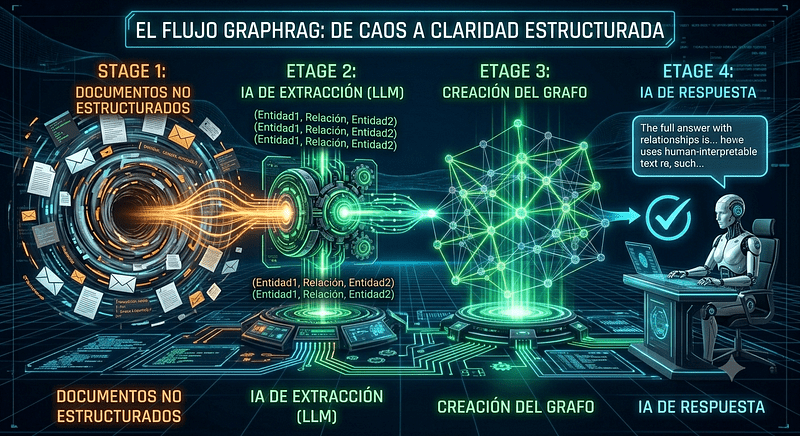
Es hora de evolucionar. Hablemos de GraphRAG y como transforma la búsqueda documental: GraphRAG usa grafos de conocimiento para conectar entidades y ofrecer razonamiento multisalto, trazabilidad y menos alucinaciones que el RAG vectorial. GraphRAG es el salto cuántico donde la IA deja de ser un simple bibliotecario rápido y se convierte en un detective maestro. GraphRAG convierte la búsqueda de documentos en navegación por relaciones: en lugar de devolver fragmentos aislados, construye y recorre un grafo de conocimiento para responder preguntas complejas y multisalto con mayor precisión y trazabilidad.
¿Alguna vez le has hecho una pregunta compleja a una Inteligencia Artificial sobre una base de datos gigante y sientes que te responde con piezas de un rompecabezas que no encajan? Exacto. El RAG tradicional es brillante, pero a veces actúa como un “Ctrl+F” con esteroides: encuentra el dato, pero se pierde la historia completa.

¿Qué es GraphRAG?
Es una variante avanzada de RAG (Retrieval‑Augmented Generation) que integra grafos de conocimiento para modelar entidades y sus relaciones, permitiendo recuperar rutas y contextos, no solo fragmentos semánticamente similares. En otras palabras:
- Razonamiento multisalto: conecta A → B → C cuando la respuesta requiere unir fuentes dispersas.
- Trazabilidad: cada respuesta puede mapearse a nodos y aristas concretas (útil en auditoría y cumplimiento).
- Mejor contexto: evita que la búsqueda vectorial “aplane” la estructura original del corpus.
Ventajas frente al RAG vectorial
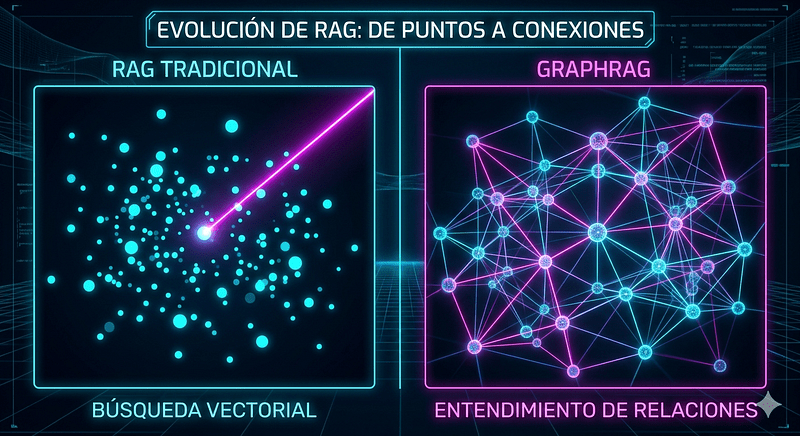
El RAG que todos conocemos funciona transformando texto en vectores (números) y buscando similitudes.
- Lo bueno: es rapidísimo para responder preguntas directas (“¿Qué dice el contrato en la cláusula 4?”).
- Lo malo: sufre de “ceguera de contexto”. Si le pides que conecte los puntos entre 50 documentos diferentes para entender una tendencia global, se marea. Trae fragmentos aislados, pero no entiende cómo se relacionan entre sí.
