
Convenzioni, compiler intelligence e server boundaries non sono dettagli ergonomici: sono la nuova interfaccia tra le codebase e gli agenti AI che ci lavorano dentro.
Lo so, lo so… La domanda, così formulata, è davvero provocatoria. Implica che esista una soglia oltre la quale gli agenti AI rendono superflua le astrazioni che chiamiamo “framework”. Inoltre, la domanda implica che la storia recente di React, Next.js, Angular, Svelte, Astro, Solid e compagnia bella sia la storia di strumenti pensati per umani che ora dovrebbero farsi da parte.
È un framing comodo per produrre titoli, e quasi inutile per capire cosa stia davvero succedendo nell’ecosistema JavaScript.

Fatta questa doverosa premessa, togliamoci il cappellino di stagnola e cominciamo ad osservare che quello che sta accadendo è più interessante che spettacolare. I framework non stanno arretrando. Stanno cambiando interlocutore. Per quindici anni hanno ottimizzato un’unica metrica, la Developer Experience, perché il loro utilizzatore principale era un essere umano davanti a un IDE.
Da circa due anni questa premessa ha smesso di essere vera. Una quota crescente del codice che entra in produzione viene generata, modificata o orchestrata da un agente AI: Cursor, Claude Code, GitHub Copilot, Devin, Windsurf, quello che preferite. L’utilizzatore del framework non è più solo un umano. È un sistema software con i suoi limiti, i suoi bias, e le sue “preferenze” (se così vogliamo chiamarle).

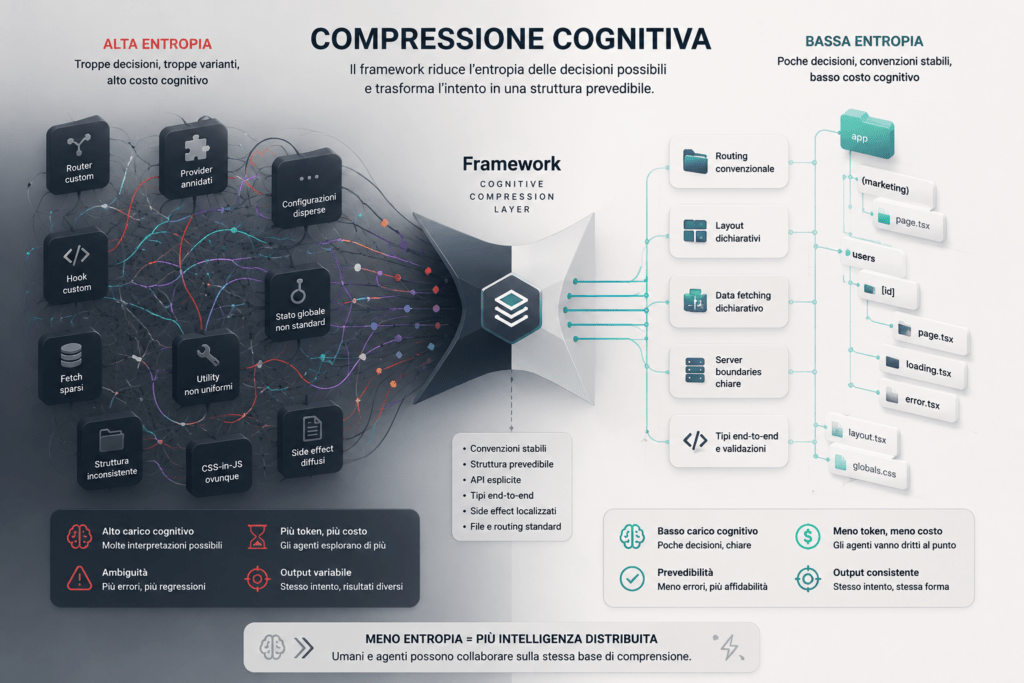
I framework che sopravvivranno ai prossimi cinque anni sono quelli che stanno ridisegnando le proprie convenzioni anche per questo nuovo utilizzatore. Non devono sostituire l’umano ma devono far lavorare l’agente AI e l’umano insieme. Il punto centrale di questo articolo è che il framework, nell’era agentica, smette di essere una “comodità per chi scrive” e diventa qualcosa di strutturalmente diverso: uno strato di compressione cognitiva tra l’intento (umano o agente) e la macchina.
Da DX a ADX
Per anni la metrica dominante è stata la Developer Experience (DX per gli amici). Tempo di setup, ergonomia delle API, qualità degli errori, hot reload, autocomplete. Era una metrica calibrata su un cervello umano che leggeva codice un pezzo alla volta.
Nell’ultimo anno (o giù di lì) sta emergendo una metrica parallela che, in mancanza di nomi migliori, possiamo chiamare Agent Developer Experience (abbreviamola in ADX). Cos’è questa ADX?
