La orquestación de agentes de IA es la capa que convierte un LLM en un agente operativo: define decisiones, acciones y protocolos de contención para que los sistemas actúen de forma segura y aprendan con el tiempo. En este artículo repasamos patrones de orquestación de agentes IA: pipeline secuencial, concurrente y supervisor. Para desplegar con seguridad, se deben incluir políticas de reintento, escalado y telemetría.
En la fiebre actual por la Inteligencia Artificial, hemos caído en una trampa conceptual: creer que un Large Language Model (LLM) es, por sí mismo, un agente. No lo es. Un LLM es un motor probabilístico extraordinario, una enciclopedia de patrones lingüísticos capaz de razonar sobre texto. Pero un motor, por potente que sea, no es un vehículo funcional si no tiene chasis, transmisión, ni un sistema de navegación. Un agente de IA no nace cuando escribes un System Prompt en una interfaz de chat. Un agente nace en el vacío de un problema de negocio que requiere autonomía.

Los agentes de IA no nacen del LLM, nacen del problema
Un agente de IA no es simplemente un gran modelo de lenguaje (LLM) con acceso a herramientas: es una solución diseñada para resolver un problema concreto. Antes de escribir prompts o elegir frameworks, hay que diseñar el comportamiento: qué decisiones tomará el agente, qué acciones ejecutará y bajo qué condiciones. El éxito no lo define el modelo, sino cómo se orquesta todo lo que ocurre entre la entrada y el resultado final.
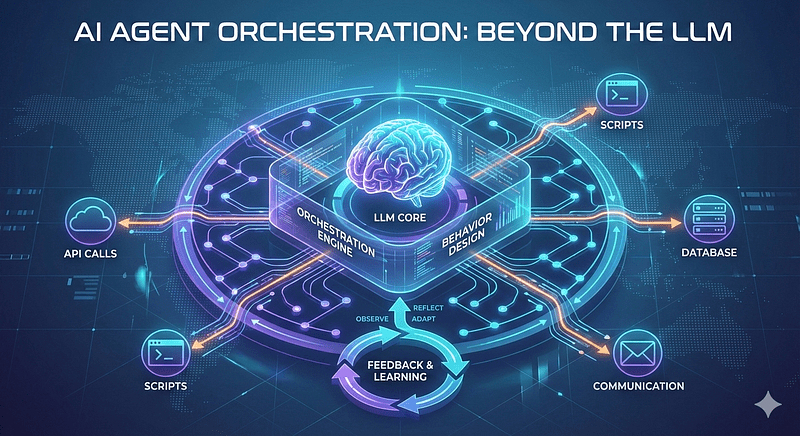
El LLM entiende y genera salidas; la orquestación controla cuándo actuar, cuándo parar, qué sistemas tocar y qué aprender para la próxima vez. Sin orquestación robusta, los agentes degeneran en automatizaciones frágiles que se estancan en producción.
Orquestación de agentes IA: patrones y arquitectura
Antes de elegir entre LangChain, CrewAI o AutoGen, debemos diseñar la psicología operativa del agente. La pregunta no es “¿qué quiero que me diga?”, sino “¿qué decisiones debe tomar cuando yo no esté mirando?”.
El diseño de comportamiento se basa en tres pilares fundamentales:
- Capacidad de juicio (decisiones): ¿bajo qué lógica el agente decide que ha terminado una tarea? ¿cómo prioriza entre dos herramientas en conflicto? ¿qué elegir cuando hay múltiples caminos?, por ejemplo: elegir extracción vs. clasificación.
- Ejecución de impacto (acciones): no hablamos de generar texto, sino de disparar efectos secundarios en el mundo real: API calls, consultas a bases de datos, actualizaciones de CRM, envío de correos, ejecución de scripts, etc.
- Protocolos de contención (condiciones): los límites éticos y técnicos. ¿Cuándo debe el agente detenerse y pedir supervisión humana (Human-in-the-loop)?. Reglas que activan o detienen acciones (umbral de confianza, límites de tiempo, señales de error).
La anatomía de la orquestación de agentes IA
Si el LLM es el cerebro, la orquestación es el sistema nervioso. La orquestación es lo que gestiona lo que ocurre “en el medio”, entre la entrada del usuario y la ejecución final.

