Recent advances in artificial intelligence (AI) and machine learning (ML) have allowed many companies to develop algorithms and tools to automatically generate artificial (but realistic) 3D or 2D images. Such algorithms are part of a research area known as generative AI and have shown incredibly powerful features. In this article, we will understand how such algorithms are usually designed, which kind of applications and business can benefit from this tools and how future products design can benefit from generative AI.
What is Generative AI?
During the last edition of Codemotion Rome 2019, Martin Musiol (Senior Data Scientist at IBM) delivered a speech aimed at clarifying some of the key concepts of generative AI. The best way to understand what we are talking about is by starting with some examples. The first one is by nVidia, who developed a software that can generate new photorealistic faces starting from few pictures of real people:

Another interesting example has been developed by a team from the University of Berkeley. They implemented a software that can transfer video-recorded movements of a user (eg. a skilled professional dancer) to the movements of another user (eg. a totally unskilled dancer). The following video is quite impressive:
While this second example is probably more sophisticated than the previous one, the basic concepts are the same, as well as the mathematical tools and the algorithm behind this “magic”.
Generative AI VS Discriminative AI
After looking at the previous videos, it should be easier to understand which are the main goals of generative AI: using data to train algorithms that are able to create things such as images or videos. This is substantially different from discriminative AI, which usually is aimed at classifying data or to distinguish things.
This fundamental difference between these two classes of AI algorithms has direct implications in the mathematical tools used. Discriminative AI are usually based on neural networks (NNs), support vector machines (SVMs) and many other tools that allow us to classify data. Generative AI also uses neural networks, but in a substantially different way: by exploiting the so-called generative adversarial networks (GANs).
How GANs work
It is interesting to understand what GANs are and how they work. If you ask a machine learning expert such a question, he or she will probably reply that it is not that simple to explain. Luckily, during his talk at Codemotion, Martin Musiol provided a very useful and simple overview, that we will summarise. Let’s start with the following diagram:
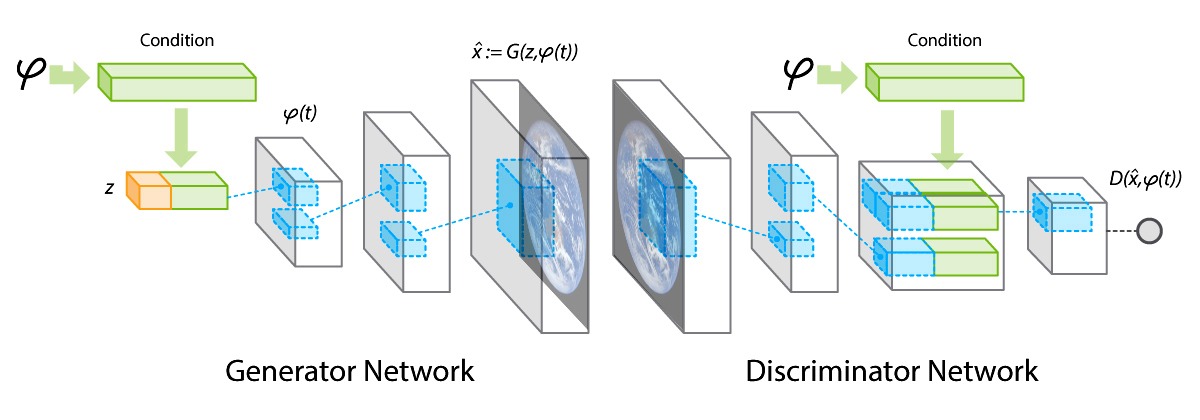
A GAN is basically a combination of two neural networks. The first one acts as a generator (e.g. of an image), which is then provided as an input of the second network. The latter acts as a discriminator, being able to distinguish between a real image and an artificial one. The output of such a discriminator network can be seen as an error value, representing how much the image produced by the generator network looks artificial. Many GANs implementations also use the error value produced by the discriminator network as an additional backpropagation connection, which allows the generator to reduce the error in the next iteration.
As an additional detail, Musiol explained that generator networks are usually implemented as deep convolutional neural networks (CNNs), while the discriminator network acts as a deconvolutional NN.
While this is just a very basic overview of GANs, it represents a great starting point for any developer who would like to start working in this field, probably one of the most promising in the context of machine learning and AI.
What’s around the corner?
Now that we have some (basic) knowledge about GANs, it is useful to understand why such tools are important nowadays. Reporting some of the examples mentioned by Musiol is useful in this direction.
In fact, it is quite evident how generative AI may impact our traditional way to produce new content. To better understand this, have a look at the following video of an interactive image generator developed by nVidia:
There will be no need to struggle in finding the right background, with objects, mountains and stuff like that in the right positions, since we will just sketch them in the place they need to be. Moreover, any kind of copyright infringement will be solved by the possibility of creating new images instead of reusing them.
