We often talk about cloud computing, artificial intelligence and machine learning, but just as frequently we forget all the software architecture that is behind these projects and how the data is treated, manipulated and managed. The databases are in fact a vital component for every company and their management is entrusted to very advanced systems such as Apache Spark.
Adi Polak, Cloud Developer Advocate at Microsoft, deepened this aspect in her talk at Milan Codemotion 2018. Apache Spark is a unified analytics engine for large-scale data processing; this project achieves high performance for both batch and streaming data, using a state-of-the-art DAG scheduler, a query optimizer, and a physical execution engine. Spark offers over 80 high-level operators that make it easy to build parallel apps. And you can use it interactively from the Scala, Python, R, and SQL shells.
Spark powers a stack of libraries including SQL and DataFrames, MLlib for machine learning, GraphX, and Spark Streaming. You can combine these libraries seamlessly in the same application. Spark can run using its standalone cluster mode, on EC2, on Hadoop YARN, on Mesos, or on Kubernetes.
Spark facilitates the implementation of both iterative algorithms, that visit their data set multiple times in a loop, and interactive/exploratory data analysis, i.e., the repeated database-style querying of data. The latency of such applications may be reduced by several orders of magnitude compared to a MapReduce implementation (as was common in Apache Hadoop stacks). Among the class of iterative algorithms are the training algorithms for machine learning systems, which formed the initial impetus for developing Apache Spark.
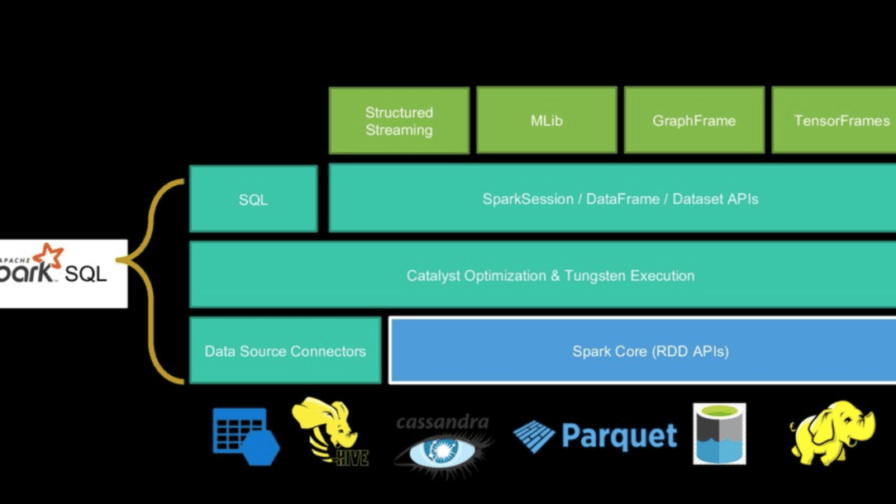
The component that supports the entire project is called Spark Core. It provides distributed task dispatching, scheduling, and basic I/O functionalities, exposed through an application programming interface (for Java, Python, Scala, and R) centered on the RDD abstraction. Another “core” component is Spark SQL that introduced a data abstraction called DataFrames. Spark SQL provides support for structured and semi-structured data and a domain-specific language (DSL) to manipulate DataFrames in Scala, Java, or Python. It also provides SQL language support, with command-line interfaces and ODBC/JDBC server. Although DataFrames lack the compile-time type-checking afforded by RDDs, as of Spark 2.0, the strongly typed DataSet is fully supported by Spark SQL as well.
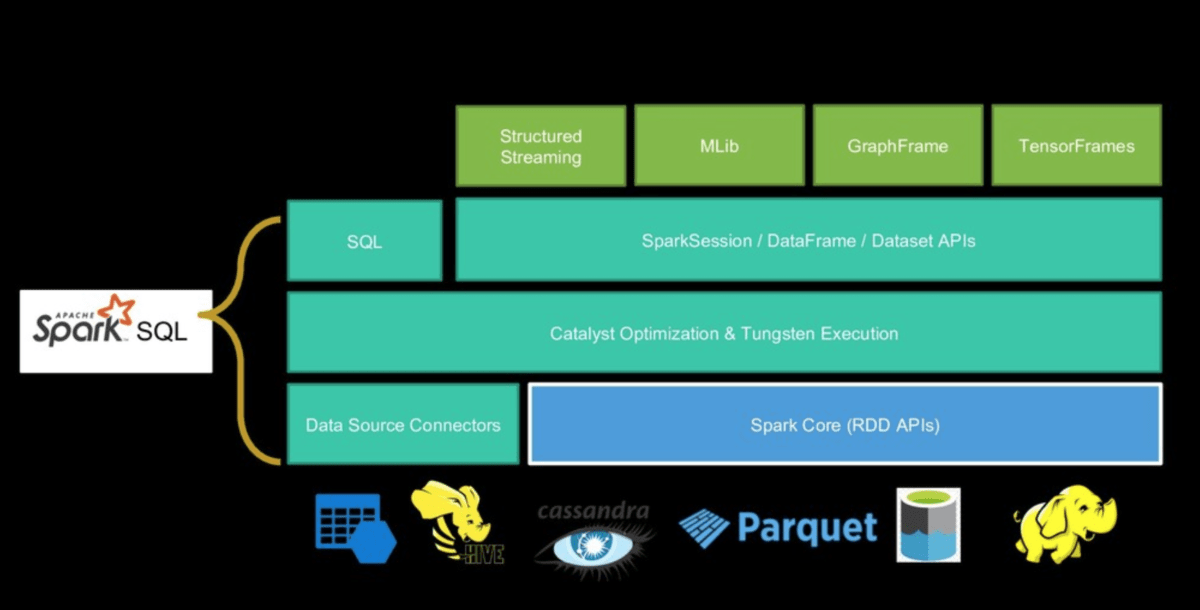
In particular, Adi Polak told us about Catalyst, an Apache Spark SQL query optimizer, and how to exploit it to avoid using UDF. The User-Defined Functions is a feature of Spark SQL to define new column-based functions that extend the vocabulary of Spark SQL’s DSL for transforming datasets.
