
How we got here: the era of artificial intelligence
The history of humankind is marked by turning points, when a new discovery or invention changes the way things are done within an entire society and, eventually, across the entire planet. The development of agriculture was such a turning point: thousands of years ago, in several parts of the world, more or less independently, people started to cultivate cereals and rice.
That was a huge turning point: the world has never been the same since agriculture started the transition from Paleolithic to Neolithic. Populations grew due to easier availability of food, social roles became more differentiated, cities and kingdoms were born, and so on. However, not all the results were positive – as populations grew and denser living became common, epidemics had space to breed.

Chain-of-Thought Prompting: the trick to help AI think better
Another turning point was the scientific revolution of the eighteenth century: again, this started in different places, and at different moments in time, but the outcome was an exponential growth in technology, meaning that resource exploitation, economies, societies, etc. would never return to their previous states. The world as we see it today was shaped by the technological advances ignited by this revolution, by Galilei, Descartes, Newton, et al.
Science is everywhere, even if most people are not fully aware of it. However, things we are unaware of relying on are revealed as essential when they cease to be available. Try to imagine your life without electricity… Practically none of your usual activities would be possible, or at least, not as you are accustomed to doing them. Electricity, or rather, the use of electricity, is a consequence of the scientific theories of the nineteenth century and of the technological advances of the twentieth century. Those achievements, largely ignored by laypeople, haved shaped, and continue to shape, our world.
Usually such “revolutions” have no due date, nor are they located precisely: they are instead historical processes which, in the long run, may be viewed as turning points, but actually span an extended time period, which may stretch to several decades. For this reason, those who live these revolutions are usually not aware of them, at least not immediately.
It seems we are living such a revolution. Indeed, the world has changed profoundly in the last two decades alone; there are several ways in which our planet has changed in the last 20 years or so, but many, perhaps even most of these may be attributed in some way to the spread of IT technologies.
First, personal computers became available: computers were no longer industrial appliances, but became household devices, and their use became more and more common, and more widely spread, at least in the wealthiest parts of the world. Next came the Internet; computers were no longer simply personal devices, but connected devices – now, most people use them primarily to access the resources of the Internet.
The more computers, the more connections, and the more connections, the more data. The flood of data increased when other devices came into play, such as tablets and smartphones, which are really computers with a different input interface. We use these devices constantly in most areas of our lives: for work, for leisure, for education, for socializing, etc. When we use them, we produce data which are then constantly collected in the huge datacenters of the great service providers.
Again, we notice a typical feature of a turning point in human history: things will never be the same as before. The availability of storage, computational power and connections changed our lives, our habits, our minds. To describe the present-day flood of data and the processes which try to manage it, the term “big data” was coined several years ago.
Now, let us reflect for a moment on this inaccurate and coarse history of humankind; each turning point produces new discoveries (agriculture, science & technology, ITC), new kinds of consumer goods (food for all, industrial processes, information exchange), new social consequences (cities and big kingdoms, industrial economy and big empires, information economy and big companies).
In each case we have an underlying commodity which has to circulate and be exchanged to let the turning point emerge as a global change: in the case of agricultural revolution these commodities were raw materials, in the scientific revolution energy in its different forms was the commodity, in the current revolution the commodities in question are information processes.
Information is the analogue of wheat and steel, and information processes are the analogue of human (mostly slave labour) and animal strength and electricity: the former the driving force in agricultural societies, the latter the driving force in industrial societies. In our society, the driving force is not information in and of itself, but the most effective way to exploit information and data potential: this driving force is artificial intelligence.
Artificial intelligence: from birth to machine learning
Computer scientists have been fascinated by artificial intelligence since the very beginning of computer science. To explain the basic concepts of artificial intelligence it is worth looking at the work of one of its founders, who is also (not incidentally) one of the founders of computer science – Alan Turing.

Turing was a pure mathematician, and tried to answer a very simple question: what is a computation? He found the answer by designing an abstract machine, which now bears his name, that can perform any kind of computation – a sort of “mechanical mind” which is fundamentally nothing less than the very essence of software. Having reduced the concept of a computation to an abstract machine, Turing, who shared the philosophical belief that the human mind is simply a very complicated machine, imagined that machines could be used to express reasoning, too.
