
Las convenciones, la inteligencia del compilador y los límites del servidor no son detalles de ergonomía: son la nueva interfaz entre las codebases y los agentes de IA que trabajan dentro de ellas.
Lo sé, lo sé… La pregunta, así formulada, es realmente provocadora. Implica que existe un umbral a partir del cual los agentes de IA vuelven superfluas las abstracciones que llamamos “frameworks”. Además, sugiere que la historia reciente de React, Next.js, Angular, Svelte, Astro, Solid y compañía es la historia de herramientas pensadas para humanos que ahora deberían dar un paso atrás.
Es un framing cómodo para generar titulares, y casi inútil para entender qué está ocurriendo realmente en el ecosistema JavaScript.
Hecha esta necesaria aclaración, quitémonos el sombrero de papel de aluminio y empecemos a observar que lo que está pasando es más interesante que espectacular. Los frameworks no están retrocediendo. Están cambiando de interlocutor. Durante quince años han optimizado una única métrica: la Developer Experience, porque su usuario principal era un ser humano frente a un IDE.
Desde hace unos dos años, esta premisa ha dejado de ser cierta. Una cuota creciente del código que entra en producción es generado, modificado u orquestado por un agente de IA: Cursor, Claude Code, GitHub Copilot, Devin, Windsurf, el que prefieras. El usuario del framework ya no es solo un humano. Es un sistema software con sus límites, sus sesgos y sus “preferencias” (si es que podemos llamarlas así).

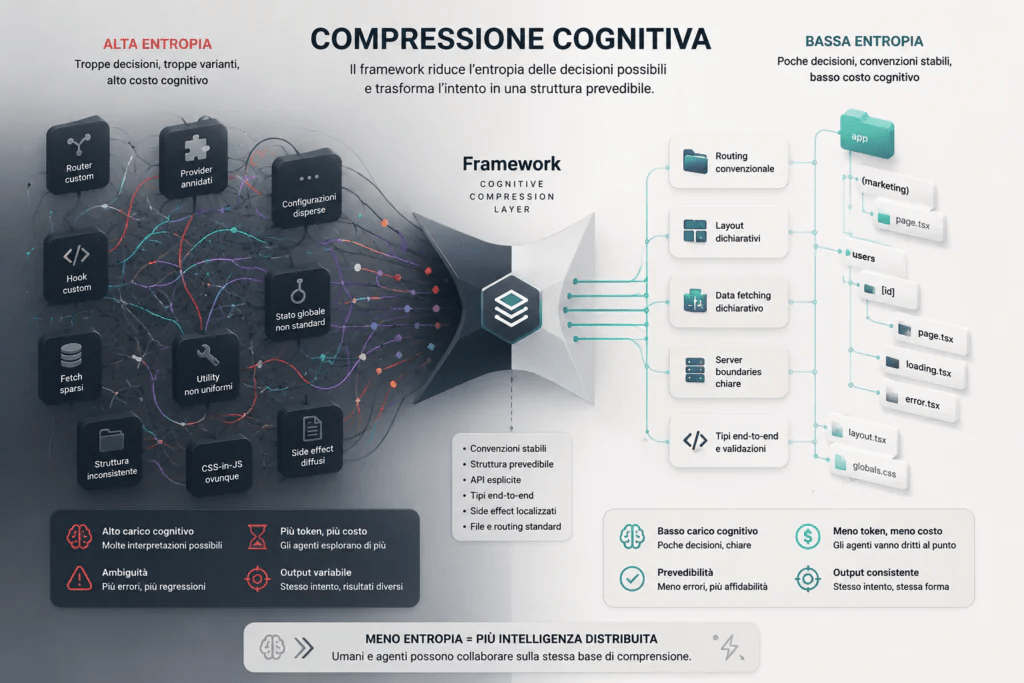
Los frameworks que sobrevivan a los próximos cinco años serán aquellos que estén rediseñando sus convenciones también para este nuevo usuario. No deben sustituir al humano, sino permitir que agente e ingeniero trabajen juntos. El punto central de este artículo es que el framework, en la era agentica, deja de ser una “comodidad para quien escribe código” y se convierte en algo estructuralmente distinto: una capa de compresión cognitiva entre la intención (humana o del agente) y la máquina.
