
C’è un filo rosso che attraversa gli ultimi sei mesi di sviluppo dell’intelligenza artificiale cinese, e corre parallelo alla geografia delle restrizioni commerciali imposte da Washington. Ogni volta che pensiamo di aver tracciato i confini dell’innovazione possibile sotto embargo hardware, un nuovo modello riscrive le regole del gioco. È successo con Kimi K2.5 a dicembre, con Qwen 3 a gennaio, con DeepSeek MHC poche settimane fa. Ora tocca a MiniMax M2.5, un modello che arriva sul mercato con una proposta tanto semplice quanto destabilizzante: prestazioni da modello di frontiera a un decimo del prezzo della concorrenza occidentale.
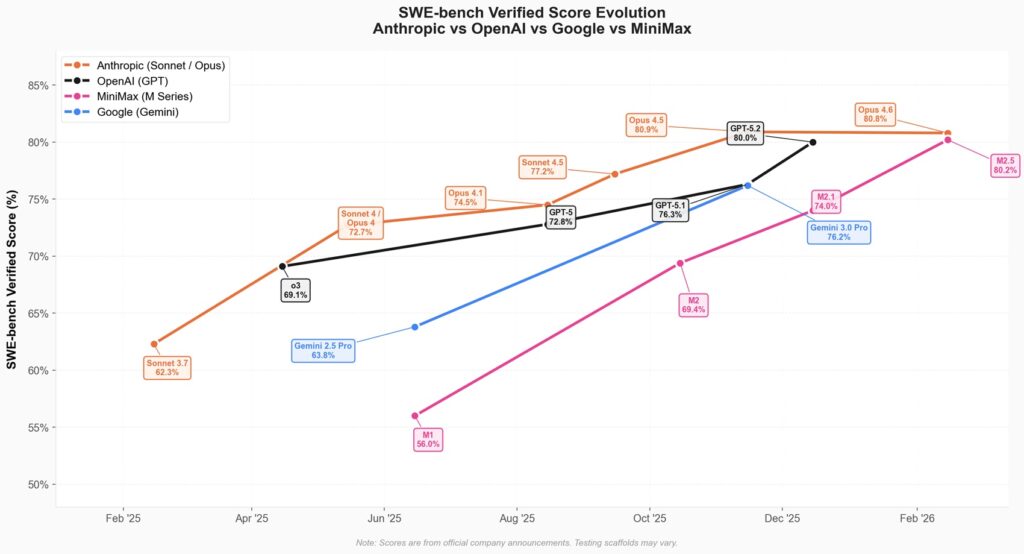
Il lancio del 12 febbraio 2026 si inserisce in una traiettoria che stiamo documentando da mesi: la capacità dell’ecosistema cinese di trasformare i limiti imposti dalle restrizioni sui chip avanzati in acceleratori di innovazione. MiniMax, startup di Shanghai fondata nel 2022 dall’ex vicepresidente di SenseTime, Yan Junjie, ha appena completato un’offerta pubblica iniziale da 619 milioni di dollari alla borsa di Hong Kong. Le azioni hanno raddoppiato il valore nel primo giorno di contrattazioni, raggiungendo una capitalizzazione di mercato di circa 13 miliardi di dollari. Gli investitori hanno sottoscritto l’offerta oltre 1.800 volte rispetto alle azioni disponibili. Il messaggio è inequivocabile: il mercato vede qualcosa che va oltre i numeri finanziari immediati.
Il modello che pensa come un architetto
MiniMax M2.5 è un modello basato su un’architettura a esperti misti, tecnicamente chiamata Mixture of Experts: sulla carta conta 230 miliardi di parametri totali, ma nella pratica ne attiva solo 10 miliardi per ogni singola query. È come avere una biblioteca immensa ma consultare solo gli scaffali pertinenti: si ottiene la conoscenza di un sistema massiccio con l’agilità di uno snello. La versione Lightning raggiunge velocità di 100 token al secondo, esattamente il doppio rispetto ai modelli di frontiera concorrenti. La versione standard si ferma a 50 token al secondo ma costa la metà.
