. Al menos, te avisa de que pongas un ticket para que alguien del equipo de infra te ayude… cuando pueda.
La torre de descontrol
Ofrece dashboards, métricas, logs… pero sin correlación ni narrativa. El desarrollador tiene visibilidad, pero no comprensión. Teras de logs pero no puede localizar la parte que es relevante para su problema. Se convierte en un espectador pasivo de datos que no responden a la única pregunta que le importa: ¿qué necesito saber para resolver esto y seguir adelante? Eso sí, la tele con 200 KPIs luce muy bien en las visitas.
El portal político
Su existencia responde más a una necesidad de «check en el roadmap» que a resolver problemas reales. Se construyó rápido, sin conversaciones con usuarios reales, y se lanzó en una demo muy vistosa para el comité ejecutivo. Desde entonces, nadie lo usa, pero nadie se atreve a decirlo o desmontarlo.
Lo preocupante no es que existan estos antipatrones, sino que se perpetúan cuando no tratamos el portal como parte de una plataforma entendida como producto, resolviendo necesidades reales, respaldada por automatismos, APIs funcionales y un compromiso claro con la mejora continua. Los atajos visuales, las métricas de vanidad y la falta de visión holística acaban empujando estos proyectos al «desván digital», donde descansan las iniciativas que alguna vez prometieron mejorar la vida de los equipos… pero no lo hicieron.
Una visión productizada: diseñar pensando como un producto que voy a poner a la venta en el mercado
Tratar la plataforma interna como un producto implica más que tener un backlog y un equipo dedicado. Significa asumir que, como cualquier producto digital, debe medirse, evolucionar y demostrar su impacto. Y para eso, necesitamos conexión absoluta con los usuarios (potenciales y, una vez lanzada, los reales), observabilidad real sobre su uso y sus beneficios, y los mecanismos para mejorar continuamente.
El backlog en una plataforma orientada al desarrollo
Para dotar de las capacidades deseadas a la plataforma el backlog será una combinación de características destinadas a facilitar el acceso y uso con automatización de capacidades de la plataforma que enriquecerán el catálogo de autoservicio. Veamos con más detalle qué tipo de elementos deberán formar parte del backlog:
- UI/UX: Obviamente, nuestros canales deben ser atractivos y fáciles de usar. Esto aplica no solo al portal web sino también a las CLIs. No hay que restar importancia a un buen árbol de comandos intuitivo y fácil de recordar.
- Autoservicio: Desde diseñar un gran catálogo de servicios, estructurado y fácil de utilizar, hasta crear un modelo federado con un marketplace donde distintas partes de la organización puedan contribuir con sus automatizaciones. Dar acceso a servicios de infraestructura, redes, aplicaciones o gestión de licencias de herramientas. Hacer que coexistan sin fricción distintos modelos de coste y aprobaciones: herramientas sin coste, coste por uso, aprobación de nuevos recursos, pero solo si se excede una cuota asignada al equipo, etc. Estos son algunos ejemplos de las preocupaciones que trasladaremos al backlog en este apartado. El autoservicio será consistente en todos los canales. P.ej. crear un repositorio de código tendrá idénticas entradas y resultados si se solicita desde la web como si se lanza desde la CLI.
- Acceso a la base de conocimiento: Mantener actualizada y accesible toda la base de conocimiento de la organización. Desde flujos de documentación como código (p.ej. markdown convertido a web estática) hasta bases de datos vectorizadas para impulsar la búsqueda con contexto y maximizar la utilidad de los asistentes virtuales. Una buena base de conocimiento contendrá elementos variados como arquetipos de soluciones y componentes, ejemplos de código, plantillas reutilizables, guías de buenas prácticas, etc., y aunque no sea responsabilidad del equipo de plataforma aportar todo ese conocimiento, sí que será responsable de que el contenido llegue de forma útil a los equipos de desarrollo.