De DX a ADX
Durante años, la métrica dominante ha sido la Developer Experience (DX para los amigos): tiempo de setup, ergonomía de las APIs, calidad de los errores, hot reload, autocompletado. Era una métrica calibrada para un cerebro humano leyendo código pieza a pieza.
En el último año (más o menos), está emergiendo una métrica paralela que, a falta de mejor nombre, podemos llamar Agent Developer Experience (ADX). ¿Qué es la ADX?
Se refiere a lo fácil que es, para un agente de IA:
- navegar una codebase
- entender qué modificar
- hacer la modificación correcta al primer intento
- no romper aquello que no ve o que todavía no “conoce”
La ADX no es lo opuesto a la DX: es su derivada, si queremos usar términos matemáticos. Las características que hacen que un código sea legible para un humano competente (convenciones estables, dependencias explícitas, tipos end-to-end, side effects localizados) son las mismas que lo hacen manipulable por un LLM. Pero con una diferencia de escala: cuando el código se genera en masa, incluso pequeñas ambigüedades se amplifican en errores enormes y poco controlables.
Seguro que lo habéis visto: empiezas con una petición simple como “créame un hook de React” y, veinte minutos después, estás perdido entre tests, linters que no pasan y un “spaghetti code” indescifrable.
Los frameworks modernos están respondiendo a esta presión de forma bastante coherente: file-based routing, server components, typed routing… Son todas respuestas al mismo problema: reducir la variabilidad del output. Hacer que, para una intención dada, exista un número reducido de soluciones plausibles, idealmente una sola.
La tesis de la compresión cognitiva
Para entender por qué esta convergencia no es casual, conviene dar un paso atrás. Un sistema software complejo se caracteriza por la entropía de decisiones que deben tomar quienes trabajan en él:
- ¿Dónde va ese componente?
- ¿Cómo se hace fetch de datos?
- ¿Dónde empieza el servidor?
- ¿Cómo se declara una ruta?
Cada pregunta admite múltiples respuestas técnicamente equivalentes, pero cognitivamente costosas.
Un framework opinionado responde a estas preguntas antes de que se formulen. Reduce la varianza. Comprime el espacio de decisiones. Para un equipo humano esto es ergonomía. Para un agente de IA es algo más crítico: es la condición para que su output sea verificable.
Repitámoslo como un mantra: un LLM no “comprende” el código en sentido fuerte. Un LLM razona sobre patrones, sobre distribuciones estadísticas de tokens, sobre estructuras sintácticas aprendidas durante el entrenamiento. Un LLM funciona mejor donde las estructuras están más representadas y son más estables.
Un App Router de Next.js, con su jerarquía app/[segment]/page.tsx, es fácil de representar para un modelo: a una ruta URL le corresponde un archivo, a un layout otro archivo, a un loading state otro más. Una SPA en React con react-router configurado manualmente en un App.tsx, con lazy imports dispersos y providers anidados, obliga al modelo a reconstruir un mapa que el framework ha decidido no imponer. El primer caso es legible. El segundo debe interpretarse.
La diferencia, en producción, no es teórica: se mide en el número de archivos que el agente toca para implementar una feature, en la probabilidad de modificar el archivo correcto a la primera, y en la cantidad de código que el senior tiene que reescribir durante el review.
Anatomía de un framework “AI-native”
Ahora que hemos aclarado qué es la ADX y por qué es relevante, podemos analizar cinco características que están emergiendo como patrones comunes en frameworks adaptados a la era agentica.
Convenciones basadas en archivos comprensibles sin documentación
Next.js App Router, Nuxt, SvelteKit, SolidStart,, Astro, Qwik City, TanStack Start: : todos convergen en sistemas de ficheros donde la posición del archivo es información en sí misma. No es un detalle estético: es una API legible sin necesidad de manual (humano o máquina). Una codebase con app/dashboard/[id]/page.tsx y app/dashboard/[id]/layout.tsx explica su arquitectura sin README.
Reactividad explícita, no mágica
Los frameworks compiler-first (como Svelte) tienen una ventaja estructural: el código se traduce de forma formal y determinista. Las runes de Svelte 5 y los signals de Solid o Angular son modelos declarativos de reactividad: no dependen del orden de ejecución (como los hooks de React) ni de reglas de linting para ser correctos.
