
There is a red thread running through the last six months of Chinese artificial intelligence development, and it runs parallel to the geography of trade restrictions imposed by Washington. Every time we think we have drawn the boundaries of innovation possible under a hardware embargo, a new model rewrites the rules of the game. It happened with Kimi K2.5 in December, with Qwen 3 in January, with DeepSeek MHC a few weeks ago. Now it’s the turn of MiniMax M2.5, a model that arrives on the market with a proposal as simple as it is destabilizing: frontier model performance at a tenth of the price of Western competition.
The launch on February 12, 2026, fits into a trajectory we have been documenting for months: the Chinese ecosystem’s ability to transform the limits imposed by restrictions on advanced chips into innovation accelerators. MiniMax, a Shanghai startup founded in 2022 by former SenseTime vice president Yan Junjie, has just completed a 619 million dollar initial public offering on the Hong Kong stock exchange. The shares doubled in value on the first day of trading, reaching a market capitalization of about 13 billion dollars. Investors subscribed to the offer more than 1,800 times compared to the available shares. The message is unmistakable: the market sees something beyond the immediate financial numbers.

The model that thinks like an architect
MiniMax M2.5 is a model based on a mixed expert architecture, technically called Mixture of Experts: on paper it has 230 billion total parameters, but in practice it only activates 10 billion for each single query. It’s like having an immense library but only consulting the relevant shelves: you get the knowledge of a massive system with the agility of a lean one. The Lightning version reaches speeds of 100 tokens per second, exactly double compared to competing frontier models. The standard version stops at 50 tokens per second but costs half as much.
Benchmark numbers tell a precise story. On SWE-Bench Verified, the test that measures the ability to solve real problems on GitHub repositories, M2.5 reaches 80.2%. Claude Opus 4.6 stands at 80.8%, GPT-5.2 at 80%, Gemini 3 Pro at 78%. We are in the order of a percentage point of difference, practically technical parity. On Multi-SWE-Bench, which tests multilingual coding capabilities on complex projects, M2.5 touches 51.3%, surpassing Opus 4.6 which is at 50.3%. On BrowseComp, a benchmark evaluating web research and contextual reasoning, it reaches 76.3%.
But there is a behavioral detail that emerges from the model analysis and that MiniMax defines as an “architect mindset.” Before writing even a single line of code, M2.5 autonomously decomposes project requirements, plans its structure, and designs the interface. This is not press release rhetoric: it’s a pattern that emerged spontaneously during reinforcement training conducted on over 200,000 different real environments. The model does not limit itself to fixing bugs or solving isolated single problems but covers the entire software development cycle: from initial system design to complete code review, through environment configuration, testing, and validation. It natively supports more than ten programming languages, from Go to Python, from Rust to TypeScript, from C++ to Kotlin, and operates on different platforms: web, Android, iOS, Windows.
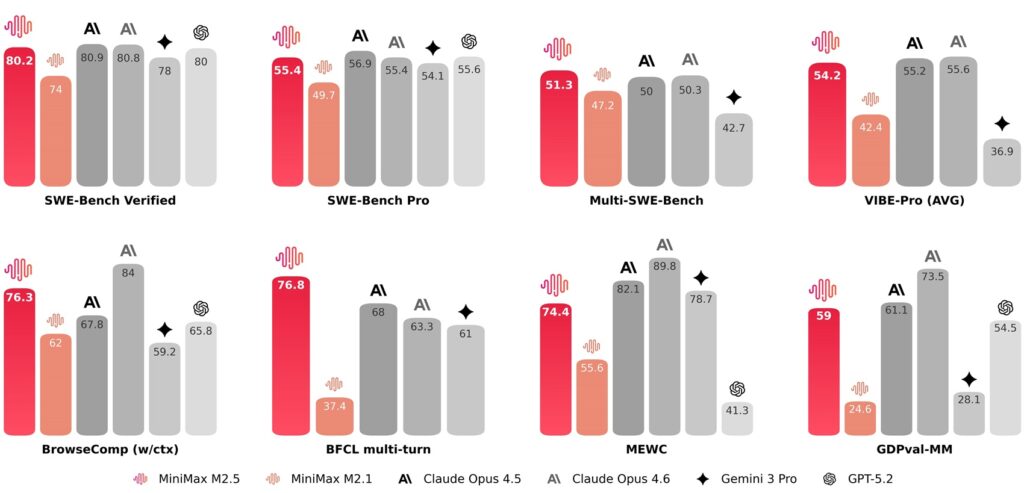
The price issue that changes everything
Here the narrative takes a different turn. MiniMax M2.5 Lightning costs $0.30 per million input tokens and $2.40 per million output tokens. The standard version halves these prices: $0.15 and $1.20 respectively. Claude Opus 4.6 costs $5 for input and $25 for output. It’s not a marginal difference from a contract clause: it’s a one-to-twenty ratio on output cost, the difference between being able to afford an experiment and having to give it up.
