
Working as Data Engineer makes you work with dates and time data a lot. Especially in the recent period where companies want to be Data-Driven, the software is Event-driven, your coffee machine is data-driven, and AI and ML require tons of data to work. In this article, I will share my experience working with date intervals in data warehouses and data lakes hoping to make your queries a little bit easier.
Motivation
Very often with modern software architecture like Event Driven Systems or with more legacy data warehouse or data lake modeling techniques we might end up having tables where each record has a validity period (i.e. a start date and an end date defining the interval where the record information is true in the system).

In a data warehouse and data lake context, modeling data using a type of slow-changing dimension (SCD) is quite a popular choice to track your data history. For example, suppose you have clients registry data, and each time a client changes his shipping address then you set the end_date of the previous shipping address and the start_date of the
new record with the timestamp the modification inside the address_tbl
| client_id | shipping_address | start_timestamp | end_timestamp |
|---|---|---|---|
| client_1 | 383 Trusel DriveNorth Andover, MA 01845 | 2015-01-14 00:00:00 | 2017-05-11 10:00:00 |
| client_1 | 91 Gates St. Valrico, FL 33594 | 2017-05-11 10:00:00 | 2999-01-01 23:59:59 |
Then you know that a client_1’s current shipping_address is the one satisfying the condition
SELECT *
FROM address_tbl
WHERE
client_id=client_1 and
address_tbl.start_date <= current_timestamp() < address_tbl.end_dateIn the case of an event-driven system you have the same pieces of information represented as events in the address_evt_tbl:
| client_id | shipping_address | event_timestamp |
|---|---|---|
| client_1 | 383 Trusel DriveNorth Andover, MA 01845 | 2015-01-14 00:00:00 |
| client_1 | 2015-01-14 00:00:00 | 2017-05-11 10:00:00 |
Then when you use that data for analytics or modeling in general you end up transforming the event table into a table with validity intervals with a query like:
WITH address_tbl AS(
SELECT client_id,
shipping_address,
event_timestamp AS start_timestamp,
COALESCE(LEAD(event_timestamp) OVER (PARTITION BY client_id ORDER BY event_timestamp), '2999-01-01 23:59:59') as
end_timestamp
FROM address_evt_tbl
)
--As before, you know that a client_1's current shipping_address is the one satisfying the condition
SELECT *
FROM address_tbl
WHERE
client_id=client_1 and
address_tbl.start_date <= current_timestamp() < address_tbl.end_date Code language: PHP (php)Now suppose you have another table called fav_payment_method telling your client’s favorite payment method:
| client_id | start_timestamp | end_timestamp | payment_method |
|---|---|---|---|
| client_1 | 2015-01-01 00:00:00 | 2016-01-01 00:00:00 | at_delivery_time |
| client_1 | 2016-01-01 00:00:00 | 2018-01-01 10:00:00 | paypal |
| client_1 | 2018-01-01 10:00:00 | 2019-01-01 23:00:00 | credit card |
| client_1 | 2019-01-01 23:00:00 | 2999-01-01 23:59:59 | Paypal |
And, don’t ask your Boss why, but you have to associate each client’s shipping address with his favorite payment method and how they evolve over time. What is the
best way to perform this operation in SQL or frameworks with SQL-like interface?