Para un LLM que modifica reactividad, la diferencia es enorme. Un closure stale en un useEffect es un bug clásico que los agentes siguen reproduciendo. Una rune declarada con $state es casi imposible de romper de la misma forma. Es precisamente este tipo de previsibilidad lo que la memoización intenta recuperar a nivel de compilador.
Optimiza automáticamente tu aplicación React gestionando la memorización por ti, eliminando la necesidad de usar manualmente
useMemo,useCallbackyReact.memo.
Tipos end-to-end
TanStack Router ha convertido el routing tipado en una característica de primera clase: parámetros de ruta, search params y loaders son tipos que fluyen a través de la app. Next.js está llegando a lo mismo por otra vía, con typed routes y Server Actions tipadas en el boundary.
Para un agente, el tipado end-to-end es una red de seguridad que evita toda una clase de outputs plausibles pero incorrectos.
Server boundaries explícitos
Los React Server Components, las Server Actions de Next.js y React Router 7, los loaders/actions de TanStack Start, o los +page.server.ts de SvelteKit son intentos de hacer visible dónde termina el cliente y dónde empieza el servidor.
Sin esta declaración, cada componente es potencialmente todo a la vez. Un agente que genera código debe adivinar. Con esta separación explícita, el problema desaparece.
Metadatos estructurados e introspección
Astro Content Collections con schema Zod, frontmatter tipado, manifiestos de build, route manifests… Son formas de exponer la estructura de la app en formato legible por máquinas. Aquí entra MCP (Model Context Protocol), que se está convirtiendo en estándar de facto para exponer contexto y capacidades a agentes. Un servidor MCP que publica rutas, layouts y server functions de una app Next.js marca la diferencia entre un agente que hace grep y uno que hace queries estructuradas.
Framework por framework, sin fanatismos
Vale la pena ver algunos ejemplos. Para cada uno se explora el mismo caso mínimo (una ruta que obtiene una lista de usuarios desde una API y la renderiza), porque es la forma más honesta de comparar cómo se adaptan al ADX.
La pregunta implícita es siempre la misma: si a un agente le pido “añade una página /users que liste usuarios”, ¿cuántas decisiones tiene que tomar por sí solo y cuál es la probabilidad de que las tome bien?
Next.js (App Router)
Next.js es el ejemplo más claro de framework que se está transformando en protocolo. App Router, Server Actions, integración nativa con el AI SDK de Vercel, soporte creciente de MCP, generadores como v0 que producen directamente código Next.js: es un sistema donde las decisiones de runtime, build, edge y data fetching están predefinidas para un modelo mental concreto.
La contrapartida es la concentración: elegir Next.js significa adoptar, en gran medida, la visión de Vercel sobre el futuro de la web. Para muchos equipos es un trade-off razonable. Para otros, es una preocupación legítima, y el debate sobre React Server Components fuera del ecosistema Next es un síntoma evidente de ello.
// app/users/page.tsx <strong>export</strong> <strong>default</strong> <strong>async</strong> <strong>function</strong> <strong>UsersPage</strong>() { <strong>const</strong> users = <strong>await</strong> fetch('https://api.example.com/users') .then((r) => r.json()) <strong>return</strong> ( <<strong>ul</strong>> {users.map((u) => <<strong>li</strong> key={u.id}>{u.name}</<strong>li</strong>>)} </<strong>ul</strong>> ) }Lenguaje del código: JSON / JSON con comentarios (json)ADX: la ruta del archivo es la URL, el componente es server-side por defecto (es un async server component), el fetch no requiere useEffect, ni react-query, ni un store. Un agente que recibe “añade una página /users que liste los usuarios” sabe exactamente dónde crear el archivo, qué firma usar y que el fetch es server-side sin tener que tomar decisiones. El espacio de soluciones plausibles es minúsculo.
Modificar la página para añadir caché, streaming o revalidación requiere tocar el mismo archivo con primitivas bien conocidas (fetch con next.revalidate, , revalidatePath). Alta densidad de convención por línea de código.