- Observabilidad: En la plataforma se dará acceso a los equipos a los principales indicadores que miden su progreso de forma consistente con lo que estén haciendo en cada momento: desde la visión de águila en la «home» (¿en qué debo fijarme hoy?), hasta información por componente y entorno. No se trata de duplicar o desplazar a las plataformas de observabilidad sino de conectar a las personas «con un vistazo» a lo que más les interesa, y enlazar a dichas plataformas de observabilidad para la investigación y el seguimiento detallado. Por ejemplo, si un miembro del equipo está revisando el listado de componentes de su aplicación le interesa ver en ese listado los datos de los umbrales de calidad de la última build, y luego tener el acceso rápido a la herramienta que usen para medir y hacer seguimiento de la calidad del código.
- Automatización: Los propios servicios que necesitan los equipos en su día a día y que son accesibles mediante el autoservicio. En modelos de plataformas federadas esta responsabilidad puede estar distribuida entre distintos grupos. P.ej. el grupo de cloud es responsable de automatizar las capacidades que tengan que ver con el uso de la cloud, mientras que el grupo de DevOps es responsable de automatizar las capacidades relacionadas con las herramientas del ciclo de vida. No hay una regla fija y depende en muchos casos del propio tamaño y estructura de la organización, pero en todo caso con un elemento común: la responsabilidad frente a los usuarios de la plataforma de los automatismos que ofrecemos en el catálogo.
Conectando los servicios y capacidad de la plataforma con los usuarios
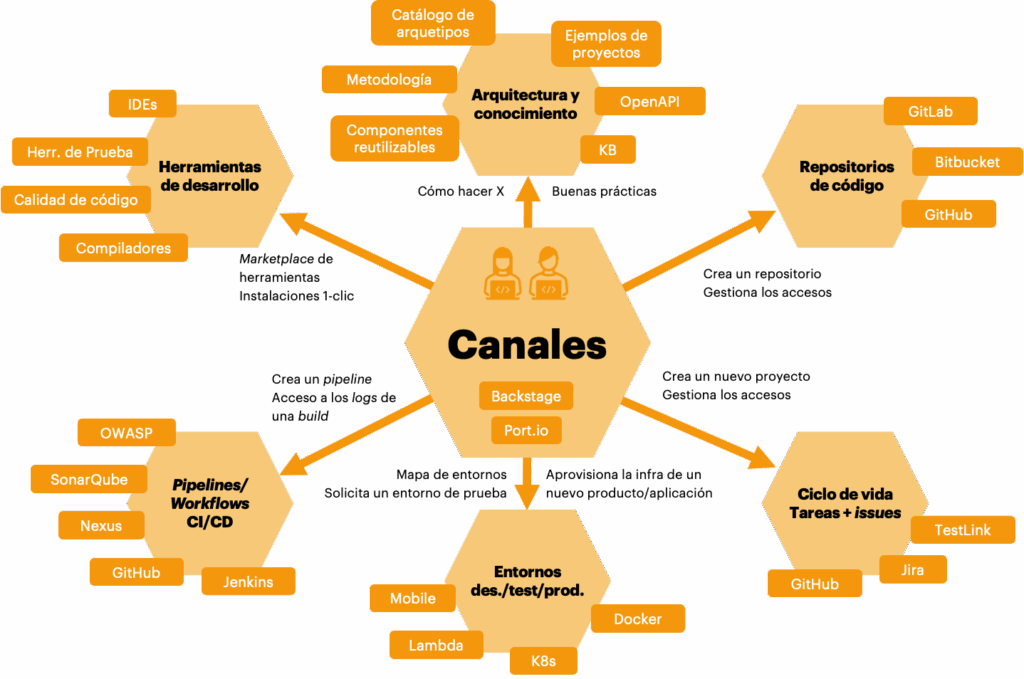
La conexión con los usuarios
La conexión con los usuarios es clave para la adopción. Como ya expliqué brevemente en la Parte 3 sobre DevEx una manera de fomentar la colaboración entre equipos consiste en tener equipos de relación con los desarrolladores (developer relations, developer advocates, o también, equipos de adopción y coaching) que entienden sus necesidades y dificultades.