Naive solution
The first idea we have is to enumerate all the possibilities. For example, we might write:
SELECT *
FROM address_tbl at INNER JOIN fav_payment_method fpm
ON at.client_id = fpm.client_id
WHERE (at.start_timestamp >= fpm.start_timestamp AND
at.start_timestamp < fpm.end_timestamp) OR -- (1)
(at.end_timestamp >= fpm.start_timestamp AND
at.end_timestamp < fpm.end_timestamp) OR -- (2 )
(fpm.start_timestamp >= at.start_timestamp AND
fpm.start_timestamp < at.end_timestamp) OR -- (3)
(fpm.end_timestamp >= at.start_timestamp AND
fpm.end_timestamp < at.end_timestamp) -- (4)
Code language: HTML, XML (xml)That can be represented graphically with the following segments (address_tbl in red and fav_payment_method in blue)
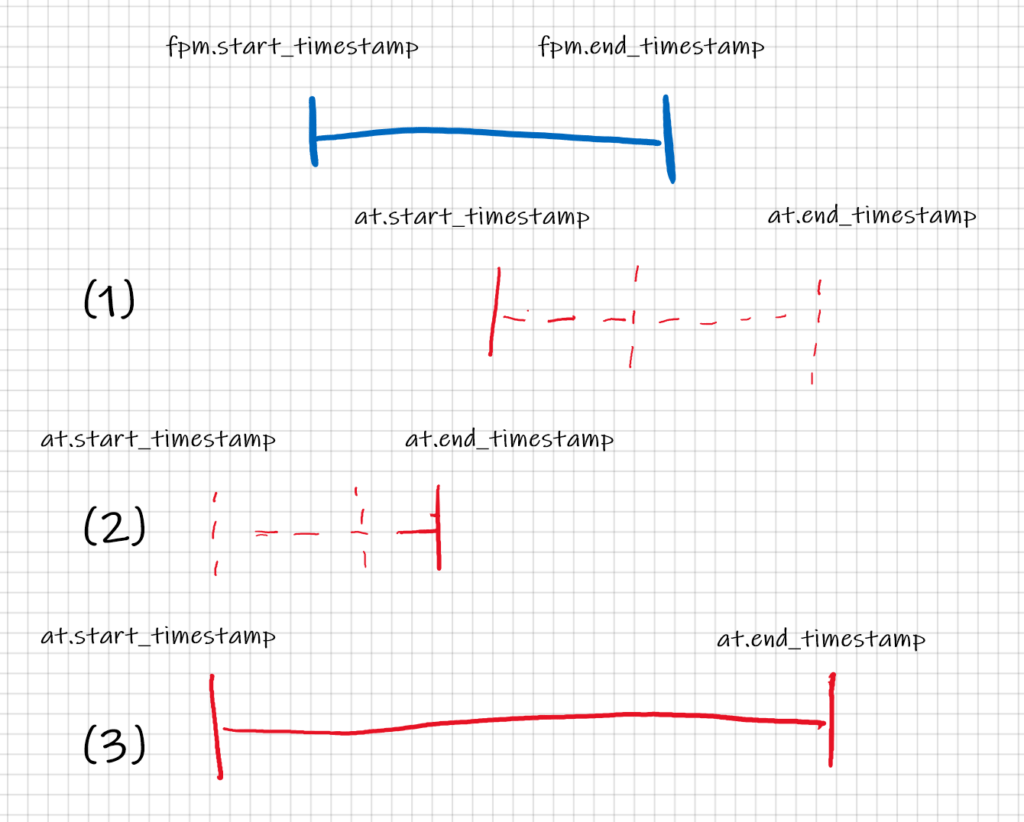
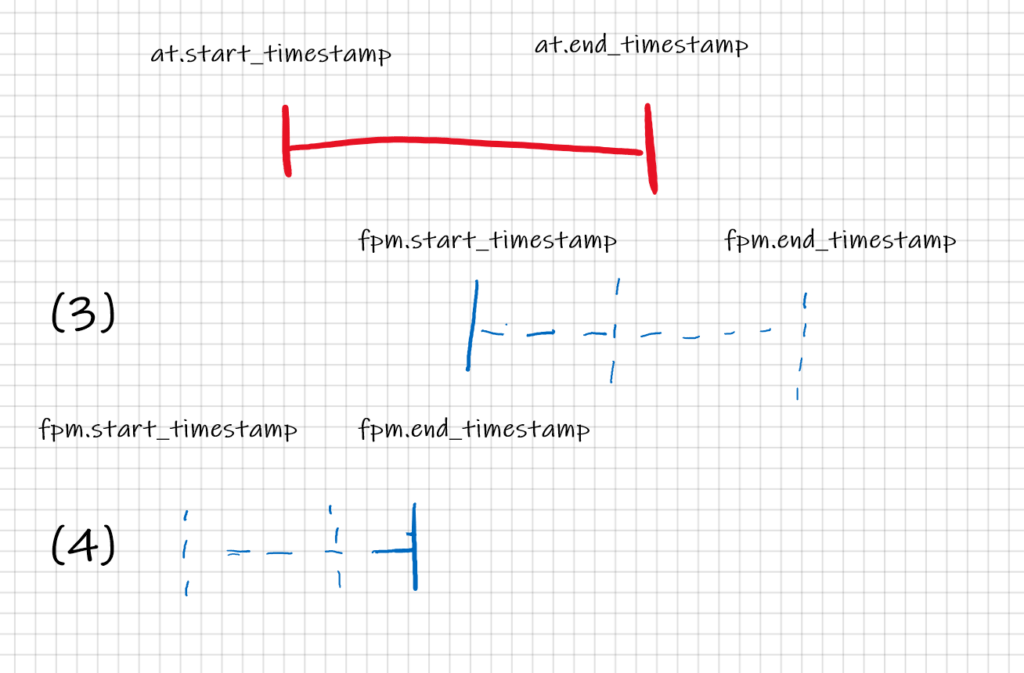
We can see that the query has a lot of conditions to match the records taking into account the validity periods and we are not even sure it covers all the cases. Do not mention the case when you inherit the code from a colleague who has quit the company and you have to interpret it…
Second try
But indeed we can be less naive than this. It turns out that the problem is a 1D segment intersection problem. Segments are your ranges of dates and you only need to take the periods that intersect. But how can we write that? And can we do it simply, maybe without enumerating all the possibilities? Well, we can say that two segments intersect if and only if they not(not intersect). Ah-ah, simple right?