React sin framework
React “puro y duro” es la posición que la era agentica está penalizando más. No porque React sea obsoleto, sino porque la combinación “React + Vite + react-router + tanstack-query + zustand + librería de formularios + librería de tablas” es una colección de decisiones locales óptimas que no se comunican entre sí.
Cada proyecto es casi artesanal. Cada agente, frente a uno de estos proyectos, tiene que reconstruir convenciones que no existen (o que están en la cabeza del desarrollador que creó el proyecto) y trabajar con “lo que hay”.
// src/App.tsx <strong>import</strong> { BrowserRouter, Routes, Route } <strong>from</strong> 'react-router-dom' <strong>import</strong> { QueryClient, QueryClientProvider, useQuery } <strong>from</strong> '@tanstack/react-query' <strong>const</strong> qc = <strong>new</strong> QueryClient() <strong>function</strong> <strong>UsersPage</strong>() { <strong>const</strong> { data, isLoading } = useQuery({ queryKey: ['users'], queryFn: () => fetch('/api/users').then((r) => r.json()), }) <strong>if</strong> (isLoading) <strong>return</strong> <<strong>div</strong>>Loading…</<strong>div</strong>> <strong>return</strong> <<strong>ul</strong>>{data.map((u: any) => <<strong>li</strong> key={u.id}>{u.name}</<strong>li</strong>>)}</<strong>ul</strong>> } <strong>export</strong> <strong>default</strong> <strong>function</strong> <strong>App</strong>() { <strong>return</strong> ( <<strong>QueryClientProvider</strong> client={qc}> <<strong>BrowserRouter</strong>> <<strong>Routes</strong>> <<strong>Route</strong> path="/users" element={<UsersPage />} /> </<strong>Routes</strong>> </<strong>BrowserRouter</strong>> </<strong>QueryClientProvider</strong>> ) }Lenguaje del código: JSON / JSON con comentarios (json)ADX: nada estándar. El agente tiene que descubrir por sí mismo dónde están declaradas las rutas (¿un componente en algún sitio? ¿un archivo routes.ts? ¿imports lazy?), qué fetcher se está usando (¿react-query? ¿swr? ¿fetch directo? ¿un cliente API personalizado?), dónde viven los providers, si hay SSR. Cada decisión es arbitraria, cada proyecto es distinto. La probabilidad de que el agente genere código “plausible pero incoherente con el resto” es alta, y crece con el tamaño del repositorio.
La verdadera pregunta que hay que hacerse en 2026 ya no es “qué librería de UI”, sino “qué framework alrededor de React”.
Angular
Angular está viviendo un renacimiento silencioso que muchos comentaristas están ignorando. Componentes standalone, signals, control flow nativo, defer block: el Angular de 2026 es un framework profundamente distinto al de los NgModule, y es (paradójicamente) uno de los más amigables para LLMs que existen.
// app/users/users.component.ts
<strong>import</strong> { Component, inject } <strong>from</strong> '@angular/core'
<strong>import</strong> { HttpClient } <strong>from</strong> '@angular/common/http'
<strong>import</strong> { toSignal } <strong>from</strong> '@angular/core/rxjs-interop'
@Component({
standalone: true,
template: `
<ul>
@for (u of users(); track u.id) {
<li>{{ u.name }}</li>
}
</ul>
`,
})
<strong>export</strong> <strong>class</strong> <strong>UsersComponent</strong> {
private http = inject(HttpClient)
users = toSignal(
<strong>this</strong>.http.get<{ id: number; name: string }[]>('/api/users'),
{ initialValue: [] }
)
}
// app.routes.ts
<strong>import</strong> { Routes } <strong>from</strong> '@angular/router'
<strong>export</strong> <strong>const</strong> routes: Routes = [
{
path: 'users',
loadComponent: () =>
<strong>import</strong>('./users/users.component').then((m) => m.UsersComponent),
},
]Lenguaje del código: HTML, XML (xml)ADX: dependencias inyectadas explícitamente (inject(HttpClient)), signals declarativos en lugar de observables “mágicos”, control flow nativo (@for con track). Para un LLM todo es explícito: qué se importa, dónde vive el estado, cómo se itera, dónde la ruta carga el componente.
