
In 2022, businesses and other organizations face any number of operational challenges. From choosing the right type of business contract to implementing more effective remote working protocols, there’s a lot to think about.
But perhaps the most critical issue facing us today is data: how it’s stored, protected and used. Data is the keystone of any modern organization and getting data management right is crucial to success.

In this article, we’ll explore two of the most popular data management solutions: data warehouses and data lakes. We’ll look at the advantages and disadvantages of each and consider why you might choose one or the other (or both).
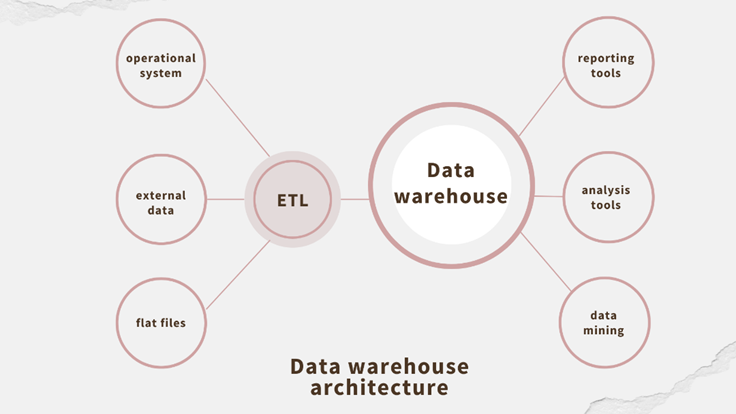
Data warehouses
For any business user, whether they’re generating reports or implementing the benefits of agile testing, data management is key. A data warehouse is one of the best-known types of data management system. It acts as a centralized repository for well-structured operational data.
When source data arrives in the warehouse, it is already in a predefined schema. And generally speaking, this is achieved using the ETL process (Extract-Transform-Load). The data can then be utilized by downstream analytical tools as required.
Advantages
A few defining characteristics of data warehouses are:
Scalability: It’s mostly a straightforward technical matter to scale up as more storage space is required.
Non-volatility: Because data warehouses are updated at scheduled intervals rather than in real time, they are not affected by momentary changes.
Well integrated: No matter the source of the data, it’s always stored in the same way.
As the schema for the data must be defined in advance, it’s crucial to know how it will be used later. This is no problem if you have well-defined use cases planned for your data. That’s why data warehouses work best for organizations which use a lot of structured data in their operations.
Downsides
For other organizations, though, it might not be the best data management solution available today. The greater the volume of data you want to add to the data warehouse at any given time, the more compute resources you will need. Obviously, this comes at a cost. If you find that much of your data is being discarded because it is not being used, the additional expense of adding yet more data that’s just going to end up on the scrapheap may seem extravagant.
As an increasing number of businesses pursue a cloud adoption strategy, this is becoming an ever more pressing issue. There’s no doubt that data warehouse architecture can be implemented on the cloud. Nevertheless, businesses making such huge changes to their data systems often use the opportunity to think bigger.
That’s why, over the past decade or so, we’ve seen more widespread adoption of the data lake system. It addresses some of the downsides of data warehouses, such as:
- Potential of data cleansing at the start of the process distorting results at the reporting stage
- Complexity of access structure for results and analysis
- Complicated and difficult change implementation
So, let’s now take a look at data lakes and how they differ from data warehouses.
Data lakes
Any kind of data – structured, semi-structured, or unstructured – can be stored in a data lake in its native format. It aggregates all data, irrespective of the format it comes in or the source it derives from. It’s still a centralized depository just as a data warehouse is, but requires no prepping of data beforehand.
This means that data lakes facilitate a schema-on-read model, whereby data is transformed as it is accessed.
Advantages
One benefit of this is that unlike with data warehouses, there is no direct connection between how much data is added and how much compute resource is required at point of ingress. In cutting down on the cost and time inherent in the ETL process, data lakes offer greater cost-effectiveness when storing large volumes of data.
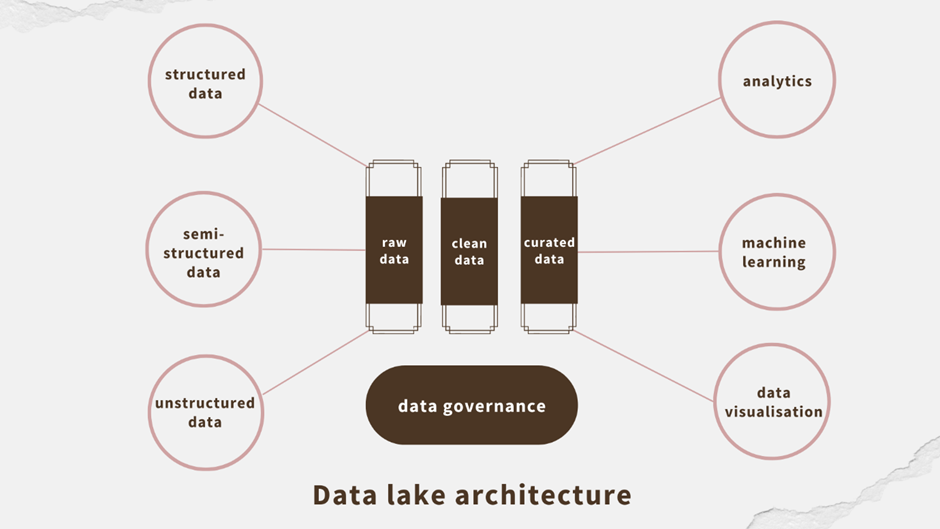
The real beauty of data lakes is that you can run an immense variety of analytics on the data stored there. Real-time analytics, full text search, SQL queries, machine learning or big data analytics – all of these can be done directly on the lake.