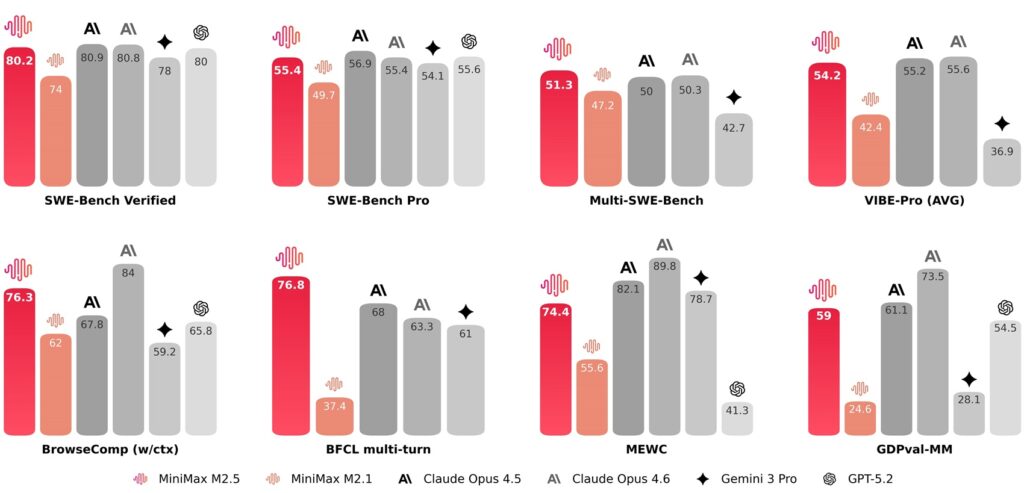
I numeri dei benchmark raccontano una storia precisa. Su SWE-Bench Verified, il test che misura la capacità di risolvere problemi reali su repository GitHub, M2.5 raggiunge l’80,2%. Claude Opus 4.6 si attesta all’80,8%, GPT-5.2 all’80%, Gemini 3 Pro al 78%. Siamo nell’ordine del punto percentuale di differenza, praticamente parità tecnica. Su Multi-SWE-Bench, che testa capacità di codifica multilingua su progetti complessi, M2.5 tocca il 51,3% superando Opus 4.6 fermo al 50,3%. Su BrowseComp, benchmark che valuta ricerca web e ragionamento contestuale, arriva al 76,3%.
Ma c’è un dettaglio comportamentale che emerge dall’analisi del modello e che MiniMax definisce “mentalità da architetto”. Prima di scrivere anche solo una riga di codice, M2.5 scompone autonomamente i requisiti del progetto, ne pianifica la struttura e disegna l’interfaccia. Non è retorica da comunicato stampa: è un pattern emerso spontaneamente durante l’addestramento tramite rinforzo condotto su oltre 200.000 ambienti reali diversi. Il modello non si limita a correggere bug o risolvere singoli problemi isolati, ma copre l’intero ciclo di sviluppo software: dalla progettazione iniziale del sistema alla revisione completa del codice, passando per configurazione degli ambienti, test e validazione. Supporta nativamente più di dieci linguaggi di programmazione, da Go a Python, da Rust a TypeScript, da C++ a Kotlin, e opera su piattaforme diverse: web, Android, iOS, Windows.
La questione del prezzo che cambia tutto
Qui la narrazione prende una piega diversa. MiniMax M2.5 Lightning costa 0,30 dollari per milione di token in input e 2,40 dollari per milione di token in output. La versione standard dimezza questi prezzi: 0,15 e 1,20 dollari rispettivamente. Claude Opus 4.6 costa 5 dollari in input e 25 dollari in output. Non è una differenza marginale da clausola contrattuale: è un rapporto di uno a venti sul costo di output, la differenza tra poter permettersi un esperimento e doverci rinunciare.
Tradotto in applicazioni concrete, un task tipico su SWE-Bench Verified consuma in media 3,52 milioni di token. Con M2.5 Lightning il costo si aggira sugli 8,45 dollari a task completato. Con Claude Opus 4.6 siamo oltre i 260 dollari per ottenere esattamente lo stesso risultato. L’efficienza emerge anche dalla velocità di esecuzione: M2.5 completa i task SWE-Bench in 22,8 minuti in media, il 37% più rapido rispetto al predecessore M2.1. Il tempo di esecuzione è identico a quello di Claude Opus 4.6, ma al 10% del costo totale.
MiniMax sintetizza la proposta con una formula che richiama il sogno dell’energia atomica degli anni Cinquanta: “intelligenza troppo economica per essere misurata”. Mantenere M2.5 Lightning attivo continuamente per un’ora, generando 100 token al secondo in modo ininterrotto, costa esattamente un dollaro. A 50 token al secondo, il prezzo scende a 30 centesimi. Con un budget di 10.000 dollari si possono far girare quattro istanze del modello ininterrottamente per un anno intero. Non è una speculazione teorica da comunicato stampa: l’azienda stessa usa M2.5 internamente su scala produttiva. Il 30% delle attività complessive viene gestito autonomamente dal modello, coprendo ricerca e sviluppo, prodotto, vendite, risorse umane, finanza. Nell’ambito specifico della programmazione, l’80% del codice nuovo inviato al repository aziendale è generato da M2.5.