Riguarda quanto è facile, per un agente AI:
- navigare una codebase
- capire cosa modificare
- fare la modifica giusta al primo tentativo
- non rompere quello che non vede o che ancora non “conosce”
L’ADX non è il contrario di DX: ne è una derivata, se vogliamo usare termini matematici… Le caratteristiche che rendono un codice leggibile da un umano competente (convenzioni stabili, dipendenze esplicite, tipi end-to-end, side effect localizzati) sono le stesse che lo rendono manipolabile da un LLM. Ma con una differenza di scala: quando il codice viene generato in massa, anche piccole ambiguità si amplificano in errori enormi e poco controllabili.
Sicuramente l’avete visto succedere: partite da una richiesta semplice tipo “creami un hook React” e dopo 20 minuti siete persi in test, linter che non passano e “spaghetti code” indecifrabile
I framework moderni stanno reagendo a questa pressione in modo abbastanza coerente: file-based routing, server components, typed routing… Sono tutte risposte allo stesso problema: ridurre la variabilità dell’output. Far sì che, per un dato intento, esista un piccolo numero di soluzioni plausibili, possibilmente una sola.
La tesi della compressione cognitiva
Per capire perché questa convergenza non sia casuale, conviene fare un passo indietro. Un sistema software complesso è caratterizzato dall’entropia delle decisioni che chi ci lavora deve prendere:
- Dove va quel componente?
- Come si fa fetch dei dati?
- Dove inizia il server?
- Come si dichiara una rotta?
Ogni domanda ammette molte risposte tecnicamente equivalenti ma cognitivamente onerose.
Un framework opinionato risponde a queste domande prima ancora che vengano poste. Riduce la varianza. Comprime lo spazio delle decisioni. Per un team umano questo è ergonomia. Per un agente AI è qualcosa di più cruciale: è la condizione perché il suo output sia verificabile.
Ripetiamolo come un mantra: un LLM non “comprende” il codice nel senso forte del termine. Un LLM ragiona su pattern, su distribuzioni statistiche di token, su strutture sintattiche apprese durante il training. Un LLM funziona meglio dove le strutture sono più rappresentate e più stabili.
Un App Router di Next.js, con la sua gerarchia app/[segment]/page.tsx, è facile da rappresentare per un modello: a un percorso URL corrisponde un file, a un layout corrisponde un altro file, a un loading state un altro ancora. Una SPA React con react-router configurato a mano in un App.tsx, con lazy import sparsi e provider annidati, richiede al modello di ricostruire una mappa che il framework ha rifiutato di imporre. Il primo caso è leggibile. Il secondo va interpretato.
La differenza, in produzione, non è teorica. Si misura nel numero di file che l’agente tocca per implementare una feature, nella probabilità di modificare il file giusto al primo tentativo, nella quantità di codice che il senior deve riscrivere durante il review.
Anatomia di un framework “AI-native”
Ora che abbiamo chiarito cosa sia l’ADX e perché sia utile, possiamo analizzare le cinque caratteristiche stanno emergendo come pattern comuni nei framework adatti all’era agentica.
File-based conventions comprensibili senza documentazione
Next.js App Router, Nuxt, SvelteKit, SolidStart, Astro, Qwik City, TanStack Start: tutti convergono su filesystem dove la posizione del file è essa stessa informazione. Questo non è un dettaglio estetico. È un’API leggibile da chi non ha letto il manuale (umano o macchina che sia). Una codebase con app/dashboard/[id]/page.tsx e app/dashboard/[id]/layout.tsx racconta la propria architettura senza bisogno di un file README.
Reattività esplicita, non magica
I compiler-first framework (come Svelte) hanno un vantaggio strutturale: il codice scritto ha una traduzione formale, deterministica, in qualcosa che l’analisi statica può manipolare. Le runes di Svelte 5 e i signals di Solid e Angular sono modelli di reattività dichiarativi: non dipendono dall’ordine di chiamata di una funzione (come gli hook React) o da regole di linting per essere corretti. Per un LLM che deve modificare la reattività di un componente, la differenza è enorme. Una closure stale in un useEffect è un bug classico che gli agenti continuano a produrre. Una rune dichiarata con $state è quasi impossibile da sbagliare allo stesso modo. È esattamente questo tipo di prevedibilità che il lavoro sulla memoization sta cercando di recuperare a livello di compilatore.
it automatically optimizes your React application by handling memoization for you, eliminating the need for manual
useMemo,useCallback, andReact.memo
Tipi end-to-end
TanStack Router ha trasformato il routing tipizzato da curiosità a feature di prima classe: i parametri di percorso, i search params, i loader sono tipi che fluiscono attraverso l’app. Next.js sta arrivando allo stesso punto in modo diverso, con typed routes e Server Actions tipizzate attraverso il boundary.
