
La Public Preview de SQL Server 2025 ya está disponible y no es para nada una actualización menor. Esta nueva versión marca un hito significativo al integrar capacidades de Inteligencia Artificial (IA) directamente en su motor de base de datos, transformando la forma en que interactuamos con nuestros datos. Lejos de ser un simple plugin o una funcionalidad de análisis superficial, esta integración permite realizar búsquedas semánticas rápidas y precisas utilizando modelos de lenguaje, embeddings y vectores, todo sin salir de nuestro entorno habitual como SQL Server Management Studio. Esto es especialmente relevante porque los datos no necesitan salir del servidor, garantizando así la seguridad y el rendimiento.
La teoría detrás de la magia: Vectores, Embeddings y Cosenos
Para entender cómo la IA logra estas búsquedas semánticas, es fundamental comprender algunos conceptos clave:

Lo primero y principal, la IA no entiende palabras, entiende números: Aunque parezca que la IA «lee» o «comprende» texto, internamente trabaja con representaciones matemáticas. La IA opera con vectores, probabilidades y operaciones matemáticas de números.
Los vectores son una lista ordenada de números que representa el «significado» de algo. Generalmente, estos vectores son de 1536 dimensiones (estándar actual de la industria) para capturar la complejidad semántica. Por ejemplo, características como si un vehículo flota, tiene alas, o si un humano habla, pueden ser representadas numéricamente en un vector.
Hablamos de embeddings y no vectores cuando un modelo de lenguaje toma una frase como «bicicleta para descenso de montaña» y genera un vector que encapsula su significado, ese vector es un embedding. Un embedding es un vector al que se le ha asignado un valor semántico. Es decir, es la representación numérica de un concepto o texto, conservando su significado.
Similitud de Coseno
La magia ocurre al comparar embeddings. Como conjuntos de números podemos pintarlos como un punto en un lugar en el espacio y trazar hasta ese punto una línea desde el eje central de nuestro plano. Esto nos permite realizar comparaciones. Cuanto más cercano es el ángulo entre dos vectores, más parecido es su significado.
Esta comparación se realiza mediante el cálculo de la similitud de coseno, que es una operación de álgebra lineal basada en el producto escalar y las magnitudes de los vectores. La fórmula es:
Similitud = cos(θ) = (A·B) / (||A|| * ||B||).
La distancia, por otro lado, es simplemente 1 – similitud; cuanto más cercana a cero, más similares son los conceptos.

Esta es la teoría pero todos tranquilos que este cálculo lo realiza el motor de SQL Server, liberándonos de la tarea manual.
¿Por qué búsquedas semánticas y no el «LIKE» de siempre?
En SQL Server 2025 el verdadero factor diferenciador de esta funcionalidad son las búsquedas semánticas. A diferencia de una búsqueda con LIKE o índices de texto completo (Full Text Indexes), los embeddings representan el significado de las palabras. Esto significa que aspectos como sinónimos o incluso el idioma de la búsqueda dejan de ser un impedimento.
Por ejemplo, si las descripciones de tus productos están en inglés, francés o chino, y tu realizas una búsqueda en español como «Quiero una bicicleta para hacer descenso de montaña», el modelo entenderá el significado y devolverá resultados coherentes, incluso si la descripción es «bike for downhill mountain racing». Esto se debe a que el modelo entiende el significado, no la forma o la sintaxis.
Implementación paso a paso: Integrando IA en SQL Server 2025
Para empezar a realizar búsquedas semánticas en SQL Server 2025, yo he usado la base de datos AdventureWorks.
Requisitos previos
Por supuesto, necesitaremos SQL Server 2025, que actualmente está en versión preview.
Si ya estamos en SQL Server 2025 lo primero que debemos habilitar las llamadas a destinos REST API para consultar los modelos LLM. Para ello ejecutaremos:
sp_configure 'external scripts enabled', 1; RECONFIGURE;.Lenguaje del código: JavaScript (javascript)Dado que a día de hoy SQL Server 2025 es una versión preview, vamos a tener que habilitar unas trazas específicas para la búsqueda de vectores por índices. Una vez que el producto esté en disponibilidad general, esto no será necesario. De momento vamos a ejecutar:
DBCC TRACEON(466, 474, 13981, -1)Configurar credenciales
Una vez que lo tenemos preparado vamos a necesitar crear y almacenar una credencial para conectarnos al modelo de generación de embeddings. Para poder almacenar esa credencial de forma segura antes de hacer nada tendremos que crear una clave maestra de encriptación:
CREATE MASTER KEY ENCRYPTION BY PASSWORD = 'TuContraseñaSegura';.Lenguaje del código: JavaScript (javascript)Con la clave de encriptación creada ya podemos crear la credencial para el servicio de IA: Es necesario configurar una credencial que apunte a tu endpoint de Azure OpenAI (o cualquier otro modelo de IA que admita llamadas API, como NVIDIA o LLaMA). Esto requiere obtener el endpoint y la API Key de tu recurso de Azure OpenAI.