Applicazioni pratiche oltre il codice
Il design di M2.5 non si limita alla programmazione. Il modello è stato addestrato su scenari d’ufficio reali, collaborando direttamente con professionisti senior in finanza, diritto e scienze sociali. Questi esperti hanno progettato requisiti specifici, fornito feedback dettagliato durante lo sviluppo, definito standard qualitativi precisi, contribuito direttamente alla costruzione dei dati di addestramento. L’obiettivo era incorporare nel modello la conoscenza tacita dei rispettivi settori, quel tipo di sapere procedurale che non si trova scritto nei manuali ma si acquisisce con anni di pratica quotidiana.
MiniMax ha costruito un framework di valutazione interno chiamato GDPval-MM che giudica non solo la qualità del prodotto finale consegnato ma anche la professionalità del percorso compiuto dall’agente per arrivarci, monitorando al contempo i costi in token dell’intero flusso di lavoro per stimare i reali guadagni di produttività del modello. Nei confronti diretti con altri modelli mainstream attraverso comparazioni a coppie, M2.5 ha raggiunto un tasso di vittoria medio del 59%. Sulla piattaforma MiniMax Agent, che integra nativamente il modello, gli utenti hanno costruito oltre 10.000 esperti personalizzati in pochi giorni dal rilascio, combinando competenze specifiche di dominio con le abilità di base del sistema.
Su ricerca web e chiamata di strumenti, M2.5 dimostra una maturità decisionale superiore rispetto ai predecessori. Non si limita a “fare le cose correttamente”, cerca attivamente percorsi più efficienti per risolvere i problemi assegnati. Su task come BrowseComp, Wide Search e RISE ha ridotto il consumo di turni di circa il 20% rispetto a M2.1, raggiungendo risultati migliori con maggiore efficienza in termini di token consumati. È un segnale importante: il modello non accumula passaggi ridondanti per coprirsi da potenziali errori, ma naviga con più precisione e determinazione verso la soluzione ottimale.
L’IPO e il contesto finanziario
L’offerta pubblica iniziale di gennaio 2026 a Hong Kong rappresenta molto più di un semplice evento finanziario nel calendario delle quotazioni. MiniMax ha raccolto 619 milioni di dollari vendendo 29,2 milioni di azioni a 165 dollari di Hong Kong ciascuna, esattamente al limite superiore della fascia indicativa comunicata agli investitori. Il titolo ha chiuso il primo giorno di contrattazioni a 345 dollari di Hong Kong, con un rialzo del 109% che ha fatto schizzare la capitalizzazione di mercato a circa 13 miliardi di dollari. La domanda è stata letteralmente travolgente: 1.837 volte l’offerta pubblica destinata al mercato retail, 37 volte il collocamento internazionale.
Quattordici investitori cornerstone hanno impegnato 350 milioni di dollari prima ancora della quotazione pubblica. L’Abu Dhabi Investment Authority porta capitale sovrano mediorientale interessato alle tecnologie emergenti, Alibaba detiene il 13,66% della società portando con sé l’intero ecosistema tecnologico cinese consolidato, Mirae Asset Securities rappresenta gli interessi sudcoreani nel settore AI. MiHoYo, lo sviluppatore del videogioco Genshin Impact e investitore angel in MiniMax sin dalle origini della startup, possiede il 6,4% della società per un valore che a capitalizzazione attuale si aggira sui 615 milioni di dollari. Altri azionisti di peso includono Tencent, Hillhouse Capital, Sequoia China e IDG.
La valutazione post-IPO di 6,5 miliardi di dollari rappresenta una crescita sostanziale rispetto ai 4,2 miliardi del precedente round di finanziamento privato. Ma dietro l’euforia delle contrattazioni del primo giorno ci sono numeri che raccontano una storia più complessa. Nei primi tre quarti del 2025 MiniMax ha registrato ricavi per 53 milioni di dollari contro perdite nette di 512 milioni. L’azienda si trova nella fase ad alto investimento tipica delle startup AI, quella fase critica in cui si brucia capitale a ritmo sostenuto per costruire rapidamente posizione di mercato. I ricavi crescono ma i costi per infrastruttura cloud e ricerca divorano capitale ancora più rapidamente.
