
Serverless computing is growing in popularity. In a serverless setup, you no longer run your own virtual servers. Instead, you compose your application using services such as databases and compute. The result is a more streamlined and reactive application.
Serverless will be one of the many interesting themes covered by Codemotion Madrid 2019 talks. Among them, Vicenç García Altés will deliver a speech about operational serverless, with many practical examples on how to use such technology (check talk’s info here).
Although the basic idea behind serverless computing seems quite straightforward, it is easy to get things wrong. So, during Codemotion Amsterdam 2019 Alex Casalboni shared some of his experiences with security, configuration management and cost optimisation.
Serverless security
Security is always crucial in any application. Access control is especially important. Using the Lambda Permission Model, AWS offers fine-grained security controls for both execution and invocation.
Execution policies are used to define what resources a given function is allowed to access. For example, “Lambda function A can read from DynamoDB users table”.
Function policies are used for controlling invocations. They can allow for access across accounts. For example, “Actions on bucket X can invoke Lambda function Z”.
However, you have to be really careful not to grant unlimited access rights! As Alex put it, things like Action: “s3.*”, Action: “dynamodb:*” and Action: “sns:*” make puppies cry! Instead, you should use very fine-grained IAM (Identity and Access Management) policies using the AWS Serverless Application Model (SAM).
The next warning Alex gave us is to avoid the use of hard-coded secrets within your application. Instead, you should use one of the tools provided by AWS.
AWS Lambda Environment Variables
AWS Lambda Environment Variables are key-value pairs that work just like Unix environment variables. They are easily accessible via the standard APIs (which depend on your runtime). They can also be optionally encrypted using the AWS Key Management Service (KMS). This allows you to control which roles are allowed access to each variable. This approach is particularly useful for creating multiple environments (e.g. dev, test and production).
AWS Systems Manager Parameter Store
The AWS Systems Manager Parameter Store is a free centralised store designed to manage all your configuration data. It is ideal for things like centralised environment variables (e.g. for 3rd party services), secrets management and feature flags. It supports hierarchies (/app/function/…) and data can be in plaintext or encrypted with AWS KMS. You can send notifications of changes to the Amazon Simple Notification Service (SNS) or to a Lambda function. The store can be secured using IAM and calls can be recorded in AWS CloudTrail. Parameters can be tagged and the parameter store is available via an API and SDKs.
Alex also introduced us to one of his own projects called ssm_cache.
AWS Secrets Manager
Another alternative is to use the AWS Secrets Manager service. This makes it easy to manage, retrieve and rotate credentials. Secrets can be automatically rotated without breaking stuff. It will keep track of password versions. It implements proper security controls for credential management and it offers built-in support for Amazon RDS.
Combining AWS Secrets Manager and Parameter Store
By combining the AWS Secrets Manager and Parameter Store you get several benefits. You can reference the secrets in the Secrets Manager using the Parameter Store APIs and you can delegate rotation and refresh of secrets to the client. Doing this is as simple as using a prefix: /aws/reference/secretsmanager.
You can even use ssm_cache to achieve the same thing:
The final thing Alex showed us with ssm_cache is how to group parameters and secrets.
If you want to play with this you can use the AWS Serverless Security training.
Serverless cost optimisation techniques
The next thing Alex showed us was how to optimise the costs of your serverless setup. Your serverless function has a complex anatomy. The function itself is wrapped in a language runtime. These are then packaged in a container which sits on top of a compute substrate. When you make a new request to the function there are several stages that have to happen as shown below. You only have control over some of these, and so this is where you should focus your optimisation efforts.