Per un agente, la tipizzazione end-to-end è una rete di sicurezza che evita un’intera classe di output plausibili-ma-sbagliati.
Server boundaries esplicite
I React Server Components, le Server Actions di Next.js e React Router 7, i loader/action di TanStack Start, le +page.server.ts di SvelteKit sono tutti tentativi di rendere lessicalmente visibile dove finisce il client e dove inizia il server.
Senza questa “dichiarazione”, ogni componente è potenzialmente tutto: un agente che genera codice deve indovinare. Con la separazione esplicita, il problema scompare.
Metadata strutturati e introspezione
Astro Content Collections con schema Zod, frontmatter tipizzato, manifesti di build, route manifest… Sono tutti modi di esporre la struttura dell’app in un formato machine-readable. Su questo si innesta MCP, il Model Context Protocol che sta diventando lo standard di fatto per esporre contesto e capability agli agenti. Un MCP server che pubblica le rotte, i layout e le server functions di un’app Next.js è la differenza tra un agente che fa grep e un agente che fa query.
Framework per framework, senza tifo
Vale la pena fare qualche esempio di quello che abbiamo appena detto. Per ognuno esploreremo lo stesso task minimale (una rotta che recupera una lista di utenti da un’API e la renderizza) perché è il modo più onesto di confrontare come i diversi framework si stanno adattando all’ADX. La domanda implicita è sempre la stessa: se a un agente chiedo “aggiungi una pagina /users che lista gli utenti”, quante decisioni deve prendere da solo, e quanto è probabile che le prenda bene?
Next.js (App Router)
Next.js è l’esempio “principe” del framework che si sta trasformando in protocollo. App Router, Server Actions, integrazione nativa con l’AI SDK di Vercel, supporto MCP in espansione, generatori come v0 che producono direttamente codice Next.js: è un sistema dove le scelte di runtime, build, edge e data fetching sono pre-confezionate per un certo modello mentale.
Il rovescio della medaglia è la concentrazione: scegliere Next.js significa scegliere, in larga misura, l’opinione di Vercel sul futuro del web. Per molti team è un trade-off ragionevole. Per altri è una preoccupazione legittima, e il dibattito ricorrente sull’utilizzabilità dei React Server Components fuori dal recinto Next ne è il sintomo evidente.
// app/users/page.tsx
export default async function UsersPage() {
const users = await fetch('https://api.example.com/users')
.then((r) => r.json())
return (
<ul>
{users.map((u) => <li key={u.id}>{u.name}</li>)}
</ul>
)
}Code language: JavaScript (javascript)ADX: il path del file è l’URL, il componente è server-side per default (è un async server component), il fetch non richiede useEffect, né react-query, né uno store. Un agente che riceve “aggiungi una pagina /users che lista gli utenti” sa esattamente dove creare il file, quale signature usare, e che il fetch è server-side senza scelte da fare. Lo spazio delle soluzioni plausibili è minuscolo.
Modificare la pagina per aggiungere caching, streaming o revalidation richiede di toccare lo stesso file con primitive ben note (fetch con next.revalidate, <Suspense>, revalidatePath). Alta densità di convenzione per riga di codice.
React senza framework
React “nudo e crudo” è la posizione che l’era agentica sta penalizzando di più. Non perché React sia obsoleto, ma perché la combinazione “React + Vite + react-router + tanstack-query + zustand + libreria di form + libreria di tabelle” è una collezione di scelte locali ottime che non comunicano tra loro.
Ogni progetto è quasi artigianale. Ogni agente, davanti a uno di questi progetti, deve ricostruire convenzioni che non esistono (o che sono nella test dello sviluppatore che ha creato il progetto) e lavorare con “quello che c’è”.
// src/App.tsx
import { BrowserRouter, Routes, Route } from 'react-router-dom'
import { QueryClient, QueryClientProvider, useQuery } from '@tanstack/react-query'
const qc = new QueryClient()
function UsersPage() {
const { data, isLoading } = useQuery({
queryKey: ['users'],
queryFn: () => fetch('/api/users').then((r) => r.json()),
})
if (isLoading) return <div>Loading…</div>
return <ul>{data.map((u: any) => <li key={u.id}>{u.name}</li>)}</ul>
}
export default function App() {
return (
<QueryClientProvider client={qc}>
<BrowserRouter>
<Routes>
<Route path="/users" element={<UsersPage />} />
</Routes>
</BrowserRouter>
</QueryClientProvider>
)
}Code language: JavaScript (javascript)ADX: niente di standard. L’agente deve scoprire da solo dove sono dichiarate le rotte (un componente <Routes> da qualche parte? un file routes.ts? lazy import?), quale fetcher è in uso (react-query? swr? fetch dritto? un client API custom?), dove vivono i provider, se c’è SSR. Ogni scelta è arbitraria, ogni progetto è diverso. La probabilità che l’agente generi codice “plausibile ma incoerente con il resto” è alta, e cresce con la dimensione del repository.