La traiettoria geopolitica
MiniMax si inserisce in un panorama competitivo che sta ridefinendo gli equilibri globali dell’intelligenza artificiale. Zhipu AI, altro player cinese dei modelli linguistici di grandi dimensioni, ha debuttato in borsa a Hong Kong un giorno prima di MiniMax, raccogliendo 558 milioni di dollari con un rialzo del 13% al primo giorno. Il mercato sta assistendo a una vera corsa delle startup AI cinesi verso i mercati pubblici, spinta dal sostegno di Pechino al settore tecnologico domestico e dalla necessità di finanziamenti massivi per competere su scala globale con i giganti occidentali.
Questa accelerazione arriva mentre le aziende americane del calibro di OpenAI e Anthropic stanno ancora lavorando ai preparativi per le loro offerte pubbliche. OpenAI ha convertito la divisione a scopo di lucro in una società a beneficio pubblico nel settembre 2025, segnalando l’intenzione di quotarsi ma senza ancora una data precisa. Anthropic ha ingaggiato uno studio legale per avviare il processo il mese scorso, con analisti che ipotizzano un debutto possibile entro l’anno. Ma intanto i concorrenti cinesi hanno già raccolto miliardi sui mercati pubblici e stanno consolidando valutazioni di mercato significative.
L’embargo americano sui chip avanzati rappresenta il contesto geopolitico inevitabile di questa storia. Le restrizioni imposte da Washington limitano l’accesso cinese a GPU di ultima generazione, costringendo gli sviluppatori a lavorare con hardware H800 e H20, versioni deliberatamente depotenziare rispetto agli A100 e H100 disponibili liberamente in Occidente. La risposta cinese è stata duplice e coordinata: da un lato ottimizzazione software spinta al limite fisico delle possibilità, dall’altro strategie open-source aggressive che trasformano un vincolo in opportunità. MiniMax ha rilasciato i pesi completi del modello su Hugging Face sotto licenza MIT modificata che richiede solo la visualizzazione della dicitura “MiniMax M2.5” nelle applicazioni, con codice sorgente disponibile anche su GitHub. È lo stesso approccio già visto con DeepSeek, Qwen, Kimi: trasparenza forzata dalle circostanze che si trasforma in vantaggio competitivo.
Architettura tecnica e addestramento
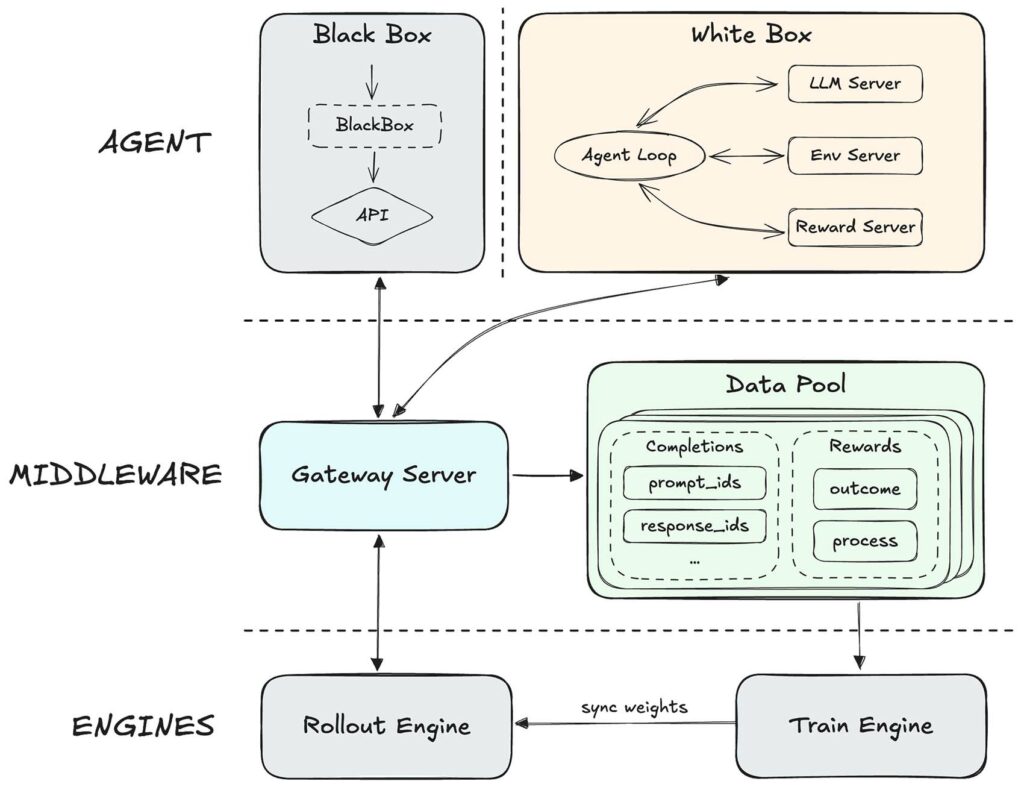
L’architettura a esperti misti non è una novità assoluta nel panorama dei modelli linguistici, ma MiniMax l’ha affinata con un framework proprietario di apprendimento tramite rinforzo chiamato Forge. Il sistema introduce un livello intermedio che disaccoppia completamente il motore di addestramento e inferenza dall’agente vero e proprio, supportando l’integrazione di agenti arbitrari e consentendo di ottimizzare la generalizzazione del modello tra diversi scaffold di agenti e strumenti. Una strategia di fusione strutturata ad albero per i campioni ha prodotto un’accelerazione di circa 40 volte rispetto agli approcci precedenti.
