
The cost and complexity of software maintenance are reducing team productivity to zero when the need is exactly the opposite – scaling up. Domain-specific languages offer a different approach to model definition, and to the reverse engineering of legacy code, promising to solve this conundrum. ComMA, developed and used by Philips Healthcare in conjunction with TNO/ESI, is an example of such a DSL
Software development doesn’t scale
Software is expensive to create. According to Dirk Jan Swagerman, Head of Development Digital and Computational Pathology at Philips, “each 5K to 10K lines of code roughly takes one full-time employee to create. An average iPhone app easily takes 10-50K lines of code, a modern car contains 100M+ lines of code.”
Machine learning algorithms have increased the complexity of the overall software, but the basic rules remain. The lifecycle of a codebase needs a lot of developers; at the same time, it introduces heavy constraints blocking the overall codebase resilience.
Software is expensive to maintain
A legacy software codebase that is larger than required is eating away at innovation speed. That’s why every development team needs a code-down target.
This is an important target to all developers, in all stages of their working life: as a junior developer, your goal is developing code; as a mid-level developer, your goal is removing code; as a senior developer, your goal is preventing your company from writing code.
One of the most common approaches for managing today’s codebase complexity is to use many different languages and environments to work across different processes of the overall system. “By using a large choice of programming languages“, explains Daan van der Munnik, Technical Department Manager Software at Philips Healthcare, “we have been conveying our ideas to computers, which has turned out to be a very laborious task, involving large teams and millions of lines of code for complex software systems. All this code will become legacy code in a short time. The same will soon happen to the execution hardware. Maintenance will exhaust most resources.”
Increasingly, we come to the conclusion that this traditional process of software development and execution does not scale. Put bluntly, if a team creates new code each year, but is also required to maintain the code it created in previous years, software management productivity is subject to exponential decay: all software teams move towards zero productivity.
What can be done about it? To keep up with this negative rate we need a higher abstraction level to convey our ideas.
The answer to this dilemma lies in model-driven engineering, based on domain-specific languages (DSL). DSLs have higher initial productivity and their maintainability is higher by design. With knowledge explicitly modeled in a DSL, code can be generated towards operating systems, hardware, languages, tools and even third-party libraries that do not exist yet.
Models are a great form of abstraction.
Domain-Specific Languages are the answer
The model is at the center of a good solution to scale up software productivity in both updated and old forms. Daan van der Munnik proposes a bi-directional graph to guide the development of detailed code. The three considered elements are the model, the specific (or domain) knowledge, and the final, detailed code. The code is to be written in the appropriate DSL.
When the problem domain is well known, its related domain knowledge can be used within the model to produce the detailed code:
Model + Domain-Knowledge → Detailed-code
This is the direction of developing new code. But when we are coping with legacy code, we can revert the direction of the equation to transform legacy code in fresh new code:
Detailed-code → Model + Domain-Knowledge
Using Domain-Specific Languages to create abstractions in the context of a specific problem domain will help us convey our ideas to computers in a scalable way.
Guided by a reference design, a component’s code is analyzed and a legacy model is extracted that captures the component’s functionality in a form close to its original structure. The legacy model is then unfolded, creating a flat model that eliminates design decisions by focusing on functionality in terms of external interfaces. Analyzing the variation points of the flat model yields a redesigned model and fresh domain abstractions to be used in the new design of the component.
ComMA is a DSL
Most of the common problems in writing code that’s efficient and maintainable can be found easily in software interfaces. Using a modeling DSL approach is a good solution.
Software interfaces are like contracts and sport the same problems. The clauses are always described in most cases, often even in deep detail, sometimes including the execution order. They normally fail on their timing behavior. Correct timing management is crucial during all lifecycle phases, including development, deployment, integration, monitoring, and reverse engineering. The timing description needs to be easy to modify, should a change become necessary.
ComMA is an ecosystem supporting model-based component engineering developed by Philips Healthcare and TNO-ESI. Component Modelling and Analysis, which provides ComMA with its acronym, helps to nail down software form/fit/function with a previously impossible rigor, during the lifecycle of a high-tech system platform. Future work includes enriching the language with data integrity checks and full system-level simulations.
It lowers development costs since the first implementation; more savings will come in time, managing the platform lifecycle.
Interface, dialogue, and constraints
Looking at its structure, ComMA is a combination of domain-specific languages (DSLs) in which the interface between a server and its clients can be specified by three main ingredients: the interface signature, the allowed client-server interactions, and the time and data constraints.
The interface signature consists of groups of commands, signals, and asynchronous notifications. Commands are synchronous: the caller is blocked until a reply is received, whereas signals are asynchronous. State machines are used to describe the allowed client-server interactions, such as the allowed order of client calls and the allowed notifications from the server in any state. Finally, ComMA enables the definition of constraints such as the allowed response time, notification periodicity and data relationships between the parameters of subsequent calls.
Let’s take a look at a typical constraints configuration.
A few examples of timing constraints. Data constraints can be similarly specified, such as for the maximal distance the table is allowed to move after detecting the absence of move requests.
ComMA modeling
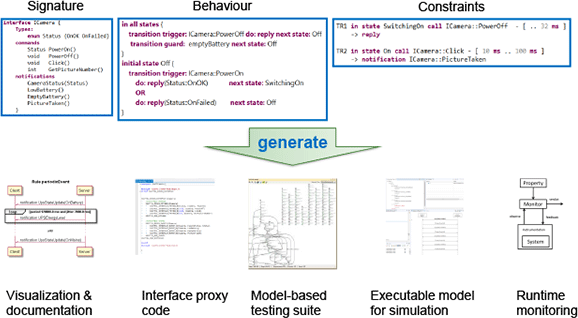
A number of artifacts can be generated from a ComMA model.
Several artifacts can be generated from a ComMA model. ComMA produces PlantUML files that visualize state machines. Constraints can be intuitively represented as annotated UML sequence diagrams.
To accelerate implementation, ComMA interface signatures can be transformed into interface proxy code (C++ and C#). This code can be incorporated into the company-specific platform for transparent component deployment. Based on the state machines, models can be generated for various model-based testing tools, enabling test generation and online testing.
For simulation purposes, state machine models are transformed into Poosl programs (Parallel Object-Oriented Specification Language). The trace of the interaction between clients and server allows monitoring and is also used to obtain statistical data. This can be obtained by logging or sniffing the events during system execution, generating errors and warnings.
Many sections of these phases can be partially automated.
Conclusions
A structured approach to domain-specific languages allows for a scale-up of the execution efficiency. This approach, as described in Philips Healthcare’s ComMA, appears to be a good way to loosen some uncertainties in software writing and maintenance, as well as in hardware upgrades and could provide a framework for others to follow in future.