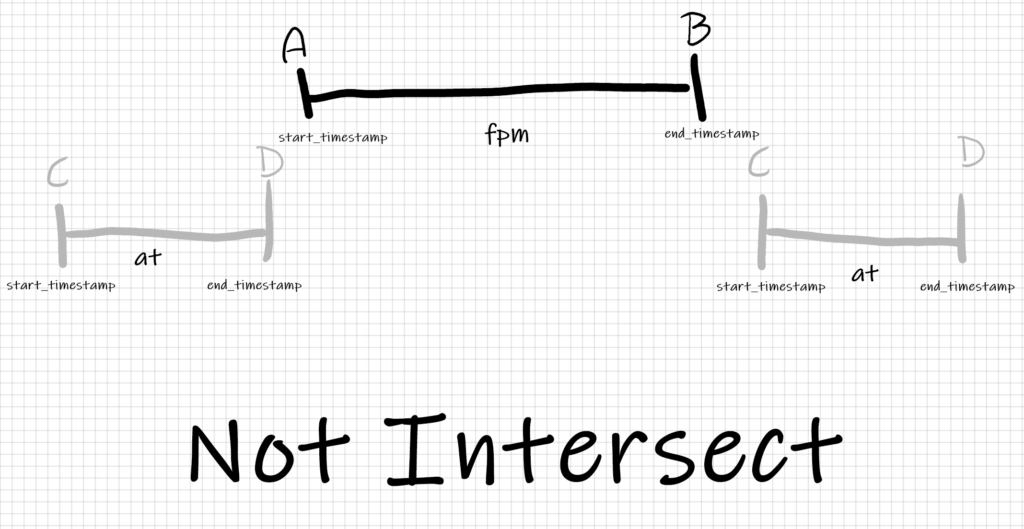
In the image we can see there isn’t an intersection when:
at.start_timestamp > fpm.end_timestamp or at.end_timestamp < fpm.start_timestampCode language: CSS (css)This also means that negating this condition we obtain not(not intersect)
at.start_timestamp <= fpm.end_timestamp and at.end_timestamp >= fpm.start_timestampCode language: HTML, XML (xml)And we can finally write a simple, clean and concise query that does exactly what we wanted:
SELECT *
FROM address_tbl at INNER JOIN fav_payment_method fpm
ON at.client_id = fpm.client_id
WHERE at.start_timestamp <= fpm.end_timestamp and
at.end_timestamp >= fpm.start_timestampCode language: HTML, XML (xml)| fpm.client_id | fpm.start_timestamp | fpm.end_timestamp | fpm.payment_method | at.client_id | at.shipping_address | at.start_timestamp | at.end_times |
|---|---|---|---|---|---|---|---|
| client_1 | 2015-01-01 00:00:00 | 2016-01-01 00:00:00 | at_delivery_time | client_1 | 383 Trusel DriveNorth Andover, MA 01845 | 2015-01-14 00:00:00 | 2017-05-11 10:00:00 |
| client_1 | 2016-01-01 00:00:00 | 2018-01-01 10:00:00 | paypal | client_1 | 383 Trusel DriveNorth Andover, MA 01845 | 2015-01-14 00:00:00 | 2017-05-11 10:00:00 |
| client_1 | 2016-01-01 00:00:00 | 2018-01-01 10:00:00 | paypal | client_1 | 91 Gates St. Valrico, FL 33594 | 2017-05-11 10:00:00 | 2999-01-01 23:59:59 |
| client_1 | 2018-01-01 10:00:00 | 2019-01-01 23:00:00 | credit card | client_1 | 91 Gates St. Valrico, FL 33594 | 2017-05-11 10:00:00 | 2999-01-01 23:59:59 |
| client_1 | 2019-01-01 23:00:00 | 2999-01-01 23:59:59 | paypal | client_1 | 91 Gates St. Valrico, FL 33594 | 2017-05-11 10:00:00 | 2999-01-01 23:59:59 |
Display them nicely
So far so good, but then the final table is a mess, there are four timestamps, what should we do next? We should go one step further and give unique, continuous, and
coherent validity intervals. But how?