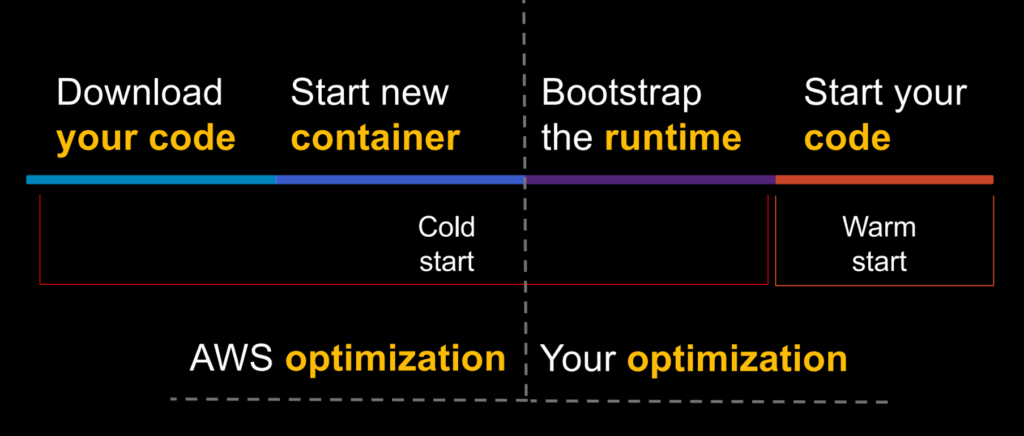
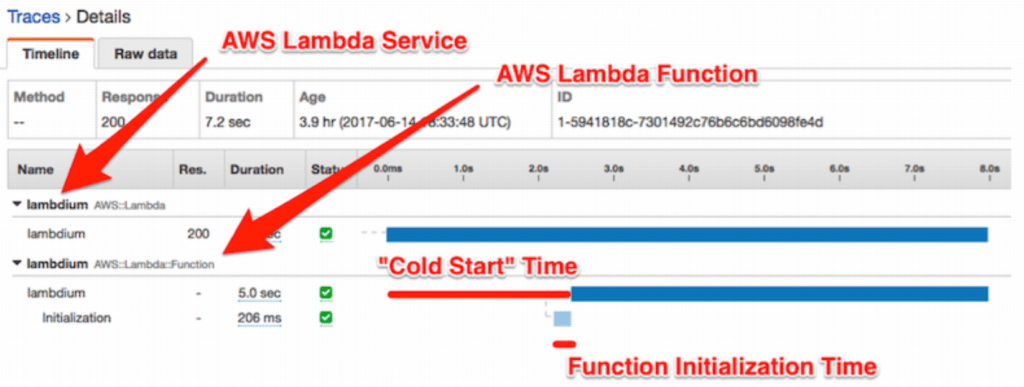
You can also see something this in AWS X-Ray:
Writing efficient functions
There are a few ways you can improve the efficiency of your code.
- Avoid large monolithic functions.
- Make sure you keep control of the dependencies in the function’s deployment environment. More dependencies = larger package.
- Make sure you use an optimisation tool suitable for your language. E.g. for Node.js you can try Browserfy, Minify or Webpack.
You also need to remember that Lambda processes a single event for each container. You don’t need to implement non-blocking execution on the frontend. But since containers are reused, there are two things Alex highlighted:
- Lazily load variables in the global state
- Don’t load something if you don’t actually need it
Here’s an example of lazy initialisation using Python and boto3.
And here are examples of how to optimise dependencies using the Node.js SDK and X-Ray.
While a few milliseconds might not seem a big saving, remember that you are billed in units of 100ms. If your function takes 104ms to run and you can save 5ms, you are halving the cost!
Concise function logic
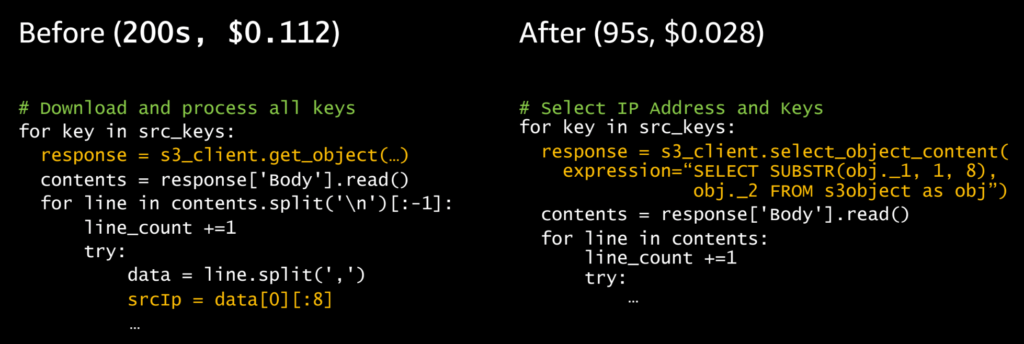
You can make your code more efficient by separating the Lambda handler from the core logic. Try to only use functions to transform the data, not to transport it. And only read in the data you need by using Query filters in Amazon Aurora or using Amazon S3 select.
Even small changes can save a lot of money, as the following example shows.
It is also really important to carefully match the resources you allocate. While more resources may cost more, the saving in time can, confusingly, lead to a lower overall bill!