create database scoped credential [https://NombreEndpoint.openai.azure.com] -- Nombre de la credencial (Endpoint Azure OpenAI)
with identity = 'HTTPEndpointHeaders', secret = '{"api-key": "*****************************************"}'; -- API KEY Open AI
GOLenguaje del código: JavaScript (javascript)Generar embeddings
Ahora que ya tenemos creada nuestra credencial para acceder a un LLM (en mi caso Azure Open AI pero puede ser otro) ya podemos empezar a hacer peticiones. Lo primero que vamos a hacer va a ser crear un procedimiento almacenado para generar los embeddings. Este procedimiento recibirá un texto (ej., la descripción de un producto) y lo enviará al modelo de IA. El modelo generará un vector con significado semántico (el embedding) de 1536 posiciones que encapsula el significado semántico del texto.
El procedimiento encapsulará la llamada REST al modelo, pasando el texto como payload en formato JSON y recibiendo el embedding como respuesta. Os dejo mi código de este SP como ejemplo. Veréis que además de lo estrictamente necesario tiene una capa de control de errores.
create or alter procedure [get_embedding]
@inputText nvarchar(max),
@embedding vector(1536) output
as
begin try
declare @retval int;
declare @payload nvarchar(max) = json_object('input': @inputText);
declare @response nvarchar(max)
declare @url nvarchar(1000) = 'https://NombreEndpoint.openai.azure.com/openai/deployments/text-embedding-ada-002/embeddings?api-version=2023-05-15' /* URL modelo (Azure AI Foundry ADA 2) */
exec @retval = sp_invoke_external_rest_endpoint
@url = @url,
@method = 'POST',
@credential = [https://NombreEndpoint.openai.azure.com], /* Nombre de la credencial (Endpoint Azure OpenAI)*/
@payload = @payload,
@response = @response output;
end try
begin catch
select
'SQL' as error_source,
error_number() as error_code,
error_message() as error_message
return;
end catch
if (@retval != 0) begin
select
'OPENAI' as error_source,
json_value(@response, '$.result.error.code') as error_code,
json_value(@response, '$.result.error.message') as error_message,
@response as error_response
return;
end;
set @embedding = cast(json_query(@response, '$.result.data[0].embedding') as vector(1536))
return @retval
GOLenguaje del código: PHP (php)Almacenar los embeddings de tus datos
Cuando generemos estos embeddings, es muy importante guardarlos en una tabla separada de tus datos originales. Esto mejora el rendimiento y mantiene la base de datos más limpia, ya que los embeddings son valores muy largos.
El siguiente script, ya con datos propios de AdventureWorks, crea una tabla y la carga con los datos de los artículos que vamos a usar junto con los embeddings:
USE AdventureWorks;
GO
-- Crea nueva tabla para embeddings de productos
DROP TABLE IF EXISTS Production.ProductDescriptionEmbeddings;
GO
CREATE TABLE Production.ProductDescriptionEmbeddings
(
ProductDescEmbeddingID INT IDENTITY NOT NULL PRIMARY KEY CLUSTERED,
ProductID INT NOT NULL,
ProductDescriptionID INT NOT NULL,
ProductModelID INT NOT NULL,
CultureID nchar(6) NOT NULL,
Embedding vector(1536)
);
-- Copiar filas relevantes de productos
-- Solo copiamos productos que tengan datos de ProductModels
INSERT INTO Production.ProductDescriptionEmbeddings
SELECT p.ProductID, pmpdc.ProductDescriptionID, pmpdc.ProductModelID, pmpdc.CultureID, NULL
FROM Production.ProductModelProductDescriptionCulture pmpdc
JOIN Production.Product p
ON pmpdc.ProductModelID = p.ProductModelID
ORDER BY p.ProductID;
GOLenguaje del código: PHP (php)Ahora, para crear los embeddings vamos a ejecutar un proceso que itere sobre la tabla de tus productos (o los datos que desees buscar semánticamente) y, para cada descripción, llama al procedimiento almacenado GetEmbedding para generar su embedding.