Translated into concrete applications, a typical task on SWE-Bench Verified consumes an average of 3.52 million tokens. With M2.5 Lightning, the cost is around $8.45 per completed task. With Claude Opus 4.6 we are over $260 to get exactly the same result. Efficiency also emerges from execution speed: M2.5 completes SWE-Bench tasks in 22.8 minutes on average, 37% faster than its predecessor M2.1. Execution time is identical to that of Claude Opus 4.6, but at 10% of the total cost.
MiniMax summarizes the proposal with a formula that recalls the dream of atomic energy from the fifties: “intelligence too cheap to be metered.” Keeping M2.5 Lightning active continuously for an hour, generating 100 tokens per second uninterruptedly, costs exactly one dollar. At 50 tokens per second, the price drops to 30 cents. With a budget of 10,000 dollars, four instances of the model can be run uninterruptedly for an entire year. It’s not theoretical speculation from a press release: the company itself uses M2.5 internally on a production scale. 30% of overall activities are managed autonomously by the model, covering research and development, product, sales, human resources, finance. In the specific area of programming, 80% of new code submitted to the company repository is generated by M2.5.
Practical applications beyond code
The design of M2.5 is not limited to programming. The model was trained on real office scenarios, collaborating directly with senior professionals in finance, law, and social sciences. These experts designed specific requirements, provided detailed feedback during development, defined precise quality standards, and contributed directly to the construction of training data. The goal was to incorporate into the model the tacit knowledge of respective sectors, that type of procedural knowledge not found written in manuals but acquired with years of daily practice.
MiniMax built an internal evaluation framework called GDPval-MM that judges not only the quality of the final delivered product but also the professionalism of the path taken by the agent to get there, while monitoring token costs of the entire workflow to estimate real productivity gains of the model. In direct comparisons with other mainstream models through pairwise comparisons, M2.5 achieved an average win rate of 59%. On the MiniMax Agent platform, which natively integrates the model, users have built over 10,000 custom experts in a few days from release, combining domain-specific expertise with basic system skills.
On web research and tool calling, M2.5 demonstrates superior decision-making maturity compared to predecessors. It doesn’t just “do things correctly,” it actively searches for more efficient paths to solve assigned problems. On tasks like BrowseComp, Wide Search, and RISE, it reduced turn consumption by about 20% compared to M2.1, reaching better results with greater efficiency in terms of tokens consumed. It’s an important signal: the model doesn’t accumulate redundant steps to cover itself from potential errors but navigates with more precision and determination towards the optimal solution.