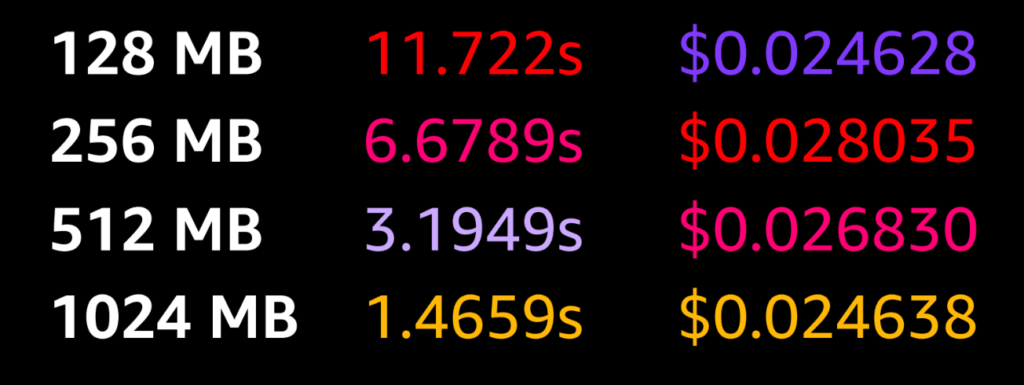
Improved orchestration
Alex’s next piece of advice for cost optimisation is to avoid using orchestration within your code. If you use the time.sleep() function to wait for an event to complete, you are going to be charged for this time, even though nothing is happening. Better to use AWS Step Functions (which are effectively state machines). Here, you are only charged for each state transition.
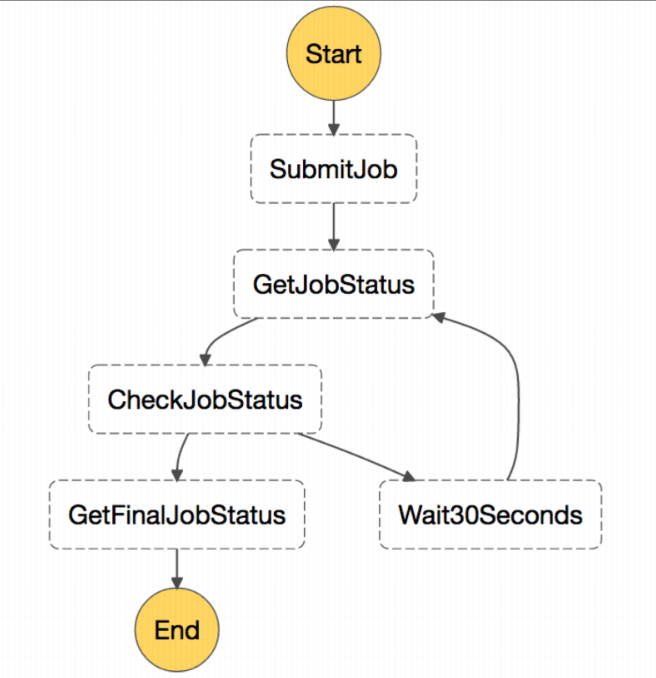
Other optimisations
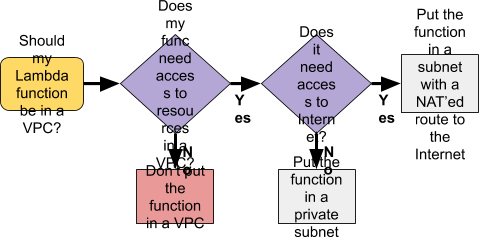
There are numerous other optimisations you can make. For instance, if you have a single client, why use an API? If your code is all internal (e.g. not customer facing) use one of the AWS regional endpoints. Make sure you discard events that aren’t needed. Make sure you really understand about retry policies (especially as they relate to asynchronous operations). Each time a function is retried, you are billed for a new invocation. Finally, you should consider whether you need to use a VPC or not. Alex shared a very simple flowchart to help us determine this:
Conclusions
Security is essential in any system. By using AWS tools, you can make it much easier to secure your function. If you are using Python, then Alex’s ssm_cache project offers a really easy way to use both the Secrets Manager and the Parameter Store. Then by optimising your serverless functions, you can save a significant amount of money. At times, it’s not obvious how to achieve this. However, the advice Alex gave should be a great help.
If you want to learn more about serverless computing, in Codemotion Madrid 2019 you will have the opportunity to learn how far we are from using serverless in real products. Check the Vicenç García Altés’s talk and the whole Codemotion Madrid 2019 agenda. And do not forget to buy your ticked and attend the conference!