USE [AdventureWorks];
GO
DECLARE @ProductName NVARCHAR(50);
DECLARE @ProductModelName NVARCHAR(50);
DECLARE @Description NVARCHAR(400);
DECLARE @ProductID INT;
DECLARE @ProductModelID INT;
DECLARE @ProductDescriptionID INT;
DECLARE @CultureID NCHAR(6);
DECLARE @vector vector(1536);
DECLARE @text nvarchar(max);
DECLARE @i INT = 1;
BEGIN TRAN
-- Proceso fila a fila
DECLARE ProductCursor CURSOR FOR
SELECT p.Name, pm.Name, pd.Description, pde.ProductID, pde.ProductModelID, pde.ProductDescriptionID, pde.CultureID
FROM Production.ProductDescription pd
JOIN Production.ProductDescriptionEmbeddings pde
ON pd.ProductDescriptionID = pde.ProductDescriptionID
JOIN Production.Product p
ON p.ProductID = pde.ProductID
JOIN Production.ProductModel pm
ON pm.ProductModelID = p.ProductModelID
OPEN ProductCursor;
FETCH NEXT FROM ProductCursor INTO @ProductName, @ProductModelName, @Description, @ProductID, @ProductModelID, @ProductDescriptionID, @CultureID;
WHILE @@FETCH_STATUS = 0
BEGIN
SET @text = (SELECT 'Name: ' + @ProductName + ', Description: ' + @Description);
EXEC get_embedding @text, @vector output;
UPDATE Production.ProductDescriptionEmbeddings SET Embedding = @vector
WHERE ProductID = @ProductID
AND ProductModelID = @ProductModelID
AND ProductDescriptionID = @ProductDescriptionID
AND CultureID = @CultureID;
FETCH NEXT FROM ProductCursor INTO @ProductName, @ProductModelName, @Description, @ProductID, @ProductModelID, @ProductDescriptionID, @CultureID;
PRINT cast(@i as varchar(5)) + ' || ' + cast(@vector as varchar(max));
if @i % 50 = 0
BEGIN
WAITFOR DELAY '00:1:00'; /* Esperar 1 minuto, cada 50 items (limite de OpenAI API)*/
END
SET @i = @i + 1;
END
COMMIT TRAN;
CLOSE ProductCursor;
DEALLOCATE ProductCursor;Lenguaje del código: PHP (php)Consideraciones de rendimiento: La generación inicial de embeddings puede tomar tiempo. Esto se debe a que es recomendable esperar entre lotes de llamadas para no exceder los límites de tokens por minuto del servicio de IA. Esta generación es una operación que usualmente se realiza una vez, o para los nuevos registros.
Crear el procedimiento almacenado para búsquedas semánticas
Ya con los embeddings de nuestros productos generados es el momento de preparar el procedimiento que recibirá la petición del usuario y hará la búsqueda. Este procedimiento recibirá una frase de búsqueda (el prompt) del usuario, generará el embedding de esa frase y lo comparará con lo que hay almacenado en la tabla.
Primero, llamará al mismo procedimiento GetEmbedding (el que hemos creado antes) para generar el embedding de la frase de búsqueda del usuario. Es fundamental usar el mismo modelo que generó los embeddings de tus productos para asegurar resultados correctos.
Luego, utilizará la nueva función vector_distance de SQL Server 2025 para comparar el embedding de la frase de búsqueda con todos los embeddings almacenados en la tabla de embeddings de tus productos. Esta función calcula la similitud de coseno.
Los resultados se ordenarán por similitud (de mayor a menor) para devolver los productos más relevantes.
Opcionalmente, he añadido más filtros adicionales, como el stock mínimo de un producto pero puedes ponerle cualquier otro con el objetivo de limitar primero la cantidad de embeddings de tus productos que se van a comparar con el embedding de la búsqueda del usuario. Esto es lo que se llama un búsqueda híbrida.