As early as 1950, Turing published a paper, Computing Machinery and Intelligence, linking intelligence and computation and putting forth the following question: is it possible for a machine to imitate a human being, as far as deductive and communicative skills are concerned? The so-called Turing test is proposed in that paper: a machine could pass the test if, communicating with a human inquirer via a remote connection the inquirer could not distinguish the machine from a human.
This paper is truly the cornerstone of AI (Artificial Intelligence), because it contains not only an operational definition of intelligence for a machine (being able to imitate humans), but also suggests how to design a machine to imitate human reasoning, in a section titled “Learning Machines”. Turing’s idea is to build a machine which simulates not the mind of a human adult, but the mind of a child, which he conceives as “rather little mechanism, and lot of blanks”. This machine should learn from scratch and by example, not by hard-coded general rules, or by means of some built-in general learning model.
Therefore, Turing was suggesting machine learning models. He also suggested a specific model – “punishment and reward” – which was later designed and implemented; we know it as “reinforcement learning”. Finally, in a prophetic final paragraph, he suggested some fields of application for these learning machines: chess and the English language. Both of these subjects (and more) have subsequently been achieved, the latter is now called NLP or Natural Language Processing.
Today, AI is a broad collection of methods, theories and practices which essentially consist of the study and application of classes of models for imitating human mental processes, or simulating them. These applications provide new ways to duplicate human performances, or even surpass them in most cases.
For example think of the famous AlphaGo program, which was programmed to play the Chinese game of ‘Go’ (much more difficult to play than chess): the program displays a variety of techniques, such as tree search techniques, Monte Carlo methods, deep learning, reinforcement learning, and so on. Essentially, it is a sort of compendium of AI.
Before this program can be used to play Go, an apprentice period is required to learn how to play Go effectively and efficiently, precisely as Turing indicated. To achieve this goal, the program tries to imitate human game players, relying on a database of some 30 million moves from actual games, and, once able to perform decently, continues to learn via the reinforcement learning approach of punishment and reward imagined by Turing, playing matches against itself. The result is an AI which systematically outperforms the best human players.
Today, artificial intelligence displays a manifold of techniques from different fields – from classical computer science techniques (such as tree search) to logical techniques, and from probabilistic techniques to mathematical optimization models, and so on. Each technique applies to the appropriate problem, but some quite general models have emerged and are used in several different fields: these models generally fit under the umbrella of machine learning (ML for short).
The ultimate weapon: deep learning
From a purely theoretical perspective, the main class of algorithms used in machine learning have been known for a very long time; we are talking about neural networks.
The name suggests some analogy with the human brain, and indeed the basic structure of a node in a neural network is modelled on a simple threshold activation neuron. This model was described in 1943 by McCulloch and Pitts, in a paper which is another cornerstone of AI. However, the idea they proposed of connecting several neurons still lacked a true learning process. That eventuated in the 1950s with Rosenblatt and, in a more general way which could address non linear problems, with the ‘backpropagation algorithm’ of the 1980s. Neural networks were able to learn from training sets of known data how to develop an inner, non-linear model for those data, eventually learning how to predict new data related to the same phenomenon.
A neural network consists of a series of layers which contain neurons, with connections from neurons in one layer to neurons in the adjacent layer. The external layers provide input and output, while the information flow runs from the input layer inside the net to emerge in the output layer. Both input, output and inner signal are numerical.