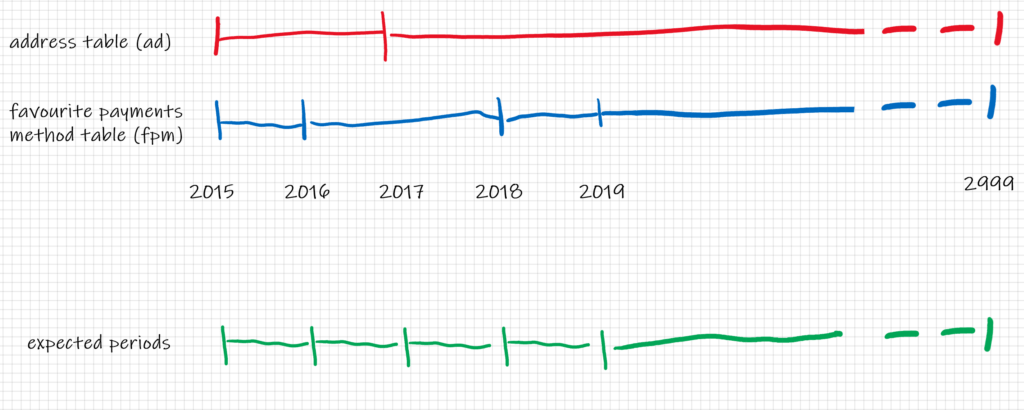
Looking at the picture we can compute the intersection of the date segments to get the new periods for each record. The intersection of 1D segments is $$
intersection_start_timestamp = max(ad.start_timestamp, fpm.start_timestamp)$$ and $$ intersection_end_timestamp = min(ad.end_timestamp, fpm.end_timestamp)$$
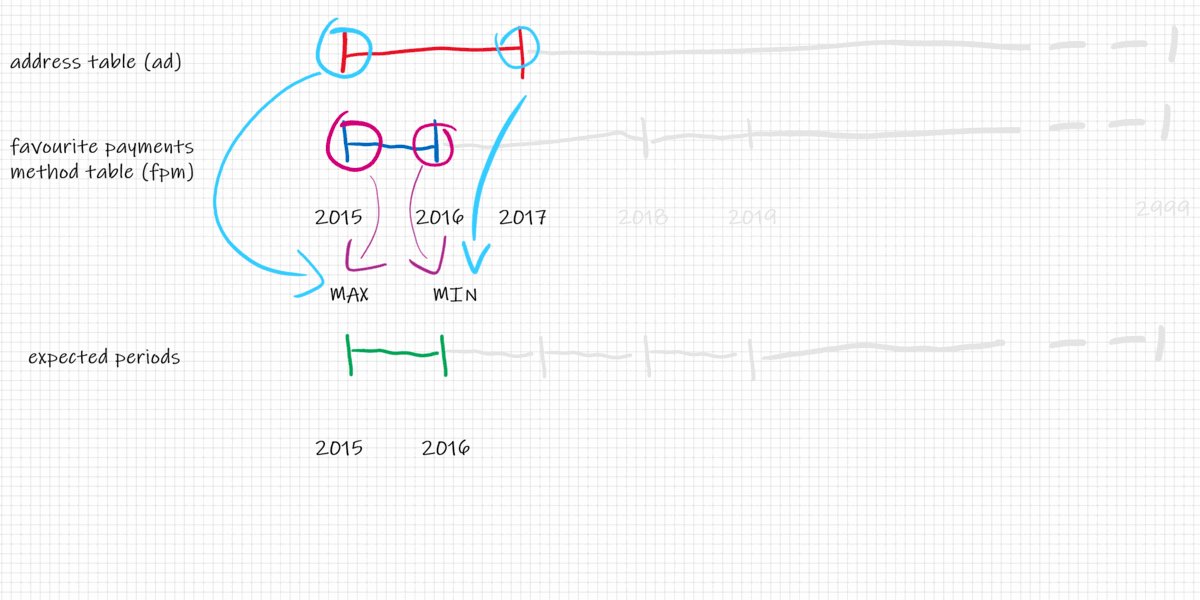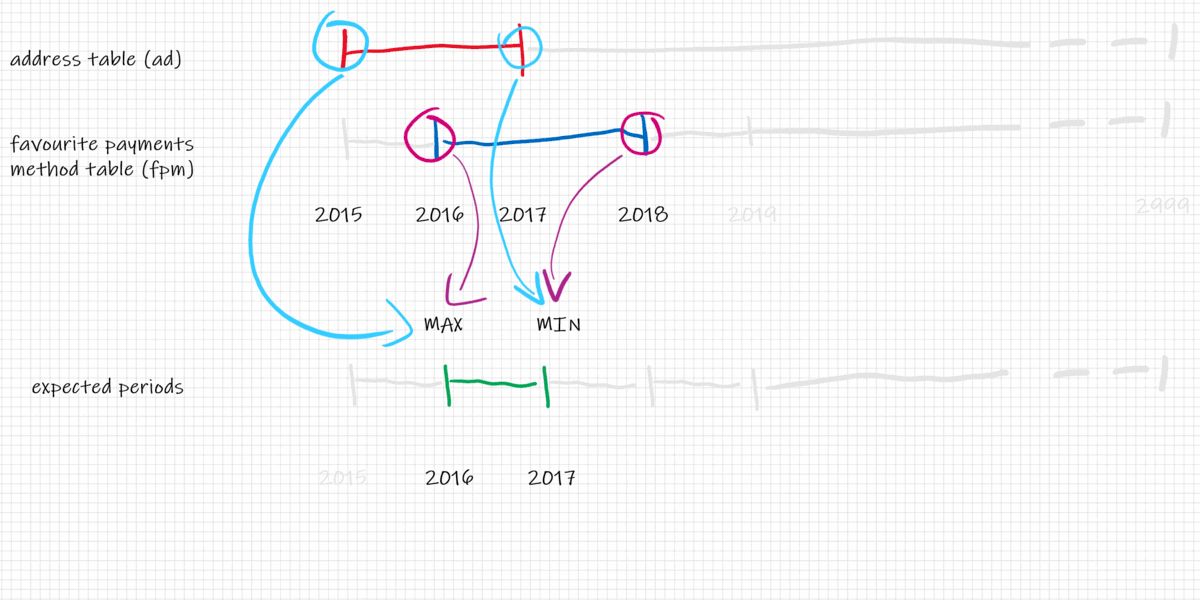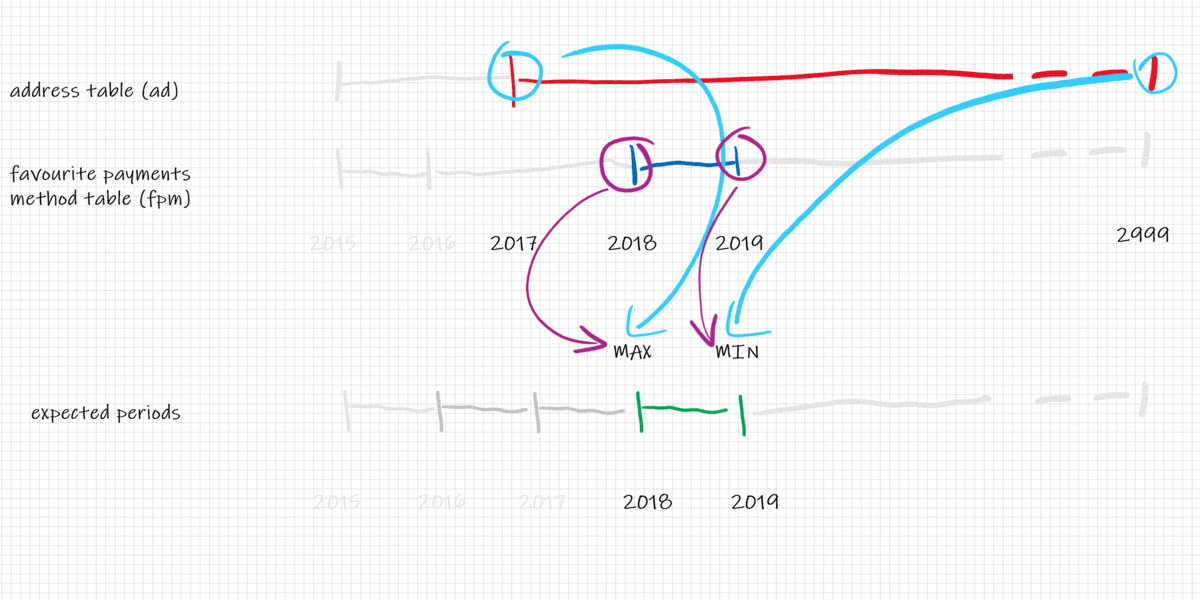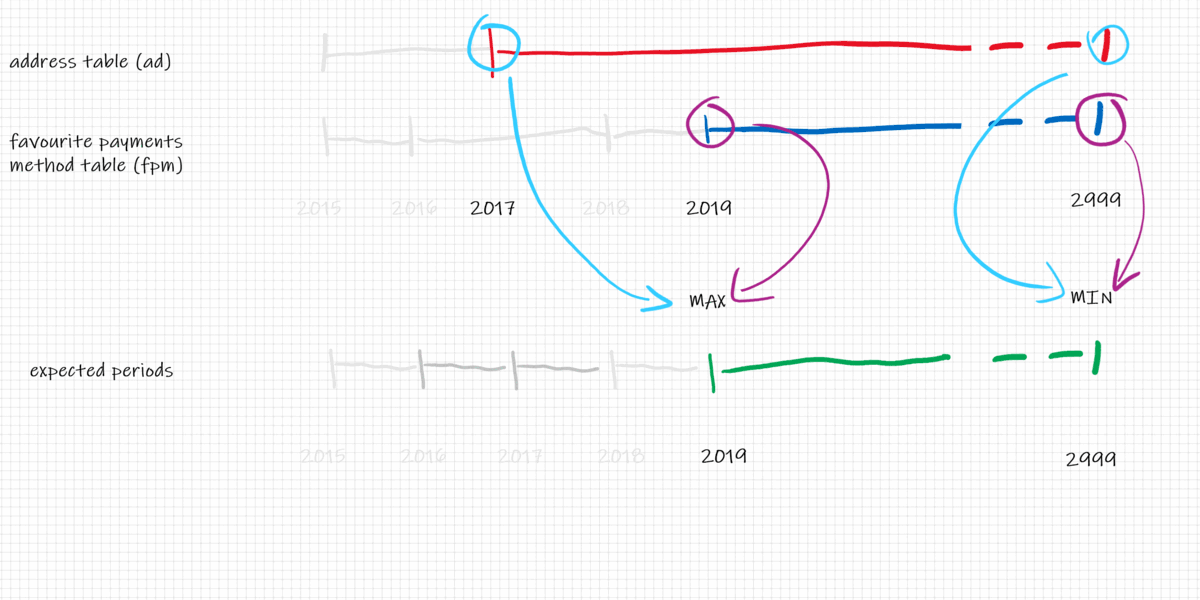
And the final result is:
SELECT fpm.client_id,
greatest(at.start_timestamp, fpm.start_timestamp) as start_timestamp,