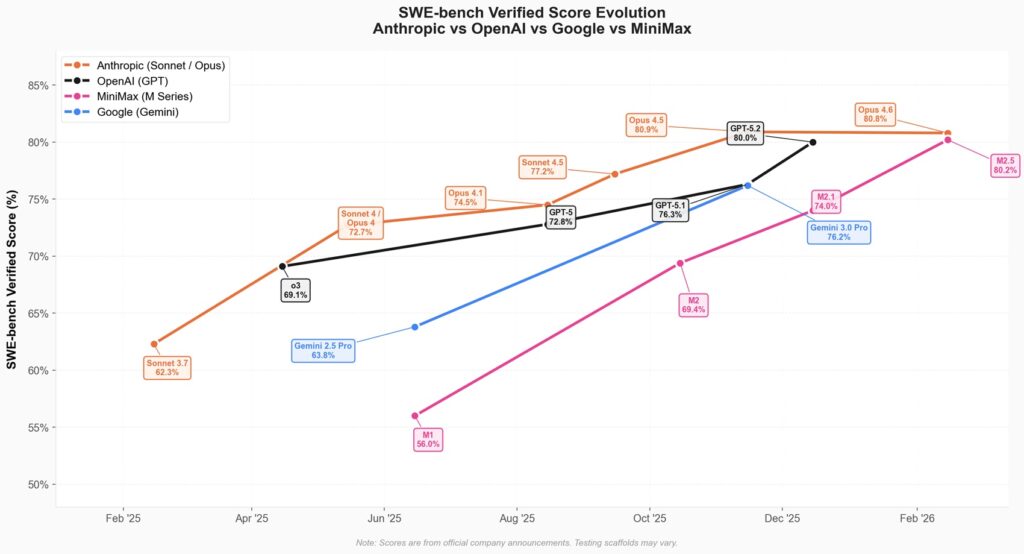
The IPO and the financial context
The January 2026 initial public offering in Hong Kong represents much more than a simple financial event in the listing calendar. MiniMax raised 619 million dollars selling 29.2 million shares at 165 Hong Kong dollars each, exactly at the upper limit of the indicative range communicated to investors. The stock closed the first day of trading at 345 Hong Kong dollars, with a 109% increase that sent the market capitalization to about 13 billion dollars. Demand was literally overwhelming: 1,837 times the public offer intended for the retail market, 37 times the international placement.
Fourteen cornerstone investors committed 350 million dollars even before the public listing. The Abu Dhabi Investment Authority brings Middle Eastern sovereign capital interested in emerging technologies, Alibaba holds 13.66% of the company bringing with it the entire consolidated Chinese technology ecosystem, Mirae Asset Securities represents South Korean interests in the AI sector. MiHoYo, developer of the video game Genshin Impact and angel investor in MiniMax since the startup’s origins, owns 6.4% of the company for a value that at current capitalization is around 615 million dollars. Other heavyweight shareholders include Tencent, Hillhouse Capital, Sequoia China, and IDG.
The post-IPO valuation of 6.5 billion dollars represents substantial growth compared to the 4.2 billion of the previous private funding round. But behind the first day’s trading euphoria there are numbers telling a more complex story. In the first three quarters of 2025 MiniMax recorded revenues of 53 million dollars against net losses of 512 million. The company is in the high investment phase typical of AI startups, that critical phase where capital is burned at a sustained rate to quickly build market position. Revenues grow but costs for cloud infrastructure and research devour capital even more rapidly.
The geopolitical trajectory
MiniMax fits into a competitive landscape that is redefining global balances of artificial intelligence. Zhipu AI, another Chinese player in large language models, debuted on the Hong Kong stock exchange a day before MiniMax, raising 558 million dollars with a 13% increase on the first day. The market is witnessing a real rush of Chinese AI startups towards public markets, driven by Beijing’s support for the domestic technological sector and the need for massive funding to compete on a global scale with Western giants.
This acceleration comes while American companies like OpenAI and Anthropic are still working on preparations for their public offerings. OpenAI converted its for-profit division into a public benefit corporation in September 2025, signaling the intention to list but without a precise date yet. Anthropic hired a law firm to start the process last month, with analysts speculating a possible debut within the year. But meanwhile, Chinese competitors have already raised billions on public markets and are consolidating significant market valuations.
The American embargo on advanced chips represents the inevitable geopolitical context of this story. Restrictions imposed by Washington limit Chinese access to latest generation GPUs, forcing developers to work with H800 and H20 hardware, versions deliberately downgraded compared to A100 and H100 freely available in the West. The Chinese response was twofold and coordinated: on one hand software optimization pushed to the physical limit of possibilities, on the other aggressive open-source strategies transforming a constraint into opportunity. MiniMax released the complete model weights on Hugging Face under a modified MIT license that only requires displaying the wording “MiniMax M2.5” in applications, with source code also available on GitHub. It’s the same approach already seen with DeepSeek, Qwen, Kimi: transparency forced by circumstances that turns into competitive advantage.