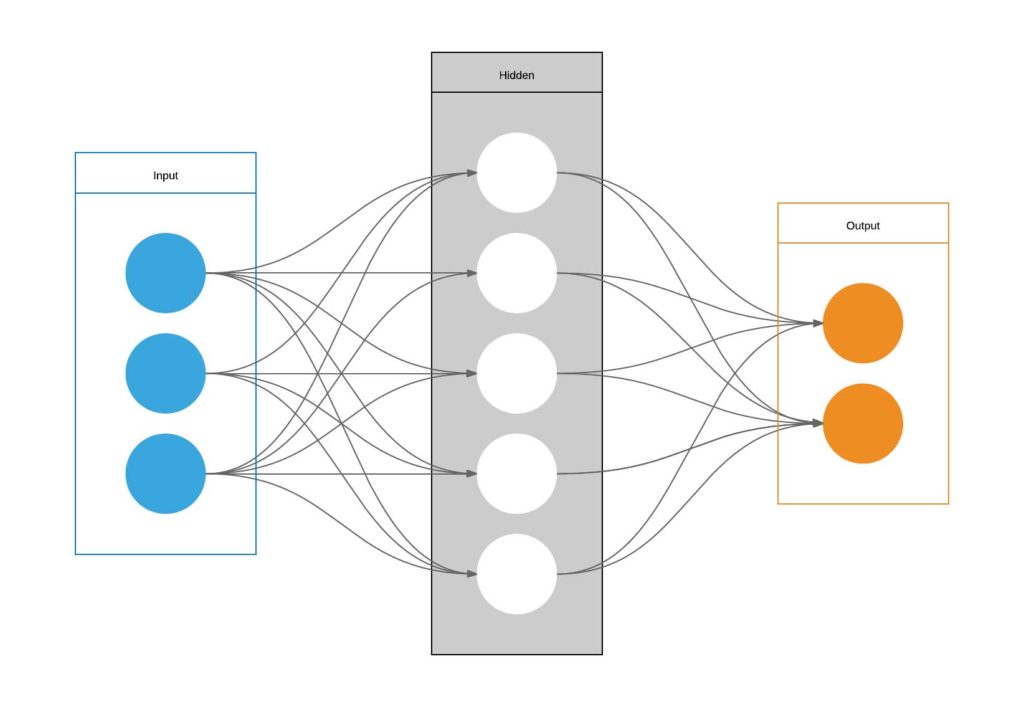
The learning algorithms feed the neurons with the results of the training session, changing the inner state of a neuron (usually a list of numbers) in order to fit the same data better when it is again proposed to the net.
A neural network thus contains a lot of data which may be changed singly at each learning session, but also other parameters, used to filter the ‘signal’ output by a neuron before the neurons in the next layer are fed with it, for example. The output of input and inner neurons in a net become the input for neurons in successive layers.
Until the first few years of the new century, neural networks were used with good results in many application fields, especially to classify things, i.e., to attach tags to texts, to recognize images, and so on. However, the performance of these networks was not better than that of human beings.
A turning point in the history of neural network came in 2006: Geoffrey Hinton, one of the three researchers awarded with the Turing Prize in 2018, devised a new way to train neural nets with many inner layers. Until then, using many layers was considered ineffective, since they augmented the complexity of the net with no real gain in performance; indeed, layers made the net more biased toward the training data, and were difficult to train due to computational issues. However, Hinton’s method worked well for these ‘deep networks‘, and the terms deep learning and deep neural networks were attached to these ideas and subsequent research from many other scientists.
Deep learning is simply a kind of machine learning that deals with neural networks with a deep inner stratification of layers, with training algorithms (and other technical elements) clever enough to allow efficient training and surprising performances. Often, these performances are superhuman.
In fact, two more ingredients were needed for the deep learning revolution to start. In the first place, the availability of huge amounts of data to train those huge nets was limited. Such networks have so many neurons that to properly set their inner number to solve a problem requires a huge number of examples to be carried out successfully (remember the 30 million moves needed by AlphaGo). Of course, in the days of big data, availability of lots of data is no longer a problem.
The other ingredient is computational power: these nets are huge and their training algorithms are very expensive from a computational point of view. Nonetheless, training algorithms may be parallelized, without the use of supercomputers – GPU suffices. These are special processors already extant within personal computers, used for computer graphics to play 3D games. Because of their high performance in parallel numerical computations, these processors provide the computational power needed to train deep neural networks.
Deep learning is not only a new collection of training algorithms, but also the exploitation of current technologies coupled with the data flood we are experiencing. The field is continuously growing; indeed, deep learning is everywhere. When we use an online translator, face recognition in social networks and digital cameras, recommendation systems when shopping online – in fact, any kind of suggestion, including semantic research in text, speech recognition (for example using personal assistants, etc.) – we are using deep neural networks somewhere in the Cloud that wraps around this world of the ITC revolution. Without realizing it, deep learning is now as necessary to us as electricity is – it is the driver of the current turning point in human history, and it is important to be aware of it.



