Introduction to Cloud-Native Microservices
Cloud-native microservices refers to an app design strategy that allows developers to divide their applications into units known as microservices. The microservices are designed to share information and interact over a network, but each one can operate independently. It is worth noting that cloud-native apps use microservices architecture, which makes microservices inherently cloud-native. Other essential aspects of a cloud-native strategy include distributed architecture and consumable services.
Microservices can be compared to monolithic architecture, where the latter consists of a large and tightly-coupled application. It is also different from service-oriented architecture or SOA. While microservices are application-specific, SOA uses an enterprise-wide effort to standardize the way in which services interact with each other.

Cloud-native microservices offer lots of benefits, and one of the main advantages is increased agility. Developers can easily update and scale each microservice independently, and this makes the entire application more flexible. Another benefit of microservices is the increased resilience as the failure of a single microservice will not make the entire application fail.
This kind of architecture is booming: websites such as Adecco’s, a platform that helps connect developers with major players in the tech universe, shows hundreds of open positions for devs looking to thrive in cloud and microservices development.
Essential concepts for working with Microservices in the cloud
When working with microservices in the cloud, it is essential to separate the codebases instead of managing the code for all microservices in a single repository. Separating the microservices will simplify the development process significantly.
Similarly, it is essential to deploy each microservice independently as this will make it possible to update one microservice without affecting the entire application.
Developers also need to give each microservice its own storage resources instead of having all of them share a database. Implementing this can take some effort, but it makes it possible for developers to tailor storage resources to the needs of individual microservices.
The Twelve-Factor Methodology: what is it?
The twelve-factor methodology is meant to define patterns for applications that target PaaS offerings like Heroku and Engine Yard.
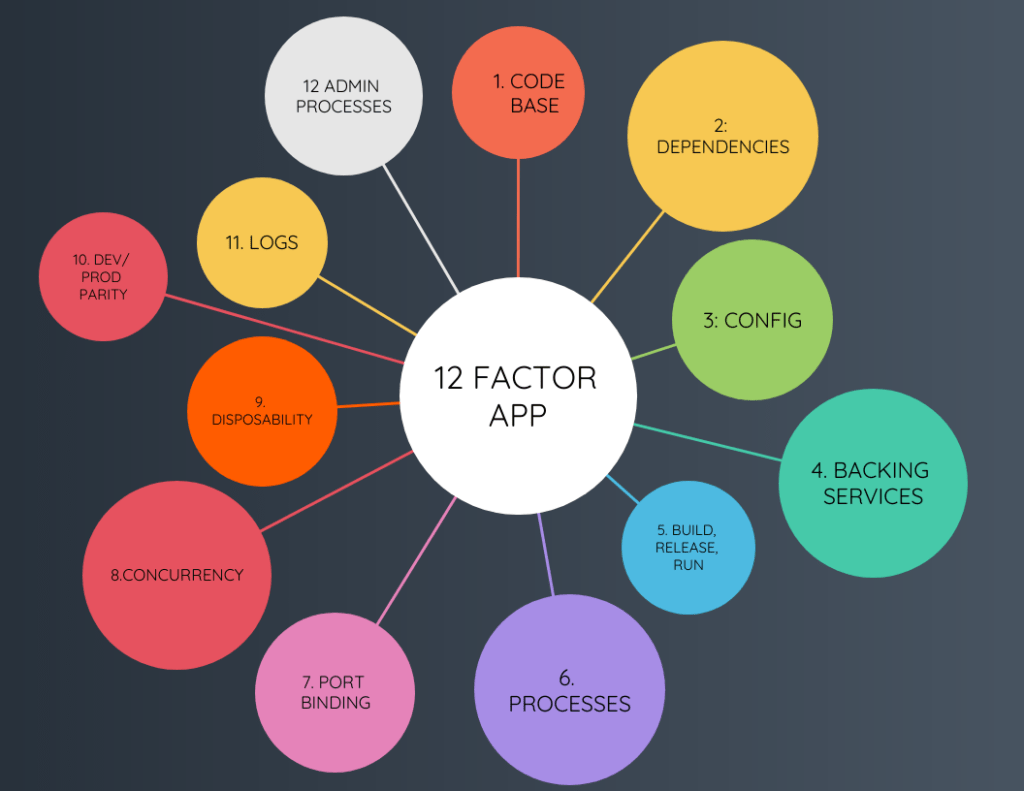
The first principle of this methodology is the codebase. The codebase of the application has to be stored in a single repository like Git or SVN. While there might be different versions and branches, there has to be a clear 1 to 1 correlation between the code, repo, and application. The main point of this principle is that developers have to maintain a single codebase for the modules associated with the application.
The second principle deals with dependencies. Developers have to ensure that the application declares all dependencies, and it shouldn’t make assumptions about the availability of dependencies.
The third principle recommends a clear separation of the configurations and codes. This can be done using environmental variables. By following this rule, the developer will be able to deploy the codebase in different environments without making any changes. You should make sure you read the configurations at runtime.
The fourth principle recommends that the developers treat backing services as attached resources. Backing services are external services that work with an application over a network connection. It is important to ensure that the interface used to connect to different services is defined in a standard way.
The fifth principle is known as the build, release, and run principle. It recommends that developers separate the stages in the lifecycle of the software. In the build stage, developers have to create the binaries by combining the code, dependencies, as well as other assets. This makes an executable bundle possible. In the release stage, the developer will combine the output from the build stage with the configurations of the environment. This prepares it for a set of target environments. Finally, in the run stage, the developer will execute the app in the select environment.
The sixth principle emphasizes the strict separation of stateful and stateless services. The application is meant to run in an execution environment as one or more processes, and these processes can be stateless and may not share anything. Each process has to download its copy to access the local file, cache, or database. By separating stateful and stateless services, the application will be able to scale as it can run simultaneously in different execution environments.
The seventh principle deals with port binding. Cloud-native applications require the developer to use a service URL to access the service exported by the application. The application will not be able to assume the port binding that exposes them to the external network. They have to bind themselves to a port that is declared externally in the configuration file. The key point here is to export services via port binding.
The eighth principle recommends that developers use the process model to scale out their applications. Each process in the twelve-factor app needs to be able to clone itself, restart, or scale when needed. This system enables the architecture to scale out when needed.
The ninth principle recommends that developers use fast startup and graceful shutdowns to maximize the robustness of the applications. Faster startups will make the release process more agile. In case of hardware failure, they will be able to shutdown gracefully.
The tenth principle requires developers to make the development, staging, and production processes similar. This consistency helps to bring parity among the dev, testing, staging, and production environments.
The eleventh principle requires developers to treat logs as continuous event streams. Logs help to keep the application working properly, but the application shouldn’t have to store the logs. This is possible if the developer treats the logs as event streams.
The twelfth principle of the twelve-factor applications is to run administration and management as one-off processes.
Choosing the right framework for cloud microservices