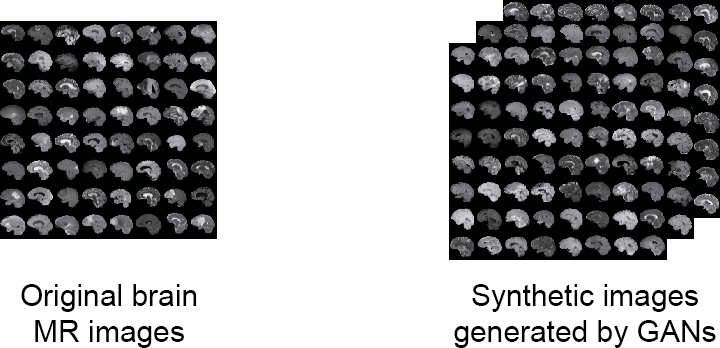
Other applications also involve privacy concerns and might affect the area of medical imaging and health-related applications. This is the case of some new inspiring applications of data augmentation, where GANs are used to provide artificial images starting from a x-ray image. This can be done to compute an estimation of the same image from different angles (avoiding additional exposure to rays), or to visualize possible expansion of a tumor.
Furthermore, these artificial images may also be used for didactic purposes, instead of using real images – thus removing any possible privacy concern for patients.
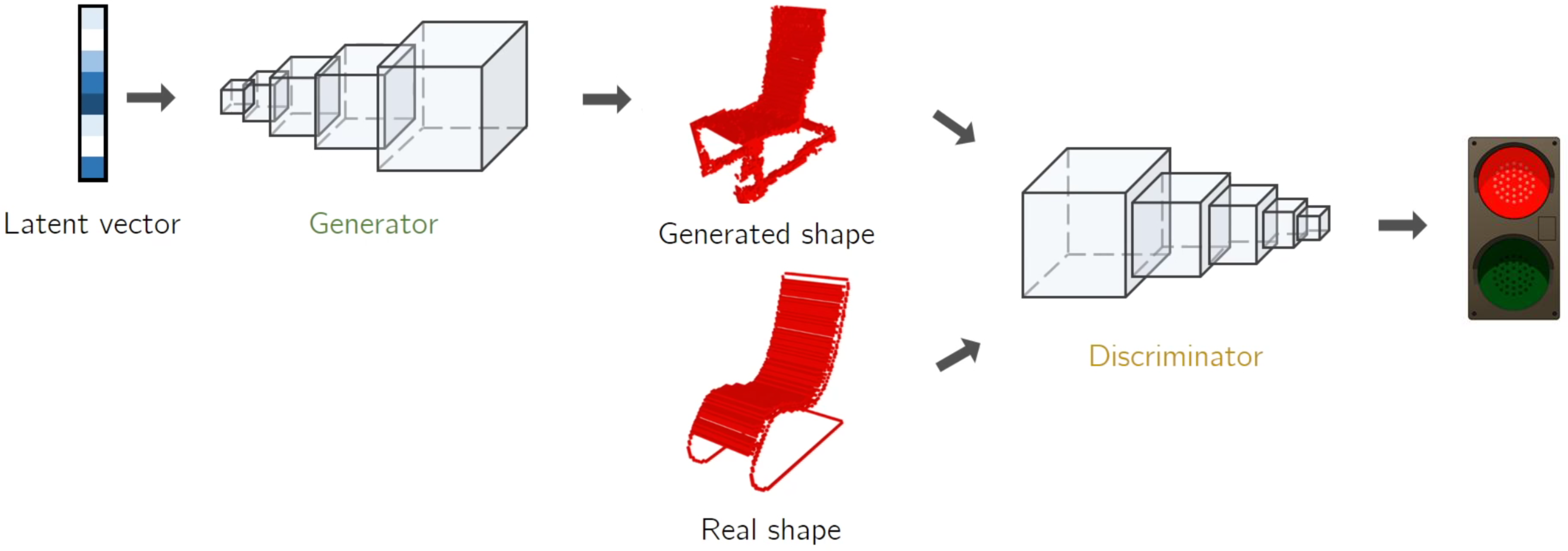
Last but not least, an additional application of generative AI is in product design. Musiol mentioned a specific class of GANs very appropriate in this context: the volumetric convolutional networks. They allow us to generate 3D objects and eventually to interpolate between the 3D representations of two different products, although the current implementations are still at a very early stage. However, with the current state-of-the-art technologies, designers may decide to use the artificially-produced 3D models as a starting point to refine and improve in order to design and build new prototypes or products.