La verdadera orquestación implementa ciclos de ReAct (Reason + Act). El agente no solo “hace”; primero piensa qué va a hacer, observa el resultado de su acción y ajusta su siguiente paso basándose en esa observación. Sin esto, solo tienes un script glorificado que se rompe ante la mínima variación del entorno.

Ciclo de aprendizaje en la orquestación de agentes IA
Las automatizaciones tradicionales son frágiles porque son ciegas a su propio rendimiento. Un agente de IA moderno debe poseer una capa de Metacognición.
¿Qué aprendió el agente de esta ejecución?
- Si la herramienta X devolvió un error de tiempo de espera, el agente orquestado debe ajustar su política de reintentos o buscar una ruta alternativa.
- Si el resultado final no satisfizo la condición de éxito definida en el diseño, el agente debe ser capaz de realizar un “self-reflection” (auto-reflexión) para identificar en qué punto de la cadena de pensamiento falló el razonamiento.
Comparativa rápida de patrones de orquestación

Ejemplo 1: Orquestador mínimo para un agente (single‑agent, pipeline)
- Descripción: pipeline secuencial: obtener documento → extraer datos → validar → persistir. Código funcional que simula llamadas al LLM y a herramientas; fácil de adaptar a un LLM real.
# orchestrator_pipeline.py
import time
from typing import Dict, Any
class ToolError(Exception):
pass
class LLMClient:
def generate(self, prompt: str) -> str:
# Simulación: en producción, aquí va la llamada al LLM
return f"RESPUESTA_SIMULADA para: {prompt}"
class Storage:
def save(self, record: Dict[str, Any]) -> None:
print("Guardado:", record)
class Orchestrator:
def __init__(self, llm: LLMClient, storage: Storage):
self.llm = llm
self.storage = storage
def run(self, document: str) -> Dict[str, Any]:
# Paso 1: comprensión
summary = self.llm.generate(f"Resume: {document}")
# Paso 2: extracción estructurada
extracted = self.llm.generate(f"Extrae campos clave de: {document}")
# Paso 3: validación simple
if "ERROR" in extracted:
raise ToolError("Extracción fallida")
# Paso 4: persistencia
record = {"summary": summary, "extracted": extracted, "ts": time.time()}
self.storage.save(record)
return record
if __name__ == "__main__":
llm = LLMClient()
storage = Storage()
orch = Orchestrator(llm, storage)
doc = "Factura #123: total 450. Fecha 2026-02-01"
result = orch.run(doc)
print("Resultado final:", result)Puntos clave:
- Control de flujo explícito entre pasos.
- Errores se elevan y pueden capturarse en un supervisor externo.
- Fácil de instrumentar con métricas y logs.
Ejemplo 2 — Orquestación concurrente y multi‑agente (ejecución paralela)
- Descripción: dividir trabajo en subtareas independientes, ejemplo: extracción de secciones de un documento grande y ejecutar en paralelo; luego agregar resultados y validar.
# orchestrator_concurrent.py
import asyncio
from typing import List
class LLMClientAsync:
async def generate(self, prompt: str) -> str:
await asyncio.sleep(0.2) # simula latencia
return f"RESP_{prompt[:20]}"
async def worker(llm: LLMClientAsync, chunk: str) -> str:
return await llm.generate(f"Extrae: {chunk}")
async def orchestrate(document_chunks: List[str]):
llm = LLMClientAsync()
tasks = [asyncio.create_task(worker(llm, c)) for c in document_chunks]
results = await asyncio.gather(*tasks, return_exceptions=True)
# manejo simple de errores
aggregated = []
for r in results:
if isinstance(r, Exception):
aggregated.append("ERROR")
else:
aggregated.append(r)
# validación agregada
if any("ERROR" in a for a in aggregated):
raise RuntimeError("Falló alguna subtarea")
return aggregated
if __name__ == "__main__":
chunks = ["Sección A", "Sección B", "Sección C"]
out = asyncio.run(orchestrate(chunks))
print("Agregado:", out)Puntos clave:
- Throughput mejorado; cuidado con límites de concurrencia y coste.
- Necesitas coordinación para reintentos y consistencia.