Catalyst is based on functional programming constructs in Scala and designed with these key two purposes:
– Easily add new optimisation techniques and features to Spark SQL;
– Enable external developers to extend the optimizer (e.g. adding data source specific rules, support for new data types, etc.).

Catalyst contains a general library for representing trees and applying rules to manipulate them. On top of this framework, it has libraries specific to relational query processing (e.g. expressions, logical query plans), and several sets of rules that handle different phases of query execution: analysis, logical optimisation, physical planning, and code generation to compile parts of queries to Java bytecode. For the latter, it uses another Scala feature, quasiquotes, that makes it easy to generate code at runtime from composable expressions. Catalyst also offers several public extension points, including external data sources and user-defined types. As well, Catalyst supports both rule-based and cost-based optimization.
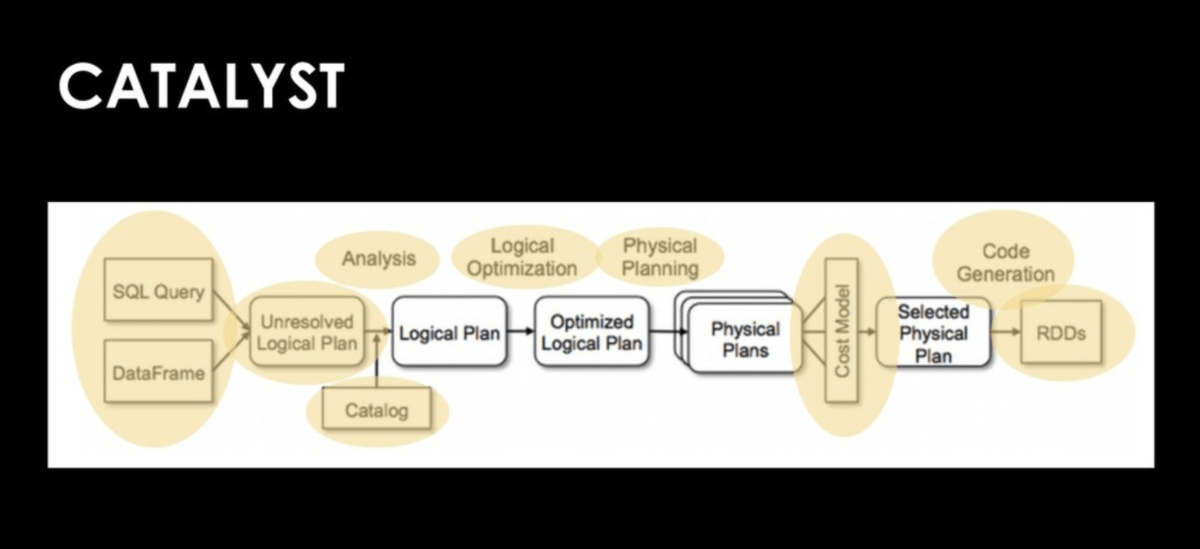
Normally to manipulate the data present a SQL database with Spark it is possible to exploit a custom UDF. However, as Adi Polak reminds us, use the higher-level standard column-based functions with dataset operators whenever possible before reverting to using your own custom UDF functions since UDFs are a blackbox for Spark and so it does not even try to optimise them.
In fact, the abuse of custom UDF can lead to the loss of constant folding and of predicate pushdown.
Constant folding is the process of recognising and evaluating constant expressions at compile time rather than computing them at runtime. While the predicate pushdown is a form of optimisation, it can drastically reduce query/processing time by filtering out data earlier rather than later. Depending on the processing framework, predicate pushdown can optimise your query by doing things like filtering data before it is transferred over the network, filtering data before loading into memory, or skipping reading entire files or chunks of files.
So as to not give up on these two features, we can then exploit Catalyst and implement a QueryExecution & explain. QueryExecution represents the execution pipeline of a structured query (as a dataset) with execution stages (phases). QueryExecution is the result of executing a LogicalPlan in a SparkSession (and so you could create a dataset from a logical operator or use the QueryExecution after executing a logical operator).