Pocos misterios en tiempo de ejecución, convenciones rigurosas, errores del compilador claros: si el ecosistema enterprise lo está redescubriendo, una de las razones es precisamente esta.
Vue / Nuxt
Vue y Nuxt ocupan el nicho de “lo aburrido es bonito”: convenciones sólidas, ecosistema maduro, sin cambios radicales. Para muchos equipos es exactamente lo que hace falta.
<!-- pages/users.vue --> <<strong>script</strong> setup lang="ts"> <strong>interface</strong> <strong>User</strong> { id: number; name: string } <strong>const</strong> { data: users } = await useFetch<User[]>('/api/users') </<strong>script</strong>> <<strong>template</strong>> <<strong>ul</strong>> <<strong>li</strong> v-for="u in users" :key="u.id">{{ u.name }}</<strong>li</strong>> </<strong>ul</strong>> </<strong>template</strong>>Lenguaje del código: PHP (php)ADX: archivo en pages/ = ruta, useFetch es la convención estándar (server en el primer render, cliente después), componente de archivo único con secciones declarativas claramente separadas. Para un agente es casi trivial: el patrón es idéntico para cualquier página, el auto-import de Nuxt reduce aún más las decisiones. La verbosidad es baja, la ambigüedad también. Un código base en Nuxt es casi siempre más legible que uno equivalente en complejidad en Next.js, simplemente porque el ecosistema de Vue siempre ha priorizado la convención sobre la innovación.
Svelte 5 / SvelteKit
Svelte 5 ha hecho la apuesta más radical: las runes trasladan la reactividad de “mágica e implícita” a “explícita y declarativa”.
// src/routes/users/+page.server.ts
import type { PageServerLoad } from ‘./$types’
export const load: PageServerLoad = async ({ fetch }) => {
const users = await fetch(‘/api/users’).then((r) => r.json())
return { users }
}
Code language: JavaScript (javascript)
ADX: el +page.server.ts hace que el boundary cliente/servidor sea explícito a nivel léxico; no es una convención sintáctica como 'use server', está escrito directamente en el nombre del archivo. No hay posibilidad de equivocarse.
Las runes ($props, $state, $derived) son declaraciones, no llamadas sensibles al orden como los hooks de React. El compilador garantiza que la salida en runtime sea analizable y optimizada. Para un LLM que tiene que modificar un componente, la diferencia entre $state(0) y una variable cuya reactividad depende de reglas sintácticas es la diferencia entre una API y un misterio. Es una de las ergonomías más favorables para agentes del mercado.
Solid / SolidStart
Solid y SolidStart comparten la filosofía compiler-first de Svelte con un purismo conceptual aún más marcado. La reactividad granular de Solid es uno de los modelos mentales más limpios de todo el ecosistema.
// src/routes/users.tsx <strong>import</strong> { For } <strong>from</strong> 'solid-js' <strong>import</strong> { createAsync, query } <strong>from</strong> '@solidjs/router' <strong>const</strong> getUsers = query(<strong>async</strong> () => { <strong>const</strong> res = <strong>await</strong> fetch('/api/users') <strong>return</strong> res.json() <strong>as</strong> Promise<{ id: number; name: string }[]> }, 'users') <strong>export</strong> <strong>default</strong> <strong>function</strong> <strong>Users</strong>() { <strong>const</strong> users = createAsync(() => getUsers()) <strong>return</strong> ( <<strong>ul</strong>> <<strong>For</strong> each={users()}>{(u) => <<strong>li</strong>>{u.name}</<strong>li</strong>>}</<strong>For</strong>> </<strong>ul</strong>> ) }Lenguaje del código: JSON / JSON con comentarios (json)ADX: reactividad basada en signals explícita: los paréntesis () revelan el acceso reactivo de un vistazo. en lugar de .map() para listas, porque Solid no vuelve a renderizar todo el componente: la diferencia es visible a nivel sintáctico. El modelo mental es coherente al 100%: no hay casos especiales, no hay “reglas de hooks”, no hay dependencias que declarar a mano. Para un LLM, la coherencia es oro — y no es casualidad que las ideas de Ryan Carniato hayan migrado, en formas distintas, dentro de Vue, Angular e incluso el trabajo sobre React Forget.