Arquitectura práctica
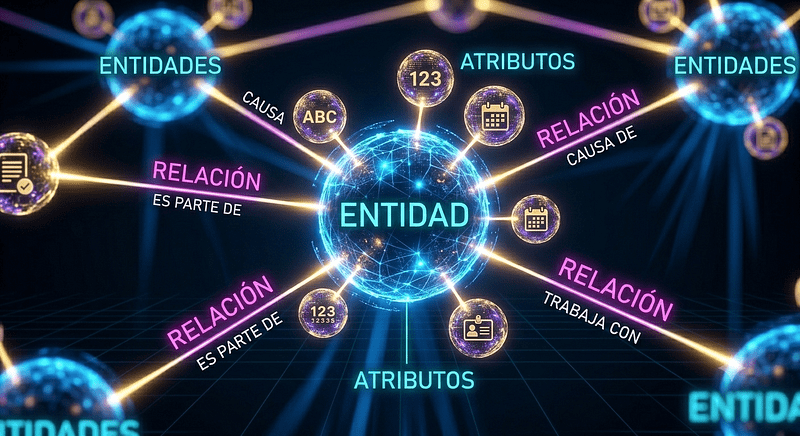
Imagina el típico tablero de corcho de un detective en las películas: fotos conectadas con hilos rojos. Eso es exactamente un Grafo de Conocimiento (Knowledge Graph), y es el motor de GraphRAG.
En lugar de solo guardar fragmentos de texto, GraphRAG extrae Entidades (nodos: personas, lugares, conceptos) y mapea sus Relaciones (aristas: “pertenece a”, “trabaja con”, “causa”).
Cuando le haces una pregunta a GraphRAG, la IA no solo busca palabras clave; navega por los hilos rojos. Entiende la topología de tu información.
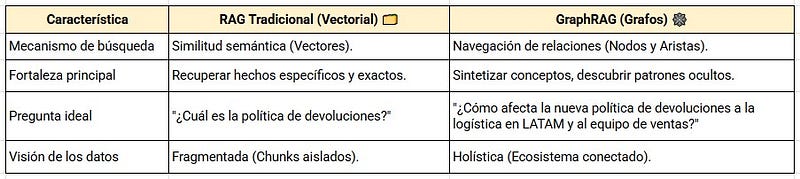
Comparativa Rápida: RAG vs. GraphRAG
Ejemplo 1 — Pregunta simple, explicación humana y funcional
Escenario: “¿Qué cláusulas de indemnización aplican si el proveedor X incumple en el contrato Y?” Cómo lo hace GraphRAG (pasos):
- Entidades: crea nodos para Proveedor X, Contrato Y, Cláusula de indemnización, Fechas, Anexos.
- Relaciones: añade aristas como aplica_a, referencia, vigente_desde.
- Consulta: el motor busca rutas desde Proveedor X hasta Cláusula de indemnización y recupera los fragmentos enlazados.
- Generación: el LLM recibe la sub‑red (nodos+aristas) y genera una respuesta con citas y enlaces a nodos. Resultado práctico: respuesta consolidada con referencias exactas a cláusulas y la ruta lógica usada.
Ejemplo 2 — Mini demo técnico (pseudocódigo)
Modelo mental: nodos = documentos/entidades; aristas = relaciones semánticas.
# pseudocódigo conceptual
grafo.add_node("Contrato Y", tipo="contrato")
grafo.add_node("Cláusula 12", tipo="cláusula")
grafo.add_edge("Contrato Y","Cláusula 12", relación="contiene")
ruta = grafo.find_paths("Proveedor X","Cláusula 12", max_hops=3)
contexto = extract_text_from_nodes(ruta)
respuesta = LLM.generate(question, context=contexto)Lenguaje del código: PHP (php)Clave: no es magia; es estructurar el corpus para que el LLM “vea” relaciones.
Recuperación topológica
Si estás construyendo agentes de IA o implementando automatizaciones complejas, GraphRAG te resuelve dolores de cabeza monumentales:
- Cero alucinaciones contextuales: al tener un mapa explícito de relaciones, la IA no tiene que “adivinar” cómo se conectan dos ideas. El margen de error (y de inventar datos) se desploma.
- Síntesis a gran escala: permite hacer preguntas abstractas sobre corpus de datos masivos. La IA puede resumir el “estado global” de un proyecto sin perder los detalles críticos.
- Explicabilidad (caja blanca): puedes rastrear exactamente por qué la IA llegó a una conclusión simplemente mirando el camino que recorrió en el grafo. ¡Adiós a la caja negra!
Para entender GraphRAG a nivel de arquitectura (sin enredarnos con configuraciones pesadas de Neo4j o miles de tokens en OpenAI de entrada), vamos a construir el motor lógico desde cero usando Python puro y la librería NetworkX.