By exploiting this function it is possible to obtain performances with SQL databases that are much higher than UDF. So Adi Polak recommends using UDF only as a last resort or in any case using UDF or UDAF only to perform a single operation and never more than one at a time.
Avoiding UDFs might not generate instant improvements, but at least it will prevent future performance issues, should the code change. Also, by using built-in Spark SQL functions we cut down our testing effort, as everything is performed on Spark’s side. These functions are designed by JVM experts so UDFs are not likely to achieve better performance.
For example, the following code can be replaced with notNull function:

Another piece of advice from Adi Polak is look under the hood and analyse Spark’s execution plan with .explain(true). From the Dataset object or Dataframe object you can call the explain method like this:
//always check yourself using
dataframe.explain(true)
The output of this function is the Spark’s execution plan and this is a good way to notice wrong executions.
In order to reduce the number of stages and shuffling, best practice is first to understand the stages and then search for a way to reduct the complexity. Adi Polak continues showing us also an example of a calling method of a query with UDF:
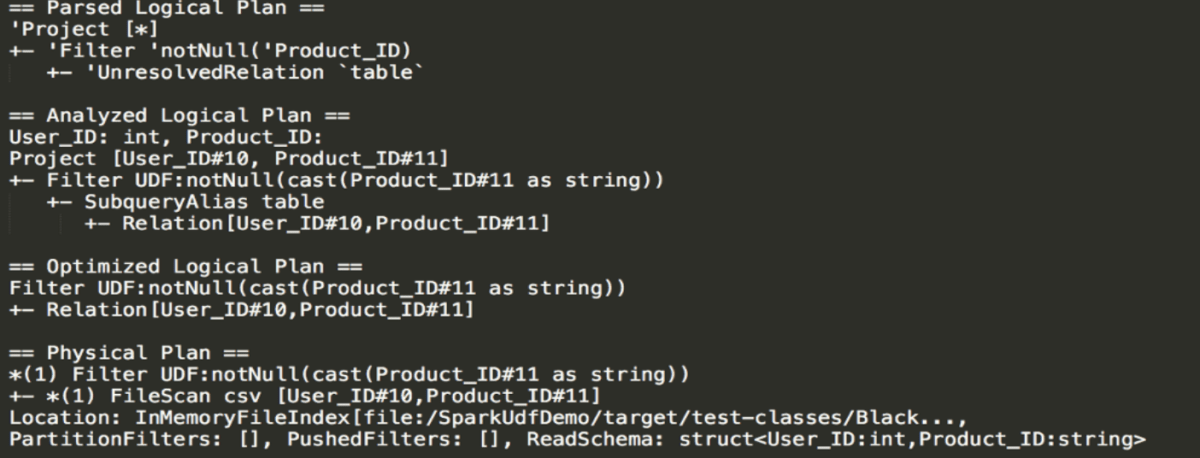
From the filtering stage, you can see that casting takes place and it happens each time an entry goes through the UDF. In our case it cast it to string.
In the physical plan we see what will actually happen in our executors, we see the partition filters, pushdown filters, the schema, the project method.
And now without UDF:
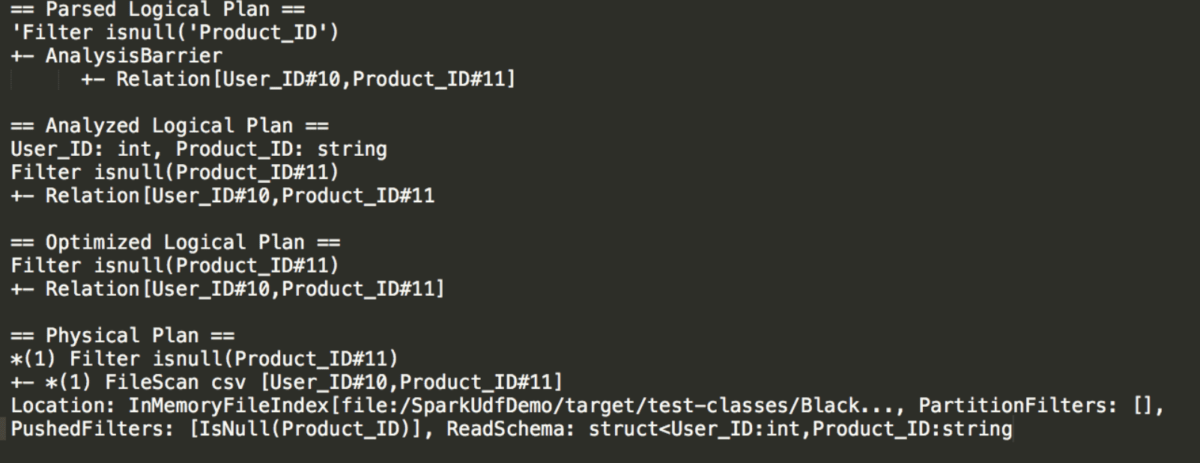
As mentioned previously, without UDF we might benefit from the pushdown filter which will happen at the storage level, which means that it won’t load all the data into Spark memory because the Spark process reads the data after the storage already filtered what’s needed to be filtered.