Astro
Astro ha elegido un posicionamiento lateral e inteligente: content-first, islands, esquema estructurado para el contenido. Es el framework que mejor se adapta a sitios donde el contenido es el producto y la interactividad es puntual.
--- // src/pages/users.astro interface User { id: number; name: string } <strong>const</strong> users: User[] = <strong>await</strong> fetch('https://api.example.com/users') .then((r) => r.json()) --- <<strong>ul</strong>> {users.map((u) => <<strong>li</strong>>{u.name}</<strong>li</strong>>)} </<strong>ul</strong>>Lenguaje del código: JavaScript (javascript)ADX: el frontmatter (—) es server-side por construcción, siempre, sin excepciones. El template es estático por defecto. No hay nada que decidir sobre cliente vs servidor: se deduce de la propia sintaxis. Añadir interactividad requiere una island explícita (), y ese es precisamente el mecanismo que reduce la varianza para el agente. Cuando se entra en el terreno de los contenidos, las Content Collections con esquema Zod se convierten en un contrato legible para el LLM: el esquema es la documentación, y el agente lo usa como tal para generar contenido coherente.
Una codebase de Astro bien estructurada es uno de los terrenos más ergonómicos en absoluto para un agente.
Qwik / Qwik City
Qwik es la apuesta a largo plazo: la resumabilidad sustituye la hidratación, el modelo de ejecución es formalmente más limpio, la app es “lazy” por construcción.
// src/routes/users/index.tsx <strong>import</strong> { component$ } <strong>from</strong> '@builder.io/qwik' <strong>import</strong> { routeLoader$ } <strong>from</strong> '@builder.io/qwik-city' <strong>export</strong> <strong>const</strong> useUsers = routeLoader$(<strong>async</strong> () => { <strong>const</strong> res = <strong>await</strong> fetch('https://api.example.com/users') <strong>return</strong> res.json() <strong>as</strong> Promise<{ id: number; name: string }[]> }) <strong>export</strong> <strong>default</strong> component$(() => { <strong>const</strong> users = useUsers() <strong>return</strong> ( <<strong>ul</strong>> {users.value.map((u) => <<strong>li</strong> key={u.id}>{u.name}</<strong>li</strong>>)} </<strong>ul</strong>> ) })Lenguaje del código: JSON / JSON con comentarios (json)ADX: el sufijo $ no es cosmético, es la marca léxica de un boundary de lazy loading, legible tanto para el compilador como para el agente como un límite de ejecución. routeLoader$ es server-side por construcción; component$ es el marcador de un componente resumable.
Más rígido que otros frameworks, pero precisamente por eso extraordinariamente legible para una máquina: cada $ es una declaración formal de “aquí sucede algo específico”, y no hay ambigüedad sobre qué. Qwik aún no tiene el momentum de los frameworks principales, pero la formalidad de su modelo lo hace especialmente interesante para quienes piensan a largo plazo.
React Router 7 (ex Remix)
Remix se ha convertido en React Router 7, fusionando el framework y el router en una única entidad. El movimiento es coherente con la tesis de este artículo: cada vez menos piezas separadas, cada vez más contratos integrados.
// app/routes/users.tsx import type { Route } from ‘./+types/users’ export async function loader() { const res = await fetch(‘https://api.example.com/users’) const users = (await res.json()) as { id: number; name: string }[] return { users } } export default function Users({ loaderData }: Route.ComponentProps) { return ( <ul> {loaderData.users.map((u) => <li key={u.id}>{u.name}</li>)} </ul> ) }
ADX: patrón loader/component canónico, tipos auto-generados (Route.ComponentProps viene de ./+types/users) que fluyen del loader al componente sin que el desarrollador (o el agente de turno) tenga que declararlos. Un agente sabe exactamente dónde está el fetch (loader, server) y dónde está la presentación (componente, posiblemente client).
La fusión Remix => RR7 ha consolidado este patrón como uno de los más limpios del ecosistema React, y es uno de los pocos casos en los que una evolución arquitectónica ha aumentado el ADX en lugar de degradarlo.
TanStack Start
TanStack representa el anti-modelo declarado. La filosofía de Tanner Linsley es clara: en lugar de un framework opinado, primitivas fuertemente tipadas y componibles.