Technical architecture and training
Mixed expert architecture is not an absolute novelty in the landscape of language models, but MiniMax refined it with a proprietary reinforcement learning framework called Forge. The system introduces an intermediate level that completely decouples the training and inference engine from the agent itself, supporting integration of arbitrary agents and allowing to optimize model generalization across different agent scaffolds and tools. A tree-structured sampling fusion strategy produced an acceleration of about 40 times compared to previous approaches.
On the algorithmic front, the company continued to use CISPO, a proprietary algorithm proposed in early 2025 to ensure stability of mixed expert models during large-scale training. Lightning Attention, the other relevant technical component of the architecture, allows the model to handle context windows up to 204,800 tokens, with the underlying architecture theoretically supporting up to one million tokens. Output capacity reaches 128,000 tokens.
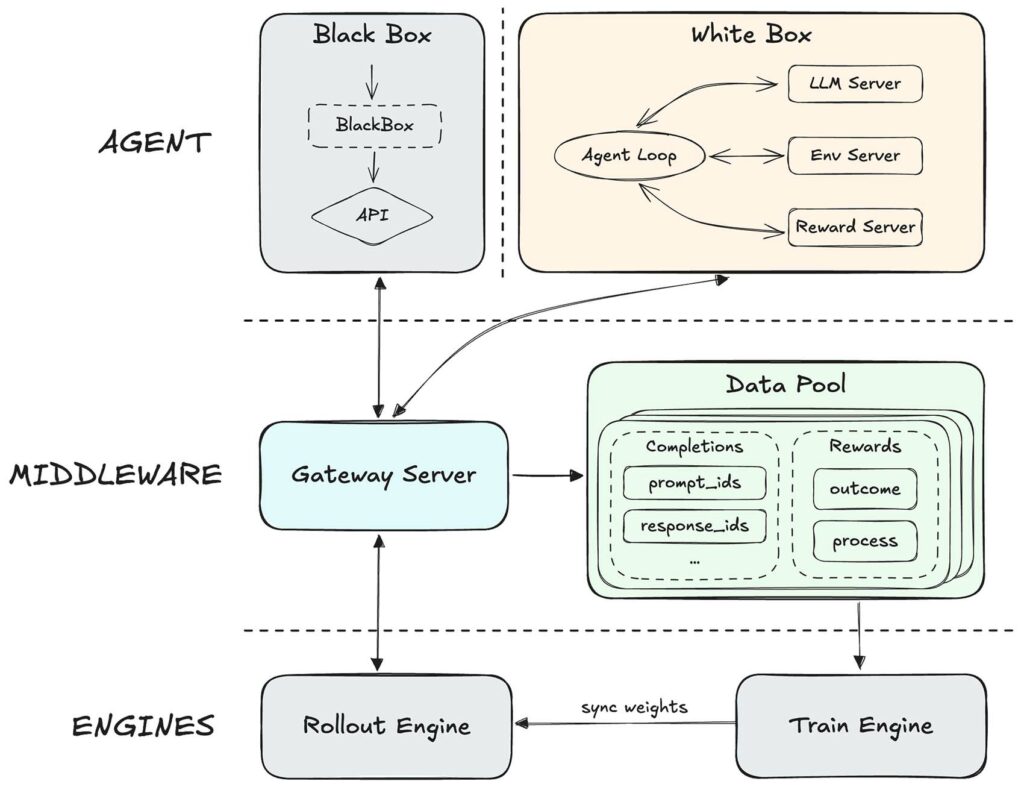
Open-source and data security
The decision to release the complete model weights in open-source presents advantages and risks that deserve balanced analysis. On the positive side we find accessibility for independent developers and researchers, the concrete possibility to conduct transparent security audits, the building of a global community that can contribute to continuous improvement. On the negative side, legitimate concerns persist about physical residency of processed data, potential biases incorporated during training on Chinese datasets, complex issues of model alignment with respect to different cultural values.
The MiniMax IPO prospectus reveals that only 26% of the company’s revenues come from mainland China, 20% from the United States, the rest from Singapore and other international markets. The monthly active user base went from 3.1 million in 2023 to 27.6 million in September 2025. These are numbers depicting a model with global ambitions and presence, not a purely domestic champion confined to the Chinese market.