Sul fronte algoritmico, l’azienda ha continuato a utilizzare CISPO, algoritmo proprietario proposto all’inizio del 2025 per garantire la stabilità dei modelli a esperti misti durante l’addestramento su larga scala. Lightning Attention, l’altra componente tecnica rilevante dell’architettura, consente al modello di gestire finestre di contesto fino a 204.800 token, con l’architettura sottostante che supporta teoricamente fino a un milione di token. La capacità di output arriva a 128.000 token.
Open-source e sicurezza dei dati
La decisione di rilasciare i pesi completi del modello in open-source presenta vantaggi e rischi che meritano un’analisi equilibrata. Sul fronte positivo troviamo l’accessibilità per sviluppatori e ricercatori indipendenti, la possibilità concreta di condurre audit di sicurezza trasparenti, la costruzione di una community globale che può contribuire al miglioramento continuo. Sul fronte negativo persistono preoccupazioni legittime sulla residenza fisica dei dati elaborati, potenziali bias incorporati durante l’addestramento su dataset cinesi, questioni complesse di allineamento del modello rispetto a valori culturali diversi.
Il prospetto IPO di MiniMax rivela che solo il 26% dei ricavi dell’azienda proviene dalla Cina continentale, il 20% dagli Stati Uniti, il resto da Singapore e altri mercati internazionali. La base utenti mensile attiva è passata da 3,1 milioni nel 2023 a 27,6 milioni a settembre 2025. Sono numeri che dipingono un modello con ambizioni e presenza globali, non un campione puramente domestico confinato al mercato cinese.
Ma per aziende e organizzazioni europee che valutano concretamente l’adozione di M2.5, la provenienza geografica del modello solleva domande che non possono essere ignorate. Dove risiedono fisicamente i dati elaborati dalle API? Quali garanzie concrete esistono contro potenziali accessi non autorizzati da parte di autorità governative? La licenza open-source permette il deployment completamente locale, mitigando alcuni di questi rischi attraverso il controllo diretto dell’infrastruttura, ma non elimina completamente le preoccupazioni sulla supply chain del software.
MiniMax ha pubblicato metriche di allineamento che mostrano una riduzione del 41% negli errori di allucinazione rispetto a M2.1 sul benchmark AA-Omniscience, attestandosi comunque a un punteggio di -30 contro il -41 di Opus 4.6. Il gap è significativo ma probabilmente non proibitivo per molte applicazioni pratiche meno critiche.
Sostenibilità economica e futuro
Il modello di business low-cost di MiniMax solleva interrogativi profondi sulla sostenibilità a lungo termine dell’intera operazione. Vendere intelligenza artificiale di frontiera a un ventesimo del prezzo dei concorrenti occidentali funziona brillantemente come strategia di acquisizione utenti e penetrazione di mercato, ma può reggere davvero quando l’azienda dovrà mostrare agli investitori un percorso credibile verso la profitabilità? MiniMax ha speso oltre 150 milioni di dollari in servizi cloud nel 2025, con ricerca e sviluppo che hanno consumato circa 250 milioni aggiuntivi. Fanno 400 milioni di dollari annui bruciati solo per rimanere competitivi nella corsa tecnologica globale.