// src/routes/users.tsx <strong>import</strong> { createFileRoute } <strong>from</strong> '@tanstack/react-router' <strong>export</strong> <strong>const</strong> Route = createFileRoute('/users')({ loader: <strong>async</strong> () => { <strong>const</strong> res = <strong>await</strong> fetch('/api/users') <strong>return</strong> res.json() <strong>as</strong> Promise<{ id: number; name: string }[]> }, component: UsersPage, }) <strong>function</strong> <strong>UsersPage</strong>() { <strong>const</strong> users = Route.useLoaderData() <strong>return</strong> ( <<strong>ul</strong>> {users.map((u) => <<strong>li</strong> key={u.id}>{u.name}</<strong>li</strong>>)} </<strong>ul</strong>> ) }Lenguaje del código: JSON / JSON con comentarios (json)ADX: la tipización end-to-end es muy fuerte: el tipo del loader se propaga al componente, a los search params y a todos los que apuntan a esta ruta.
Para un agente, TanStack es un terreno de juego excelente: los errores de tipos interceptan gran parte de las salidas incorrectas antes de que lleguen a revisión humana. Para un agente menos disciplinado que ignora los tipos, la verbosidad se convierte en ruido. La pregunta que la era agentica plantea sobre TanStack es honesta: ¿qué tan bien se comporta cuando la mitad del código es escrito por un agente que no tiene las mismas intuiciones que el equipo que eligió las primitivas?
Es una pregunta abierta, y que vale la pena mantener abierta.
Qué ve un agente cuando entra en un repositorio
Vale la pena detenerse y ver con detalle qué ocurre, concretamente, cuando una herramienta como Cursor, Codex o Claude Code abre por primera vez una codebase. Es el punto donde las consideraciones teóricas se traducen en diferencias medibles y donde la idea de “compresión cognitiva” deja de ser metáfora.
Codebase indexing
La herramienta construye en segundo plano una representación estructurada del proyecto. Los componentes típicos de esta representación son al menos tres:
- Un mapa de archivos con metadatos básicos (ruta, lenguaje, tamaño, hash).
- Un conjunto de embeddings semánticos calculados sobre chunks de código de tamaño variable (función, clase, bloque de imports, sección de documentación).
- Un grafo de símbolos públicos (funciones exportadas, tipos, clases) derivado de análisis estático o de language servers como tsserver.
Cursor publica documentación explícita sobre esto (aquí puedes leer un buen análisis), y Claude Code hace algo similar de forma menos verbosa. La calidad de la indexación depende en gran medida de cuán estructurada y reconocible sea la codebase: un módulo llamado users.ts con un export llamado getUsers es infinitamente más fácil de encontrar que una arrow function anónima dentro de un useQuery en un componente.
Cuando llega un prompt tipo “añade paginación a la lista de usuarios”, el agente no envía todo el repositorio al modelo. Hace retrieval: combina búsqueda semántica sobre embeddings, búsqueda léxica (normalmente ripgrep bajo el capó) y navegación del grafo de símbolos para construir un contexto relevante.
Sobre ese contexto, y una serie de herramientas como read_file, grep, find_references, edit_file, el modelo razona de forma iterativa. Es un bucle: propone una consulta, recibe resultados, propone un cambio o nueva consulta, y así hasta producir el diff final. Cada paso consume tokens, latencia, y sobre todo abre la puerta a desviarse.
Aquí las convenciones del framework empiezan a marcar diferencias reales. En una codebase de Next.js App Router, “encontrar la página de usuarios” se resuelve en el primer paso: app/users/page.tsx existe o no existe. En Astro, “modificar el esquema de posts” es un único archivo en src/content/config.ts con un esquema Zod explícito legible tanto por el agente como por un humano. En Angular moderno, los standalone components con inject() explícito dicen al modelo qué importar y desde dónde. En SvelteKit, +page.server.ts declara de forma léxica que el archivo es server-side: el agente no puede confundirlo con código cliente.
En una codebase React “vanilla” con configuración artesanal, nada de esto está dado. “Encontrar la página de usuarios” se convierte en: grep en todo el repo, parsing manual de dónde está <Routes>, navegación de imports, identificar el componente, ver si el fetch está en useEffect, en useQuery, en un hook custom o en un servicio API.