La vera domanda da porsi nel 2026 non è più “quale UI library”, ma “quale framework attorno a React”.
Angular
Angular sta vivendo una rinascita silenziosa che molti commentatori stanno ignorando. Standalone components, signals, control flow nativo, defer block: l’Angular del 2026 è un framework profondamente diverso da quello degli NgModule, ed è (paradossalmente) uno dei più LLM-friendly in circolazione.
// app/users/users.component.ts
import { Component, inject } from '@angular/core'
import { HttpClient } from '@angular/common/http'
import { toSignal } from '@angular/core/rxjs-interop'
@Component({
standalone: true,
template: `
<ul>
@for (u of users(); track u.id) {
<li>{{ u.name }}</li>
}
</ul>
`,
})
export class UsersComponent {
private http = inject(HttpClient)
users = toSignal(
this.http.get<{ id: number; name: string }[]>('/api/users'),
{ initialValue: [] }
)
}
// app.routes.ts
import { Routes } from '@angular/router'
export const routes: Routes = [
{
path: 'users',
loadComponent: () =>
import('./users/users.component').then((m) => m.UsersComponent),
},
]Code language: JavaScript (javascript)ADX: dipendenze iniettate esplicitamente (inject(HttpClient)), signal dichiarativo invece di osservabili magici, control flow nativo (@for con track). Per un LLM tutto è esplicito: cosa si importa, dove vive lo stato, come si itera, dove la rotta carica il componente.
Pochi misteri runtime, convenzioni rigorose, errori del compiler chiari: se l’ecosistema enterprise lo sta riscoprendo, una delle ragioni è proprio questa.
Vue / Nuxt
Vue e Nuxt occupano la nicchia “boring is beautiful”: convenzioni solide, ecosistema maturo, niente svolte epocali. Per molti team è esattamente quello che serve.
<!-- pages/users.vue -->
<script setup lang="ts">
interface User { id: number; name: string }
const { data: users } = await useFetch<User[]>('/api/users')
</script>
<template>
<ul>
<li v-for="u in users" :key="u.id">{{ u.name }}</li>
</ul>
</template>Code language: HTML, XML (xml)ADX: file in pages/ = rotta, useFetch è la convenzione standard (server al primo render, client dopo), single-file component con sezioni dichiarative chiaramente separate. Per un agente è quasi banale: il pattern è identico per qualunque pagina, l’auto-import di Nuxt riduce ulteriormente le scelte. La verbosità è bassa, l’ambiguità anche. Una codebase Nuxt è quasi sempre più leggibile di una Next.js equivalente in complessità, semplicemente perché l’ecosistema Vue ha sempre premiato la convenzione sull’innovazione.
Svelte 5 / SvelteKit
Svelte 5 ha fatto la scommessa più radicale: le runes spostano la reattività da “magica e implicita” a “esplicita e dichiarativa”.
// src/routes/users/+page.server.ts
import type { PageServerLoad } from './$types'
export const load: PageServerLoad = async ({ fetch }) => {
const users = await fetch('/api/users').then((r) => r.json())
return { users }
}Code language: JavaScript (javascript)<!-- src/routes/users/+page.svelte -->
<script lang="ts">
let { data } = $props()
</script>
<ul>
{#each data.users as user (user.id)}
<li>{user.name}</li>
{/each}
</ul>Code language: HTML, XML (xml)ADX: il +page.server.ts rende il boundary client/server lessicalmente esplicito, non è una convenzione di sintassi come 'use server', è scritto proprio nel nome del file. Non si può sbagliare.
Le runes ($props, $state, $derived) sono dichiarazioni, non chiamate sensibili all’ordine come gli hook React. Il compiler garantisce che l’output runtime sia analizzabile e ottimizzato. Per un LLM che deve modificare un componente, la differenza tra $state(0) e una variabile la cui reattività dipende da regole sintattiche è la differenza tra un’API e un mistero. È una delle ergonomie agentiche più alte sul mercato.
Solid / SolidStart
Solid e SolidStart condividono la filosofia compiler-first di Svelte con un purismo concettuale ancora più marcato. La reattività granulare di Solid è uno dei modelli mentali più puliti dell’intero ecosistema.
// src/routes/users.tsx
import { For } from 'solid-js'
import { createAsync, query } from '@solidjs/router'
const getUsers = query(async () => {
const res = await fetch('/api/users')
return res.json() as Promise<{ id: number; name: string }[]>
}, 'users')
export default function Users() {
const users = createAsync(() => getUsers())
return (
<ul>
<For each={users()}>{(u) => <li>{u.name}</li>}</For>
</ul>
)
}Code language: JavaScript (javascript)ADX: signal-based reactivity esplicita: le parentesi () rivelano l’accesso reattivo a colpo d’occhio. <For> invece di .map() per liste, perché Solid non re-rendera l’intero componente: la differenza è sintatticamente visibile. Il modello mentale è coerente al 100%: non ci sono casi speciali, non ci sono “regole degli hook”, non ci sono dipendenze da dichiarare a mano. Per un LLM, la coerenza è oro — e non è un caso che le idee di Ryan Carniato siano migrate, in forme diverse, dentro Vue, Angular e perfino il lavoro su React Forget.