least(at.end_timestamp, fpm.end_timestamp) as end_timestamp,
fpm.payment_method,
at.shipping_address
FROM address_tbl at INNER JOIN fav_payment_method fpm
ON at.client_id = fpm.client_id
WHERE at.start_timestamp <= fpm.end_timestamp and
at.end_timestamp >= fpm.start_timestamp
Code language: JavaScript (javascript)| client_id | start_timestamp | end_timestamp | payment_method | shipping_address |
|---|---|---|---|---|
| client_1 | 2015-01-01 00:00:00 | 2016-01-01 00:00:00 | at_delivery_time | 383 Trusel DriveNorth Andover, MA 01845 |
| client_1 | 2016-01-01 00:00:00 | 2017-05-11 10:00:00 | paypal | 383 Trusel DriveNorth Andover, MA 01845 |
| client_1 | 2017-05-11 10:00:00 | 2018-01-01 10:00:00 | paypal | 91 Gates St. Valrico, FL 33594 |
| client_1 | 2018-01-01 10:00:00 | 2019-01-01 23:00:00 | credit card | 91 Gates St. Valrico, FL 33594 |
| client_1 | 2019-01-01 23:00:00 | 2999-01-01 23:59:59 | paypal | 91 Gates St. Valrico, FL 33594 |
Note that, since at the end you obtain a table with only one start_timestamp and one end_timestamp, you can iterate this approach indefinitely and obtain a snapshot
for each version of your data.
Now you won’t suffer that much when working with date intervals in data warehouses and data lakes. Have a good query!