Cada paso es una oportunidad de error. El agente suele hacerlo bien en casos comunes, y por eso la ilusión de “la IA lo hace todo” es tan convincente. El problema es la varianza: errores sutiles frecuentes, y coste de revisión humana creciente.
En una codebase pequeña no se nota; en equipos grandes sí, y se mide en PRs rechazadas, regresiones en producción y sesiones de debugging evitables.
MCP y el cambio de interfaz
Aquí aparece un modelo emergente: el Model Context Protocol. Estándar promovido por Anthropic y adoptado por herramientas modernas, permite exponer a los agentes no solo archivos sino capacidades estructuradas.
Un MCP server para una app Next.js puede responder preguntas como:
- “lista todas las rutas”
- “cuál es el loader de /dashboard/[id]”
- “qué Server Actions modifican la tabla users”
- “qué esquema devuelve getUserById”
Un agente con acceso a MCP ya no hace grep: hace queries estructuradas. Es la diferencia entre leer documentación a mano y consultar un SQL bien diseñado.
Vercel empuja explícitamente en esta dirección; SvelteKit, Nuxt y Angular tienen iniciativas similares. Un framework que expone su “API interna” (rutas, layouts, server functions, esquemas de datos, config de build) se convierte en una herramienta programable para agentes.
Es la extensión natural de la compresión cognitiva: primero el framework reduce decisiones mediante convenciones; luego las expone de forma machine-readable mediante protocolos.
Standardización, fragmentación y Schelling points
La pregunta de fondo es si la IA fragmenta o estandariza el ecosistema.
La intuición de la fragmentación es simple: si un agente me ayuda con cualquier framework, puedo elegir cualquiera. Pero los LLM no funcionan así: son distribucionales. Rinden mejor en patrones más representados en los datos.
Eso crea un bucle:
- frameworks más usados → mejor rendimiento del modelo
- mejor rendimiento del modelo → más adopción
- más adopción → más datos
Resultado: convergencia.
Esto es un efecto Schelling point.
Schelling planteaba un problema: dos personas deben coordinarse sin comunicarse. La solución tiende a un punto focal (Grand Central Station, mediodía). No porque sea óptimo, sino porque ambos esperan que el otro lo elija.
En frameworks ocurre algo similar entre tres actores:
- desarrolladores
- herramientas de IA
- frameworks
Todos convergen hacia los mismos puntos de mayor visibilidad en datos: documentación, GitHub, ejemplos, tutoriales.
No es solo efecto de red. Es un loop estadístico de entrenamiento.
Consecuencias
Esto favorece el mainstream (React + Next.js + Vercel), pero penaliza ecosistemas pequeños no por inferioridad técnica, sino por menor presencia en datos.
También crea presión hacia versiones recientes: App Router es más visible en datasets actuales que Pages Router. Incluso dentro del mismo framework, el “presente” gana sobre el “legacy”.
Implicación para equipos senior
El rol senior cambia: menos escribir lógica compleja, más diseñar límites donde los agentes pueden operar sin romper el sistema.
La code review deja de ser lectura línea por línea y pasa a ser verificación de coherencia arquitectónica.
La decisión tecnológica deja de ser “qué nos gusta” y pasa a ser “qué es legible para humanos + agentes en 3 años”.
Debito técnico generado por agentes
Aparece un nuevo tipo de deuda: código correcto pero frágil en casos no cubiertos. Es difícil de detectar porque “parece terminado”.
Las convenciones fuertes reducen este espacio de error.
Escenarios a 3–5 años
- Convergencia hacia framework-as-protocol (Next/Vercel/MCP dominante).
- Dominio de compiler-first (Svelte/Solid/React evolucionado).
- Fragmentación asistida por mejores agentes.
- El framework desaparece como preocupación humana.
La pregunta real
La cuestión no es qué framework elegir.
Es otra:
¿cuánto de tu codebase es legible sin tu cerebro en medio?
Porque en la era agentica, el valor ya no es solo ergonomía del desarrollador. Es legibilidad para una mezcla de humanos y sistemas que escriben código en tu lugar.
Y eso cambia completamente qué significa “buena arquitectura”.