Este script es 100% funcional. Te mostrará exactamente cómo un agente extrae contexto navegando por nodos y aristas (relaciones) en lugar de medir distancias vectoriales.
Visualización y escalado
Asegúrate de tener instalada la librería de grafos: !pip install networkx
import networkx as nx
# ==========================================
# 1. CONSTRUCCIÓN DEL GRAFO DE CONOCIMIENTO
# ==========================================
# En producción, un LLM extrae esto de tus documentos.
# Aquí lo armamos directamente para ilustrar el ecosistema.
kg = nx.Graph()
# Definimos las Entidades (Nodos) y sus Relaciones (Aristas)
kg.add_edge("Sistema de Pagos", "Checkout", relation="es parte de")
kg.add_edge("Checkout", "Stripe", relation="procesa pagos con")
kg.add_edge("Stripe", "API Key V2", relation="requiere")
kg.add_edge("Sistema de Pagos", "Base de Datos", relation="guarda transacciones en")
kg.add_edge("Base de Datos", "AWS RDS", relation="alojada en")
# ==========================================
# 2. EL MOTOR RAG (Retrieval) BASADO EN GRAFOS
# ==========================================
def retrieve_graph_context(query_entity, graph, depth=2):
"""
Aquí ocurre la magia de GraphRAG.
En lugar de buscar vectores similares, navegamos la topología de la información.
"""
if query_entity not in graph:
return ["Entidad no encontrada en el grafo."]
# Extraemos el vecindario (subgrafo) conectado a nuestra entidad a X saltos de distancia
subgraph_nodes = nx.single_source_shortest_path_length(graph, query_entity, cutoff=depth)
context = []
# Reconstruimos la historia leyendo los hilos rojos
for node in subgraph_nodes:
for neighbor, datadict in graph[node].items():
if neighbor in subgraph_nodes:
relation = datadict.get("relation", "está relacionado con")
context.append(f"[{node}] --({relation})--> [{neighbor}]")
# Eliminamos relaciones duplicadas (A->B es lo mismo que B->A en grafos no dirigidos)
return list(dict.fromkeys(context))
# ==========================================
# 3. GENERACIÓN AUMENTADA (La parte "AG" de GraphRAG)
# ==========================================
def llm_agent_response(query, context):
"""
Simulación del prompt final que le enviarías a Claude o Gemini.
"""
context_str = "\n".join(context)
prompt = f"""
Eres un Arquitecto de Software experto.
Pregunta del usuario: ¿Qué impacto tiene modificar el '{query}'?
Contexto recuperado del Grafo de Conocimiento:
{context_str}
Analiza las dependencias y responde con precisión técnica.
"""
# Aquí iría tu llamada real a la API del LLM.
# Mockeamos la respuesta inteligente para que el script corra localmente sin APIs.
return f"""
💡 Análisis de Impacto:
Modificar el **{query}** tiene un efecto cascada en la arquitectura.
Según el grafo de dependencias:
1. El Checkout depende directamente de **Stripe**.
2. Si actualizas Stripe, debes asegurarte de mantener la compatibilidad con la **API Key V2**.
3. Como el Checkout es parte del **Sistema de Pagos**, cualquier fallo aquí afectará la escritura de transacciones en la **Base de Datos** alojada en **AWS RDS**.
"""
# ==========================================
# 🚀 EJECUCIÓN DEL FLUJO
# ==========================================
if __name__ == "__main__":
entidad_objetivo = "Checkout"
print(f"🔍 PREGUNTA: ¿Qué pasa si modificamos el {entidad_objetivo}?\n")
# Paso 1: Recuperación topológica
contexto_recuperado = retrieve_graph_context(entidad_objetivo, kg, depth=2)
print("🕸️ CONTEXTO EXTRAÍDO (Hilos Rojos):")
for c in contexto_recuperado:
print(f" 👉 {c}")
print("\n" + "-"*40 + "\n")
# Paso 2: Generación
respuesta_final = llm_agent_response(entidad_objetivo, contexto_recuperado)
print("✨ RESPUESTA FINAL DEL AGENTE IA:")
print(respuesta_final)Lenguaje del código: PHP (php)¿Por qué esto es superior?: si analizas el bloque de ejecución, notarás tres diferencias críticas frente al RAG tradicional:
- Contexto estructurado, no texto suelto: en lugar de inyectar párrafos larguísimos (y costosos en tokens) al LLM, le estamos pasando una estructura lógica innegable:
[Checkout] --(procesa pagos con)--> [Stripe]. Esto reduce las alucinaciones a cero. - Exploración por saltos (
depth=2): el parámetrodepthpermite que la IA entienda el impacto de segundo y tercer grado. La IA supo que modificar el «Checkout» afectaba a «AWS RDS» porque siguió la cadena de nodos. Un RAG vectorial jamás haría esta conexión a menos que un documento textualmente dijera «El checkout afecta a AWS RDS». - Eficiencia técnica: para implementarlo a gran escala con agentes de IA reales, reemplazas
NetworkXpor una base de datos de grafos pura (como Neo4j) y usas flujos automatizados para que tu LLM convierta PDFs en estas tuplas deNodo-Relación-Nodo.