Astro
Astro ha scelto un posizionamento laterale e furbo: content-first, islands, schema strutturato per i contenuti. È il framework che meglio si presta a siti dove il contenuto è il prodotto e l’interattività è puntuale.
---
// src/pages/users.astro
interface User { id: number; name: string }
const users: User[] = await fetch('https://api.example.com/users')
.then((r) => r.json())
---
<ul>
{users.map((u) => <li>{u.name}</li>)}
</ul>Code language: JavaScript (javascript)ADX: il frontmatter (---) è server-side per costruzione, sempre, senza eccezioni. Il template è statico per default. Niente da decidere su client vs server: è ovvio dalla sintassi stessa. Aggiungere interattività richiede un’island esplicita (<MyComponent client:load />), e questo è proprio il metodo che riduce la varianza per l’agente. Quando si entra nel territorio dei contenuti, le Content Collections con schema Zod diventano un contratto leggibile per l’LLM: lo schema è la documentazione, e l’agente lo usa come tale per generare contenuti coerenti.
Una codebase Astro ben strutturata è uno dei terreni più ergonomici in assoluto per un agente.
Qwik / Qwik City
Qwik è la scommessa di lungo periodo: la resumability sostituisce l’idratazione, il modello di esecuzione è formalmente più pulito, l’app è “lazy” per costruzione.
// src/routes/users/index.tsx
import { component$ } from '@builder.io/qwik'
import { routeLoader$ } from '@builder.io/qwik-city'
export const useUsers = routeLoader$(async () => {
const res = await fetch('https://api.example.com/users')
return res.json() as Promise<{ id: number; name: string }[]>
})
export default component$(() => {
const users = useUsers()
return (
<ul>
{users.value.map((u) => <li key={u.id}>{u.name}</li>)}
</ul>
)
})Code language: JavaScript (javascript)ADX: il suffisso $ non è cosmetico, è la marca lessicale di un boundary di lazy loading, leggibile dal compiler e dall’agente come confine di esecuzione. routeLoader$ è server-side per costruzione; component$ è il marker di un componente resumable.
Più rigido di altri framework, ma proprio per questo straordinariamente leggibile per una macchina: ogni $ è una dichiarazione formale di “qui succede qualcosa di specifico”, e non c’è ambiguità su cosa. Qwik non ha ancora il momentum dei framework principali, ma la formalità del modello lo rende particolarmente interessante per chi pensa al lungo termine.
React Router 7 (ex Remix)
Remix è diventato React Router 7, fondendo il framework e il router in un’unica entità. La mossa è coerente con la tesi di questo articolo: sempre meno pezzi separati, sempre più contratti integrati.
// app/routes/users.tsx
import type { Route } from './+types/users'
export async function loader() {
const res = await fetch('https://api.example.com/users')
const users = (await res.json()) as { id: number; name: string }[]
return { users }
}
export default function Users({ loaderData }: Route.ComponentProps) {
return (
<ul>
{loaderData.users.map((u) => <li key={u.id}>{u.name}</li>)}
</ul>
)
}Code language: JavaScript (javascript)ADX: pattern loader/component canonico, tipi auto-generati (Route.ComponentProps viene da ./+types/users) che fluiscono dal loader al componente senza che lo sviluppatore (o l’agente di turno) debba dichiararli. Un agente sa esattamente dove sta il fetch (loader, server) e dove sta la presentazione (componente, possibly client).
La fusione Remix => RR7 ha consolidato questo pattern come uno dei più puliti dell’ecosistema React, ed è uno dei pochi casi in cui un’evoluzione architetturale ha aumentato l’ADX invece di degradarla.
TanStack Start
TanStack rappresenta l’anti-modello dichiarato. La filosofia di Tanner Linsley è chiara: invece di un framework opinionato, primitive fortemente tipizzate e componibili.
// src/routes/users.tsx
import { createFileRoute } from '@tanstack/react-router'
export const Route = createFileRoute('/users')({
loader: async () => {
const res = await fetch('/api/users')
return res.json() as Promise<{ id: number; name: string }[]>
},
component: UsersPage,
})
function UsersPage() {
const users = Route.useLoaderData()
return (
<ul>
{users.map((u) => <li key={u.id}>{u.name}</li>)}
</ul>
)
}Code language: JavaScript (javascript)ADX: tipizzazione end-to-end fortissima: il tipo del loader si propaga al componente, ai search params, e a tutti i <Link> che puntano a questa rotta.