But for European companies and organizations concretely evaluating M2.5 adoption, the model’s geographic origin raises questions that cannot be ignored. Where do the data processed by APIs physically reside? What concrete guarantees exist against potential unauthorized access by government authorities? The open-source license allows completely local deployment, mitigating some of these risks through direct infrastructure control, but does not completely eliminate concerns about the software supply chain.
MiniMax published alignment metrics showing a 41% reduction in hallucination errors compared to M2.1 on the AA-Omniscience benchmark, still settling at a score of -30 against the -41 of Opus 4.6. The gap is significant but probably not prohibitive for many less critical practical applications.
Economic sustainability and future
MiniMax’s low-cost business model raises deep questions about long-term sustainability of the entire operation. Selling frontier artificial intelligence at a twentieth of the price of Western competitors works brilliantly as a user acquisition and market penetration strategy, but can it really hold up when the company has to show investors a credible path to profitability? MiniMax spent over 150 million dollars in cloud services in 2025, with research and development consuming about an additional 250 million. That’s 400 million dollars annually burned just to stay competitive in the global technology race.
The company’s answer might lie in a clever combination of massive volume and extreme technical efficiency. If price drastically lowers adoption barriers, the total number of users and applications can scale very quickly, offsetting thin margins with volumes. But there is still a physical limit beyond which math simply stops adding up: GPUs have a real cost, electricity has a real cost, system engineering has a real cost. Pressure on margins will inevitably start to bite.
The IPO still provides a precious time window. The 619 million dollars raised buy operational runway for at least a couple of years, allow massive investments in infrastructure scaling, give breathing room to refine both the model and the overall commercial offering. But the 13 billion dollar market capitalization implies very high expectations on future results.
Implications for the European market
For Italian and European developers and companies concretely evaluating adoption of new AI technologies, M2.5 represents an option deserving careful and weighted evaluation. The quality-price ratio is objectively undeniable looking at pure numbers. The possibility of completely local deployment via open-source weights mitigates some of the most pressing data privacy concerns. But real trade-offs exist to consider carefully: available documentation is predominantly in English and Chinese, dedicated enterprise support is still less mature compared to consolidated Western providers like Anthropic or OpenAI.
On the other hand, the dramatically lower cost allows experiments that would be simply economically prohibitive with Claude Opus or GPT-5 at current prices. For innovative startups and small-medium enterprises with tight budget constraints, the practical difference between spending 1,000 euros a month and spending 20,000 euros a month can literally determine the very feasibility of an ambitious project or its premature death.
The broader geopolitical issue still remains in the background but does not disappear at all. The European Union is working intensively on the AI Act and Digital Services Act, laboriously trying to balance technological innovation and citizen protection. How exactly do Chinese open-source models fit into this still evolving regulatory framework? Definitive answers are not yet entirely clear, but the questions are absolutely legitimate and necessary for a responsible evaluation.
Still open questions
MiniMax M2.5 arrives on the market at a particularly delicate historical moment for the artificial intelligence industry. Initial euphoria for large language models certainly persists, but growing in parallel is also an increasingly widespread skepticism about astronomical costs and concrete, actually measurable results. Companies want to see tangible returns on AI investment, not just impressive technical demos to show investors.
How robust is the model really in complex production scenarios not explicitly foreseen during training? How does it concretely handle unexpected edge cases, unusual domain-specific requirements, deeply ambiguous contexts requiring human judgment? Standardized benchmarks inevitably capture only a narrow dimension of an AI system’s overall quality. Real use in production exposes complexities and challenges that no controlled test can completely anticipate. Months of industrial-scale deployment will be needed to have a truly definitive picture.
Global competition in artificial intelligence is rapidly shifting from “who builds the biggest brain” towards “who builds the most useful and accessible brain for the largest number of users.” It is a profound paradigm shift systematically favoring operational efficiency, intelligent resource optimization, and careful system engineering over pure brute computational power. In this evolving scenario, hardware constraints imposed by the American embargo might reveal themselves, paradoxically, as a lasting and structural competitive advantage for the entire Chinese AI ecosystem.
The future of technological leadership in artificial intelligence might therefore not be determined mainly by who owns the most powerful and advanced chips, but rather by who concretely manages to do more with fewer resources. MiniMax M2.5 is a precise and unmistakable signal in this strategic direction.