Entender el grafo de forma abstracta está bien, pero verlo es lo que hace que el concepto de GraphRAG realmente haga clic en la cabeza. En un entorno de desarrollo real, tienes dos caminos principales para visualizar estas estructuras:
- Visualización Local: si quieres renderizar el grafo directamente desde el script que construimos usando
NetworkX, la forma más rápida y estándar es usar la libreríamatplotlib. Solo necesitas agregar este bloque al final de tu script (asegúrate de hacer!pip install matplotlib):
import matplotlib.pyplot as plt
# Generamos un layout (distribución espacial de los nodos)
pos = nx.spring_layout(kg, seed=42)
plt.figure(figsize=(10, 6))
# Dibujamos los nodos con estilo
nx.draw(kg, pos, with_labels=True, node_size=3500, font_size=10, font_weight="bold", alpha=0.9)
# Extraemos y dibujamos las etiquetas de las aristas (las relaciones)
edge_labels = nx.get_edge_attributes(kg, 'relation')
nx.draw_networkx_edge_labels(kg, pos, edge_labels=edge_labels, font_size=9)
plt.title("Arquitectura: Ecosistema de Pagos", fontsize=14)
plt.show()Lenguaje del código: PHP (php)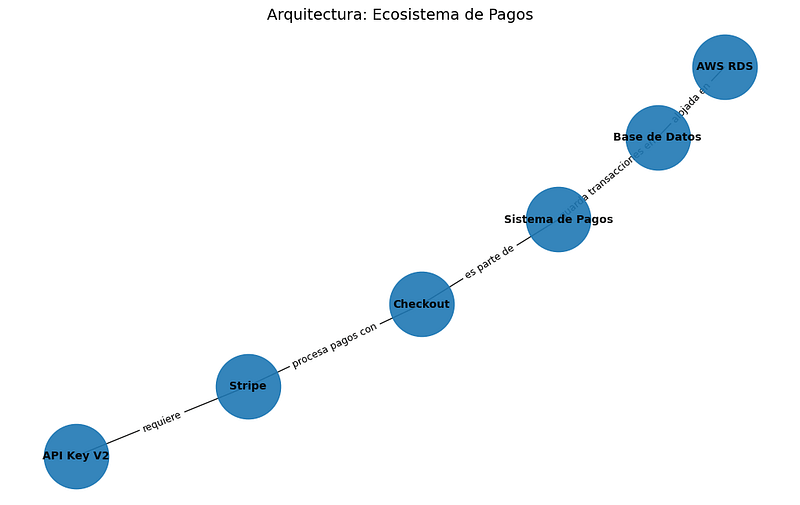
- Herramientas de Producción: cuando tu grafo de conocimiento no tiene 6 nodos, sino 6 millones, Python se queda corto. En esos casos, la arquitectura exige bases de datos de grafos nativas. Las opciones líderes en la industria que incluyen visualizadores interactivos brutales son:
- Neo4j (con Neo4j Bloom): el rey indiscutible. Te permite navegar visualmente por bases de datos masivas.
- PyVis / Gephi: excelentes para renderizar grafos complejos en HTML interactivo directamente desde Python.
¿Cuándo usar GraphRAG?
- Sí necesitas: razonamiento multisalto, trazabilidad, integración de datos estructurados.
- No si tu corpus es pequeño y las preguntas son directas (RAG vectorial basta).
Limitaciones
- Modelado incorrecto del grafo puede inducir respuestas erróneas.
- Coste y complejidad: construir y mantener grafos exige ingeniería y gobernanza de datos.
La verdadera inteligencia no es saber dónde está un dato; es entender qué significa ese dato en relación con todo lo demás. GraphRAG no es solo una optimización técnica, es un cambio de paradigma. Es dotar a nuestros sistemas de IA de una visión panorámica, permitiéndoles razonar con la misma riqueza y complejidad estructural que el cerebro humano. Entonces, GraphRAG no es solo buscar mejor: es enseñar a la IA a “leer” las conexiones entre cosas.
¿Estás construyendo con vectores y sintiendo que te falta contexto? Quizás es momento de empezar a dibujar grafos.