Per un agente TanStack è un terreno di gioco eccellente: gli errori di tipo intercettano gran parte degli output sbagliati prima che arrivino al review umano. Per un agente meno disciplinato che ignora i tipi, la verbosità diventa rumore. La domanda che l’era agentica solleva su TanStack è onesta: quanto bene si comporta quando metà del codice viene scritto da un agente che non ha le stesse intuizioni del team che ha scelto le primitive?
È una domanda aperta, e che vale la pena tenere aperta.
Cosa vede un agente quando entra in un repository
Vale la pena fermarsi e guardare nel dettaglio cosa accada, concretamente, quando uno strumento come Cursor, Codex o Claude Code apre per la prima volta una codebase. È il punto in cui le considerazioni teoriche si traducono in differenze misurabili e dove l’idea di “compressione cognitiva” smette di essere una metafora.
Codebase indexing
Il tool costruisce in background una rappresentazione strutturata del progetto. Le componenti tipiche di questa rappresentazione sono almeno tre:
- Una mappa dei file con metadata di base (path, linguaggio, dimensione, hash)
- Un set di embeddings semantici, calcolati su chunk di codice di dimensione variabile (funzione, classe, blocco di import, sezione di documentazione)
- Un grafo dei simboli pubblici (funzioni esportate, tipi, classi) derivato da analisi statica o da language server come
tsserver.
Cursor pubblica documentazione esplicita su questo (qui potete leggere un’ottima analisi), Claude Code fa qualcosa di simile in modo meno verboso. La qualità dell’indicizzazione dipende in larga misura da quanto la codebase è strutturata in modo riconoscibile: un modulo nominato users.ts con un export chiamato getUsers è infinitamente più trovabile di un’arrow function anonima passata a useQuery dentro un componente.
Quando arriva un prompt tipo “aggiungi paginazione alla lista utenti” l’agente non spedisce l’intero repository al modello. Fa un retrieval: combina ricerca semantica sugli embeddings, ricerca lessicale (tipicamente ripgrep sotto il cofano), e navigazione del grafo dei simboli per costruire un contesto rilevante.
Su questo contesto, e su una serie di tool come read_file, grep, find_references, edit_file il modello ragiona iterativamente. È un loop: il modello propone una query, riceve un risultato, propone un’edit o un’altra query, e così via, finché non produce il diff finale. Ogni passo costa token, latenza, e soprattutto è un’occasione per sbagliare strada.
Qui le convenzioni del framework cominciano a fare differenze concrete. In una codebase Next.js App Router, “trova la pagina utenti” si risolve nel primo passo: app/users/page.tsx esiste o non esiste. In una codebase Astro, “modifica lo schema dei post” è un singolo file in src/content/config.ts con uno Zod schema esplicito leggibile dall’agente esattamente come sarebbe leggibile per uno sviluppatore nuovo. In Angular moderno, gli standalone components con inject() esplicita dicono al modello cosa importare e da dove, senza che debba ricostruire la dependency injection a partire da decoratori sparsi. In SvelteKit, +page.server.ts dichiara lessicalmente che il file è server-side: un agente non può confonderlo con codice client.
In una codebase React vanilla con configurazione artigianale, niente di tutto questo è dato. “Trova la pagina utenti” si traduce in: grep -r "/users" su tutto il repo, parsing manuale del file dove <Routes> è dichiarato, navigazione di import, identificazione del componente, controllo se il fetch è dentro un useEffect, dentro un useQuery, in un custom hook, in un servizio API custom, in un loader passato come prop.
Ognuno di questi passi è una possibilità di errore. L’agente ricostruisce abbastanza bene nei casi comuni: è per questo che l’illusione “tanto ci pensa l’AI” è così seducente. Peccato che la varianza degli output sia alta, gli errori sottili siano frequenti, e il costo della review umana cresca in proporzione.
Su uno snippet isolato non si vede; su un team di trenta persone con dieci agenti attivi in parallelo, sì e si misura in PR rifiutate, regressioni in produzione, sessioni di debugging che non sarebbero esistite.
C’è poi un modello emergente… Il Model Context Protocol, standardizzato da Anthropic e adottato sempre più ampiamente da tool e framework, permette di esporre agli agenti non solo file ma capability strutturate. Un MCP server per un’app Next.js può rispondere a query come “elenca tutte le rotte”, “qual è il loader per /dashboard/[id]“, “quali Server Actions modificano la tabella users”, “qual è lo schema dei dati ritornati da getUserById“.
Un agente con accesso a un MCP server di questo tipo non fa più grep: fa query strutturate. La differenza è la stessa che passa tra cercare un’informazione leggendo migliaia di pagine di documentazione e cercarla con SQL su un database normalizzato.