Springboot
Spring Boot has become the standard framework for Java microservices as it allows microservices to start small and iterate quickly. The framework is meant to help developers mitigate the challenges that come with microservices. It can help with resilience, service discovery, and load balancing, among other issues.
Micronaut
This is an open-source framework that helps developers build modular and easily-testable microservices. It provides developers with OAuth2 support and also offers annotations to secure methods. You should note that Micronaut is natively designed for cloud microservices. It can handle cloud concepts like distributed configuration, service discovery, and distributed tracing.
Quarkus
This is a Java framework that is designed for deployment on Kubernetes and Openshift platforms. The framework is built on top of popular java standards like JAX-RS and Eclipse MicroProfile, and this is one factor that distinguishes it from Spring Boot and Micronaut. Some benefits of Quarkus include its fast boot time, the little memory footprint, and the lower time-to-first request. The memory footprint is optimized for running in containers. While it is relatively new, it has been developed with a lot of extensions, including support for Hibernate and RabbitMQ.
Managing Microservices in containers
Microservices are better suited to containers as these offer fine-grain control over the allocation of resources. Containers also make it easier to use your computing capacity efficiently. Let’s look at some containerization technologies.
Docker and its benefits
Docker helps developers maintain consistency across all containerized microservices. It also makes it easier to deal with runtime issues outside the single application. Some of these issues include the use of memory and storage and the controlling of access permissions. Docker supports compatibility and maintainability, and this will minimize the time needed to set up the environment or debug it. It also supports continuous deployment and testing.
How to apply Kubernetes

Kubernetes helps developers to ensure that containerized applications run when and where they want. It also helps the applications find the resources and tools they need to work properly. The technology is production-ready and is designed with Google’s accumulated experience in container orchestration. It also takes advantage of ideas from the community.
Here is a summary of how to apply Kubernetes:
- Create a Kubernetes cluster
- Deploy an application
- Explore your application
- Expose the application publicly
- Scale up the application
- Update the application
Building an Istio service mesh
Instio provides a means for the application to connect, control, and monitor the interactions of the microservices across the containers. With it, you will be able to control all microservice communication logic, including load balancing, timeouts, fallbacks, and circuit breaking. You can deploy service mesh as a host shared proxy or as a sidecar container. Using it as a host shared proxy ends up using fewer resources and might also use connection pooling to improve the throughput. However, you should remember that a failure in one proxy will terminate the entire fleet of containers in the host.
Building an Istio service mesh as a sidecar container requires the developer to inject the proxy into each pod definition so that it runs alongside the main service. With this method, any possible proxy failure will be limited to a single pod and will not affect other pods on the host.