Ejemplo 3 — Orquestador con supervisor, control de políticas y aprendizaje básico
- Descripción: patrón supervisor que decide cuándo reintentar, cuándo escalar y registra experiencias para aprendizaje offline.
# orchestrator_supervisor.py
import random
import json
from typing import Dict
class Supervisor:
def __init__(self, max_retries=2, confidence_threshold=0.7):
self.max_retries = max_retries
self.confidence_threshold = confidence_threshold
self.experience_log = "experience.log"
def decide(self, output: Dict[str, float]) -> str:
# output contiene {'result': str, 'confidence': float}
if output['confidence'] >= self.confidence_threshold:
return "accept"
elif output['confidence'] < 0.3:
return "escalate"
else:
return "retry"
def record_experience(self, context: Dict, outcome: Dict):
entry = {"context": context, "outcome": outcome}
with open(self.experience_log, "a") as f:
f.write(json.dumps(entry) + "\n")
class MockAgent:
def infer(self, prompt: str) -> Dict:
# Simula variabilidad de confianza
conf = random.random()
return {"result": f"Salida para {prompt}", "confidence": conf}
def run_task(supervisor: Supervisor, agent: MockAgent, prompt: str):
attempts = 0
context = {"prompt": prompt}
while attempts <= supervisor.max_retries:
out = agent.infer(prompt)
decision = supervisor.decide(out)
supervisor.record_experience(context, {"attempt": attempts, "out": out, "decision": decision})
if decision == "accept":
return out
elif decision == "escalate":
# Escalación: por ejemplo, notificar humano o fallback determinista
return {"result": "ESCALATED_TO_HUMAN", "confidence": out['confidence']}
else:
attempts += 1
return {"result": "FAILED_AFTER_RETRIES", "confidence": 0.0}
if __name__ == "__main__":
sup = Supervisor()
agent = MockAgent()
res = run_task(sup, agent, "Extrae entidad X")
print("Resultado:", res)Lenguaje del código: HTML, XML (xml)Puntos clave:
- Supervisor aplica políticas (umbral de confianza, reintentos, escalado).
- Registro de experiencias permite análisis offline y reentrenamiento o ajuste de reglas.
- En producción, el registro alimenta pipelines de mejora continua.
Descubre agent-orchestration-playbook, un repositorio práctico con patrones y ejemplos para diseñar agentes de IA robustos: adaptadores de LLM, orquestadores, políticas de supervisión y ejemplos ejecutables (ingestión de facturas, triage de soporte y revisión de código). Ideal para aprender cómo convertir un LLM en un agente real mediante orquestación, telemetría y buenas prácticas.
Orquestación en producción de agentes IA
Retos comunes:
- Context drift: modelos pierden precisión con datos nuevos.
- Costos y latencia: llamadas LLM frecuentes son caras; la orquestación debe optimizar cuándo y cuánto invocar.
- Fallas silenciosas: agentes que “fallan” sin alertas; la telemetría es crítica.
- Escalabilidad: patrones que funcionan en pruebas pueden colapsar a escala sin coordinación.
Buenas prácticas:
- Instrumentar cada decisión y acción (trazas, métricas, logs).
- Políticas explícitas de reintento, backoff y escalado.
- Simulaciones y pruebas de estrés antes de desplegar.
- Separación de responsabilidades: agentes especializados + orquestador que coordina.
- Feedback loop: registrar errores y resultados para reentrenamiento o ajuste de reglas.
El Cambio de Paradigma
Un agente de IA no nace del LLM, nace del problema y del diseño del comportamiento. El LLM es una pieza poderosa, pero la orquestación; decidir cuándo actuar, cuándo parar, qué sistemas tocar y qué aprender, es lo que convierte una automatización frágil en un agente robusto y adaptable. Sin orquestación no hay agentes; solo cadenas que se rompen con el tiempo. Para sistemas complejos, se deben adoptar patrones de orquestación adecuados (secuencial, concurrente, multi‑agente, supervisor) y tratar la orquestación como la capa crítica de producción.
Construir agentes no es un ejercicio de literatura (prompts); es un ejercicio de arquitectura de sistemas. El modelo (GPT-4, Claude, Gemini) es simplemente un “commodity” intercambiable. Lo que realmente tiene valor es la estructura lógica que envuelve a ese modelo: los guardrails, la gestión de estado y la capacidad de interactuar con sistemas externos de forma coherente.
Si quieres un agente que perdure, deja de obsesionarte con el modelo y empieza a obsesionarte con la orquestación. Ahí es donde reside la inteligencia real.