CREATE OR ALTER procedure [find_relevant_products]
@prompt nvarchar(max), -- Entrada prompt
@stock smallint = 500, -- Filtro Stock, el usuario puede cambiarlo
@top int = 10, -- Top 10 productos, el usuario puede cambiarlo
@min_similarity decimal(19,16) = 0.3 -- Nivel minimo similitud, el usuario puede cambiarlo
as
if (@prompt is null) return;
declare @retval int, @vector vector(1536);
exec @retval = get_embedding @prompt, @vector output;
if (@retval != 0) return;
-- Usa la funcion vector_distance para localizar productos
-- Busqueda híbrida stock >= @stock
with cteSimilarEmbeddings as
(
select
top(@top)
pde.ProductID, pde.ProductModelID, pde.ProductDescriptionID, pde.CultureID,
vector_distance('cosine', pde.[Embedding], @vector) as distance
from
Production.ProductDescriptionEmbeddings pde
order by
distance
)
select p.Name as ProductName, pd.Description as ProductDescription, p.SafetyStockLevel as StockQuantity
from cteSimilarEmbeddings se
inner join Production.Product p
on p.ProductID = se.ProductID
inner join Production.ProductDescription pd
on pd.ProductDescriptionID = se.ProductDescriptionID
where (1-distance) > @min_similarity and p.SafetyStockLevel >= @stock
order by distance asc;
GOLenguaje del código: JavaScript (javascript)Uso y resultados
Ahora sí, ya tenemos todo listo para empezar a hacer nuestras búsquedas semánticas en SQL Server como si fuera un RAG más que una base de datos relacional. Simplemente tendremos que llamar a este último procedimiento almacenado que acabamos de crear pasándole nuestra búsqueda y los filtros extra y nos devolverá los productos que más se adecuen a lo que necesitamos. Veamos unos ejemplos, con distintas búsquedas en distintos idiomas:
EXEC find_relevant_products
@prompt = N'Show me the best products for riding on rough ground',
@stock = 100,
@top = 20;
GO
EXEC find_relevant_products
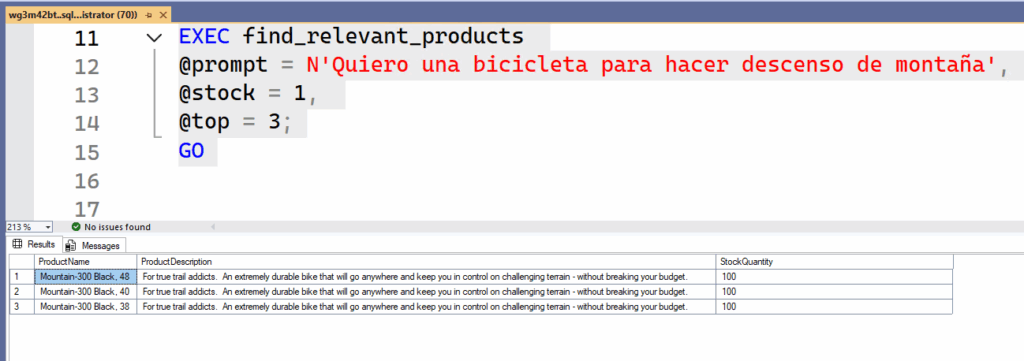
@prompt = N'Quiero una bicicleta para hacer descenso de montaña',
@stock = 100,
@top = 20;
GO
EXEC find_relevant_products
@prompt = N'Quiero una bicicleta para participar en carreras de carretera',
@stock = 100,
@top = 20;
GOLenguaje del código: CSS (css)

Aplicaciones reales más allá de la demo
Aunque comparar descripciones de productos es una «demo fácil», las aplicaciones de las búsquedas semánticas son muchísimas y muy valiosas. Por ejemplo, lo puedes utilizar para ofrecer recomendación de artículos y sugerir productos relacionados en una tienda en línea. Otra opción interesante puede ser el análisis de feedback de clientes y usar la búsqueda semántica para clasificar sentimientos, detectar patrones de insatisfacción o anticipar problemas a partir de comentarios de texto en la web. Incluso podrías hacer análisis de transcripciones de llamadas de soporte técnico para identificar temas recurrentes o emociones.
En resumen, esta funcionalidad es ideal para la automatización de búsquedas complejas y resolver consultas que hasta ahora requerían intervención humana. Todo esto se logra directamente desde SQL Server, sin necesidad de montar pipelines complejas o exportar datos a otros sistemas. La velocidad es impresionante, con resultados en milisegundos, ya que el cálculo del embedding de la petición y su comparación se realizan muy rápidamente.
Conclusión
SQL Server 2025 ha trascendido su rol de motor relacional para convertirse en un intérprete semántico, incluso podríamos hablar de un RAG. Esta es una funcionalidad real, integrada, segura y rapidísima que cambia fundamentalmente la forma en que interactuamos con los datos. La capacidad de «chatear» con tu base de datos de manera natural y obtener resultados basados en el significado abre puertas a soluciones que antes eran inviables o extremadamente complejas. La IA en SQL Server ha llegado para quedarse y transformará las operaciones de base de datos.