En el contexto de una plataforma entendida como producto, estos equipos ayudan a que los productos y servicios internos se construyan para que la vida de los ingenieros de software sea tan fácil como sea posible. Escuchan, transmiten el feedback, ayudan a priorizar poniendo el foco en lo que más «duele», conectan con los usuarios clave para mostrarles lo que es nuevo y notable incluso antes de liberarlo al resto de la organización, y acompañan a los equipos de forma continua durante su camino de adopción y uso.
Medir el impacto que tiene la plataforma
Como no basta con tener cercanía, sino que necesitamos medir el impacto que la plataforma tiene en la organización, complementamos lo anterior con indicadores objetivos y encuestas a los usuarios.
Pero cuidado: no se trata de llenar dashboards con decenas de KPIs irrelevantes. Se trata de definir pocas métricas, pero con sentido, que nos ayuden a responder preguntas clave como:
- ¿Está la plataforma reduciendo el tiempo de entrega?
- ¿Está disminuyendo la carga cognitiva de los equipos?
- ¿Está aumentando la autonomía y la satisfacción de los desarrolladores?
- ¿Estamos reduciendo el número de incidencias o el tiempo de recuperación?
Una buena referencia para esto son las métricas DORA, desarrolladas por el equipo de Google Cloud tras años de investigación sobre prácticas de alto rendimiento en ingeniería de software. Estas métricas permiten evaluar tanto la velocidad como la estabilidad del proceso de entrega:
- Deployment frequency: Cuán a menudo se entrega software a producción.
- Lead time for changes: Tiempo desde que se completa un desarrollo hasta que el cambio llega a producción.
- Change failure rate: Porcentaje de despliegues que causan fallos en producción.
- Time to restore service: Tiempo medio para recuperar el servicio tras un fallo.
Además, estas métricas deben complementarse con indicadores tanto cuantitativos como cualitativos, tales como:
- Ratio de autoservicio: cuántas tareas se completan sin intervención externa.
- Carga cognitiva percibida: evaluada mediante encuestas periódicas.
- Feedback de usuarios internos: recogido de forma continua y sistemática.
Estas métricas no solo sirven para evaluar el rendimiento técnico, sino también para medir el valor que la plataforma aporta a la organización. Por ejemplo, si tras adoptar la plataforma el lead time se reduce a la mitad, o si el ratio de autoservicio aumenta significativamente, estamos ante señales claras de que la plataforma está funcionando como producto.
Y aquí entra un elemento clave: la experimentación. Tratar la plataforma como un producto digital implica estar abiertos a probar nuevas ideas, lanzar funcionalidades en beta, recoger feedback real y afinar lo que funciona. Pero también significa tener el coraje de descartar lo que no aporta valor, sin miedo a «matar» features que no cumplen su propósito. La plataforma debe ser un producto vivo, en constante evolución, igual que evolucionan las necesidades de sus usuarios.
Este enfoque experimental no solo mejora la plataforma: fomenta una cultura de aprendizaje continuo. Nos permite validar hipótesis, descubrir patrones de uso inesperados y adaptar la plataforma a medida que la organización crece. Porque si algo define a un buen producto digital, es su capacidad de cambiar con sus usuarios, no contra ellos.
Conclusión
El problema no es que los portales y plataformas internos no funcionen: es que, demasiadas veces, no son realmente productos que mejoran nuestro día a día. Para que cumplan su promesa de mejorar la DevEx, necesitamos:
- Diseñar sobre la base sólida de los «developer journeys», entendiendo que el portal es solo un canal, no el destino, y que la visión debe incluir la plataforma al completo.
- Construir plataformas con mentalidad de producto, con APIs, visión a largo plazo y soporte organizativo real, presupuesto adecuados y equipo humano suficiente.
- Equilibrar estándares con flexibilidad, habilitando la experimentación sin perder seguridad ni cumplimiento.
- Reducir la carga cognitiva, ayudando a los equipos a convivir con entornos cada vez más complejos.
- Medir el impacto de verdad, con métricas claras que conecten la plataforma con el valor que entrega.
Porque si seguimos construyendo portales que informan pero no habilitan, que prescriben pero no escuchan, que miden clicks pero no entregas, estaremos simplemente decorando el desván. Y ese no es el lugar que deseamos para una plataforma que aspira a ser el corazón de nuestra ingeniería.