Because data lakes can store non-relational data such as from social media, IoT devices, mobile apps as well as relational business data, they’re uniquely flexible. You can use solutions like the Databricks ACID transactions implementation to continue to benefit from the plus points of data warehouses. But you can also use data in completely new ways.
Take, for example, IoT devices. You can use data lakes to store real-time data from internet-connected devices and massively improve operational efficiency. Or what about research and development? Specialists can run their entire hypothesis, assumption refinement and results assessment cycle directly on data stored in the lake. The full variety of ways of using a lake-based data management system is limited only by your imagination.
Downsides
There are a few drawbacks. For example, there’s no way of tracking what data has been extracted previously. This means that you can’t refer to insights gleaned from earlier findings, which isn’t ideal. Additionally, there is a risk of data integrity loss. Despite the fact several versions of the same document can be stored on the lake, there is a lack of transaction control.
And unfortunately, the free-wheeling nature of data lakes can lead to a frustrating issue. If the data in the data lake is largely of low quality, this can lead to it becoming what’s known as a “data swamp”. Sounds bad, doesn’t it? It is. Essentially, it just means that your data lake has filled up with useless data. And that can make the entire lake tiresome to use as you try to sift through all the rubbish.
So, with all this in mind, possibly there’s a question bubbling in your mind. You may be wondering whether what you need is a data warehouse or a data lake.
Data warehouse or data lake – which is the better choice for you?
This choice ultimately depends on the nature of your organization and what you plan to do with your data. It doesn’t matter whether you’re thinking of undertaking data migration to the cloud, or keeping your infrastructure on site. Either way, it’s vital to have an appropriate data management system that’s tailored to your organization’s needs. So, here are a few questions to consider before you make your decision.
How structured is your data at the moment?
If your business generally deals with well-structured data such as banking details, customer profiles, healthcare records etc., a data warehouse may be all you need. It’s crucial to consider future proofing here, of course. Are you absolutely sure your organization won’t be moving towards utilizing more unstructured data over the next few years? This can be a tricky call to make.
On the other hand, if your organization already uses a large volume of unstructured data, such as binary data, IoT telemetry, and so on, a data lake-based system is more likely to appeal. A data virtualization layer can be implemented in parallel to improve data integration.
Do you already have a structure in place?
If you’re currently using ERP, CRM, HRM, or an SQL database system, a data warehouse will be a good fit. There may not be much value to add at this point by switching to a data lake-based system. However, if this is not the case and you’re building a new system, this may not apply.
Are the data needs of your organization predictable?
If you know that the data will be used to, say, generate reports using pre-determined queries against regularly updated tables, a data warehouse will work well. But if it will be used to service a diverse and unpredictable set of analytics queries, you should consider a data lake system. That’s because, in this case, it makes much more sense to store the data in its original format.

Why not both?
In actual fact, this isn’t a binary choice. Neither a data warehouse nor a data lake on their own necessarily constitute a rounded solution. Just as you might choose to use a Resilient Distributed Dataset (RDD) or a Dataframe or Dataset in different scenarios to suit a particular use case, so it goes with the underlying data management system.
Gartner analyst Donald Feinberg points out that rushing towards implementing one single data lake solution can be a mistake. At the company’s 2021 Data and Analytics Summit, he ran a session called “How to avoid data lake failures”, which offered valuable insights into the practicalities of the process.
To avoid some of the potential problems, he suggests starting small. This means implementing a data lake for a single business unit first, which can work in conjunction with other solutions, such as an existing data warehouse. He cautions that neither a data warehouse nor a data lake represents a data strategy in itself. And that’s a vital point to remember.
Putting it all together
The reality is that many organizations will need some combination of both data warehouses and data lakes. Running analytics on Azure data lake architecture will be a great solution in some cases. Equally, for running regular operational business processes, a data warehouse will suffice.
It’s really a question of a) where you’re starting from now and b) where you need to go. Luckily, there are plenty of options you can choose between to find exactly the right fit for your organization. The future of data management has never looked more promising.
Recommended articles:
Enabling the Data Lakehouse