Vercel sta spingendo in questa direzione esplicitamente; SvelteKit, Nuxt e Angular hanno iniziative analoghe in corso. Un framework che espone in modo nativo il proprio “MCP applicativo” (con tanto di rotte, layout, server functions, schema dati, configurazione di build) diventa, di fatto, una tool API per gli agenti.
È il completamento naturale della tesi della compressione cognitiva: prima il framework comprime le scelte attraverso convenzioni; poi le espone in modo machine-readable attraverso un protocollo. Tra cinque anni dare un repo a un agente senza un MCP server attivo sarà come dare un database senza un’introspezione dello schema. Tecnicamente fattibile, professionalmente discutibile.
Standardizzazione, frammentazione, e l’effetto Schelling
Abbiamo detto che la domanda all’inizio dell’articolo è “brutta e cattiva”… C’è però una domanda strategica che vale la pena porre apertamente: l’AI sta favorendo la standardizzazione dell’ecosistema o la sua frammentazione?
L’argomento per la frammentazione è intuitivo: se un agente può aiutarmi a usare qualsiasi framework, la barriera di adozione si abbassa, mille fiori fioriscono. L’argomento è plausibile in superficie, ma la realtà del training dei modelli racconta una storia diversa. Gli LLM sono distribuzionali: lavorano meglio sui pattern più rappresentati nei dati. I framework con più adozione, più documentazione e più codice pubblico diventano progressivamente più facili da generare bene. Gli sviluppatori scelgono quelli che gli agenti gestiscono meglio. Loop di rinforzo. Vincono i vincitori.
È un effetto Schelling-point, e vale la pena spendere due parole sul concetto perché spiega molto di quello che sta succedendo. Il termine viene dall’economista Thomas Schelling, premio Nobel nel 2005 per il suo lavoro sulla teoria dei giochi. Schelling chiedeva ai suoi studenti: “Devi incontrare qualcuno a New York domani, non potete comunicare in anticipo, dove vai e a che ora?” La risposta modale era “Grand Central Station, mezzogiorno”. Non perché Grand Central sia oggettivamente il punto migliore (qualunque punto della città funzionerebbe se entrambi ci andassero) ma perché è il punto focale che entrambi si aspettano che l’altro scelga.
Le persone convergono spontaneamente sui punti focali quando hanno bisogno di coordinarsi senza comunicare. Schelling chiamò questi punti focal points; oggi li chiamiamo Schelling points.
Nell’ecosistema dei framework, il meccanismo è analogo ma a tre attori.
- Gli sviluppatori vogliono scegliere un framework che gli agenti AI gestiscano bene.
- I produttori di agenti vogliono performare bene sui framework che gli sviluppatori usano.
- I framework vogliono essere scelti dagli sviluppatori.
Tutti e tre hanno incentivi locali a convergere sugli stessi pattern dominanti: quelli che hanno più rappresentazione nei dati di training, più documentazione pubblica, più issue risolte su GitHub, più esempi su Medium, dev.to e piattaforme simili. Ogni attore, individualmente, sta giocando una mossa razionale. L’effetto aggregato è la convergenza.
Questo non è semplicemente un effetto di rete. Un effetto di rete classico (Facebook, WhatsApp) deriva dal fatto che il valore del prodotto cresce con il numero di utenti. Lo Schelling point dei framework è più sottile: deriva dal fatto che la qualità degli output degli agenti cresce con la rappresentazione del framework nei dati. È un loop di rinforzo statistico. Più Next.js è documentato, più gli LLM lo gestiscono bene; più gli LLM lo gestiscono bene, più i team lo scelgono; più team lo scelgono, più documentazione e codice pubblico viene prodotto. Lo stesso loop, in senso inverso, penalizza i framework di nicchia: non perché siano peggiori, ma perché il loro corpus di training è più piccolo e quindi gli output del modello su quei framework sono mediamente meno accurati.
Le conseguenze pratiche sono ambivalenti. Da un lato, ottima esperienza per chi sta nel mainstream: meno fatica, meno errori, più produttività. Dall’altro, una concentrazione di mercato che andrà valutata con attenzione, soprattutto quando il “mainstream” coincide largamente con un singolo vendor, e nel caso di React + Next.js + Vercel + AI SDK, la concentrazione è già reale.
C’è anche un effetto secondario meno discusso: lo Schelling point premia anche le versioni di un framework, non solo il framework. Un agente lavora meglio sull’App Router che sul Pages Router perché c’è più codice App Router nei training set recenti. La conseguenza è che restare su versioni vecchie di un framework opinionated (anche se tecnicamente funzionano) diventa progressivamente un costo nascosto in termini di ADX.
La pressione a stare sull’ultima major aumenta, e con essa la frequenza di migrazioni dovute non a bisogni di prodotto ma a bisogni di leggibilità per gli strumenti.