La risposta dell’azienda potrebbe risiedere in una combinazione intelligente di volume massiccio ed efficienza tecnica spinta. Se il prezzo abbatte drasticamente le barriere all’adozione, il numero totale di utenti e applicazioni può scalare molto rapidamente, compensando i margini sottili con i volumi. Ma c’è comunque un limite fisico oltre il quale la matematica smette semplicemente di tornare: le GPU hanno un costo reale, l’energia elettrica ha un costo reale, l’ingegneria di sistema ha un costo reale. La pressione sui margini finirà inevitabilmente per mordere.
L’IPO fornisce comunque una finestra temporale preziosa. I 619 milioni di dollari raccolti comprano runway operativo per almeno un paio d’anni, permettono investimenti massicci in scaling dell’infrastruttura, danno respiro per perfezionare sia il modello sia l’offerta commerciale complessiva. Ma la capitalizzazione di mercato da 13 miliardi di dollari implica aspettative molto elevate sui risultati futuri.
Implicazioni per il mercato europeo
Per sviluppatori e aziende italiane ed europee che valutano concretamente l’adozione di nuove tecnologie AI, M2.5 rappresenta un’opzione che merita valutazione attenta e ponderata. Il rapporto qualità-prezzo è oggettivamente innegabile guardando i numeri puri. La possibilità di deployment completamente locale tramite i pesi open-source mitiga alcune delle preoccupazioni più pressanti sulla privacy dei dati. Ma esistono trade-off reali da considerare con attenzione: la documentazione disponibile è prevalentemente in inglese e cinese, il supporto enterprise dedicato è ancora meno maturo rispetto ai fornitori occidentali consolidati come Anthropic o OpenAI.
D’altra parte, il costo drammaticamente inferiore permette sperimentazioni che sarebbero semplicemente proibitive economicamente con Claude Opus o GPT-5 ai prezzi attuali. Per startup innovative e piccole medie imprese con vincoli di budget stringenti, la differenza pratica tra spendere 1.000 euro al mese e spendere 20.000 euro al mese può letteralmente determinare la fattibilità stessa di un progetto ambizioso o la sua morte prematura.
La questione geopolitica più ampia rimane comunque sullo sfondo ma non scompare affatto. L’Unione Europea sta lavorando intensamente su AI Act e Digital Services Act, cercando faticosamente di bilanciare innovazione tecnologica e protezione dei cittadini. Come si inseriscono esattamente i modelli cinesi open-source in questo framework regolatorio ancora in evoluzione? Le risposte definitive non sono ancora del tutto chiare, ma le domande sono assolutamente legittime e necessarie per una valutazione responsabile.
Domande ancora aperte
MiniMax M2.5 arriva sul mercato in un momento storico particolarmente delicato per l’industria dell’intelligenza artificiale. L’euforia iniziale per i modelli linguistici di grandi dimensioni persiste certamente, ma cresce in parallelo anche uno scetticismo sempre più diffuso sui costi astronomici e sui risultati concreti effettivamente misurabili. Le aziende vogliono vedere ritorni tangibili sull’investimento in AI, non solo demo tecniche impressionanti da mostrare agli investitori.
Quanto è davvero robusto il modello in scenari di produzione complessi non previsti esplicitamente durante l’addestramento? Come gestisce concretamente edge case inattesi, requisiti inusuali specifici di domini particolari, contesti profondamente ambigui che richiedono giudizio umano? I benchmark standardizzati catturano inevitabilmente solo una dimensione ristretta della qualità complessiva di un sistema AI. L’uso reale in produzione espone complessità e sfide che nessun test controllato può anticipare completamente. Serviranno mesi di deployment su scala industriale per avere un quadro davvero definitivo.
La competizione globale nell’intelligenza artificiale si sta spostando rapidamente da “chi costruisce il cervello più grande” verso “chi costruisce il cervello più utile e accessibile al maggior numero di utenti”. È un cambio di paradigma profondo che favorisce sistematicamente efficienza operativa, ottimizzazione intelligente delle risorse, ingegnerizzazione attenta dei sistemi rispetto alla pura potenza computazionale bruta. In questo scenario in evoluzione, i vincoli hardware imposti dall’embargo americano potrebbero rivelarsi, paradossalmente, un vantaggio competitivo duraturo e strutturale per l’intero ecosistema cinese dell’AI.
Il futuro della leadership tecnologica nell’intelligenza artificiale potrebbe quindi non essere determinato principalmente da chi possiede i chip più potenti e avanzati, ma piuttosto da chi riesce concretamente a fare di più con meno risorse. MiniMax M2.5 è un segnale preciso e inequivocabile in questa direzione strategica.