Cosa cambia per i senior e per i team
Per chi guida architetture, l’era agentica introduce un cambiamento di ruolo che vale la pena nominare. Il senior smette progressivamente di essere “chi scrive il codice difficile” e diventa “chi progetta i confini dentro cui l’agente può scrivere senza fare danni”. È un lavoro meno visibile e più strategico: definire convenzioni, stabilire invarianti, decidere quali astrazioni sono leggibili e quali no, scegliere framework opinionated abbastanza da essere navigabili.
Il code review cambia natura. Quando una PR di trecento righe è stata generata in dieci minuti, il revisore umano non può più fare lo stesso tipo di lettura granulare. Deve fidarsi del framework, dei tipi, dei test, e concentrarsi sugli aspetti che la macchina non vede: coerenza architetturale, decisioni di prodotto, allineamento con il sistema esistente. È un mestiere diverso, e va imparato.
Le decisioni di adozione tecnologica si pesano diversamente. “Abbiamo libertà totale” smette di essere un argomento a favore di uno stack. “Il nostro stack è leggibile e prevedibile per gli strumenti che useremo nei prossimi tre anni” diventa una preoccupazione di prima istanza. Non è una resa al mainstream: è una valutazione realistica del costo che comporta uscirne.
E c’è il debito tecnico generato dagli agenti, che ha una forma sua: codice plausibile, sintatticamente corretto, che funziona nei casi testati e si rompe in modi sottili nei casi non testati. È un debito tecnico particolarmente insidioso perché sembra finito. Architetture con convenzioni forti lo limitano alla radice, perché restringono lo spazio dove un errore può nascondersi.
Quattro scenari a tre-cinque anni
Vale la pena chiudere disegnando, sobriamente, qualche scenario.
Nel primo, convergenza dei protocolli: il modello Next.js + Vercel + AI SDK + MCP diventa lo standard de facto, e l’ecosistema si polarizza tra “framework-as-protocol” maturi e librerie composte residuali. È lo scenario più plausibile a breve termine, ed è già parzialmente in corso. Il rischio è la concentrazione di mercato.
Nel secondo, vittoria dei compiler-first: la prevedibilità del codice generato da Svelte, Solid e simili si dimostra un vantaggio decisivo per gli agenti, e una nuova generazione di framework con compiler ancora più aggressivi, React compreso, ridisegna il panorama. È uno scenario tecnicamente affascinante, e non così improbabile come sembra.
Nel terzo, frammentazione assistita: i tool agentici diventano abbastanza bravi da neutralizzare il vantaggio dei framework opinionated, e ecosistemi composti come TanStack tornano competitivi grazie alla portabilità. È lo scenario meno probabile a tre anni, più probabile a sette.
Nel quarto, il framework diventa invisibile: l’agente sceglie, configura e gestisce lo stack al posto del team, e la conversazione si sposta dal “quale framework” al “quale obiettivo di prodotto”. È lo scenario più speculativo, e pone domande serie su autonomia, debugging e ownership delle decisioni architetturali. Ma non è fantascienza: è già la traiettoria di tool come Devin o di alcune feature autonomous di Claude Code.
La domanda giusta
Il dibattito su framework e AI è stato finora dominato da due narrative opposte e ugualmente sterili. Da una parte i catastrofisti, che annunciano la morte del frontend a ogni nuova release di un agente. Dall’altra gli ottimisti professionali, che fingono che nulla sia cambiato e che la solita curva di apprendimento basti.
La realtà, per chi lavora davvero su codebase complesse, è meno spettacolare e più impegnativa. I framework JS non stanno morendo. Stanno cambiando padrone cognitivo. La metrica che li ha guidati per dieci anni (l’ergonomia del singolo sviluppatore) sta cedendo il passo a una metrica nuova: la leggibilità collettiva, dove “collettivo” include una flotta crescente di lettori artificiali.
I framework che hanno investito in convenzioni stabili, compiler intelligence, tipi end-to-end, server boundaries esplicite e metadata strutturata si troveranno, semplicemente, nel posto giusto. Non per fortuna, ma perché stavano già costruendo le feature di cui questa fase ha bisogno.
La domanda operativa per chi legge non è “quale framework scelgo”. È più scomoda: quanto della mia codebase è leggibile senza il mio cervello in mezzo? Se la risposta è “poco”, il problema non è l’AI. È un debito di leggibilità che esisteva già, e che l’era agentica si limiterà a far emergere più in fretta, e con meno cortesia, di quanto avrebbe fatto un nuovo collega.
I framework sopravvivranno. Cambieranno destinatario. E i team che lo capiranno per primi smetteranno di chiedersi se React, Next, Svelte o Astro stiano morendo, e cominceranno a porsi una domanda molto più produttiva: la nostra architettura è leggibile da chiunque o solo da noi?
