Starting to work in the processing of big data could be unsettling even for a developer who has solid foundations and experience in areas more related to “consumer” products.
The software tools and computational systems for data science, in fact, have peculiar characteristics related to both the practical needs of big data processing and storage infrastructure. Therefore, as part of the processing of big data, it is necessary to manage where data comes from, but also the fact that actual processing takes place through specialised frameworks (software) that interact with distributed (hardware) systems.
At Codemotion Milan 2018, Don Kelly presented a brief introduction to neophytes to Apache Spark, the open-source, fast and general cluster computing system for big data. As clearly stated by Kelly, developers have to know how Spark (and similar frameworks) acts and works in order to overcome its pitfalls and operate effectively.
Smart Processing for Big Data
Apache Spark can be described as distributed framework/platform for data processing that can operate well in both batch and streaming modes. Its peculiarity compared to similar frameworks (i.e. MapReduce) is the core engine that operates on multi-stage and in memory, providing the best performances for some kinds of application, such as iterative algorithms or interactive data mining. In short: Spark does machine learning.
Apart from its features, when approaching to big data elaboration with Spark there are three main concepts to understand and master: what is a Spark application, how data is structured in Spark, and processing is applied.
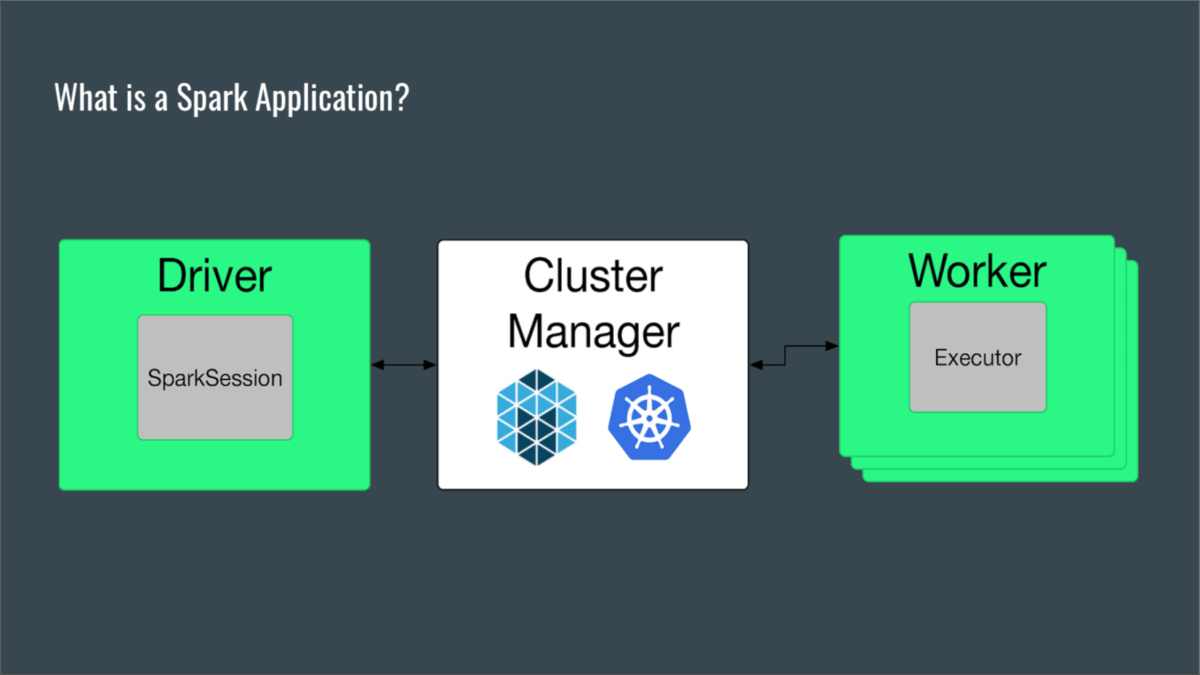
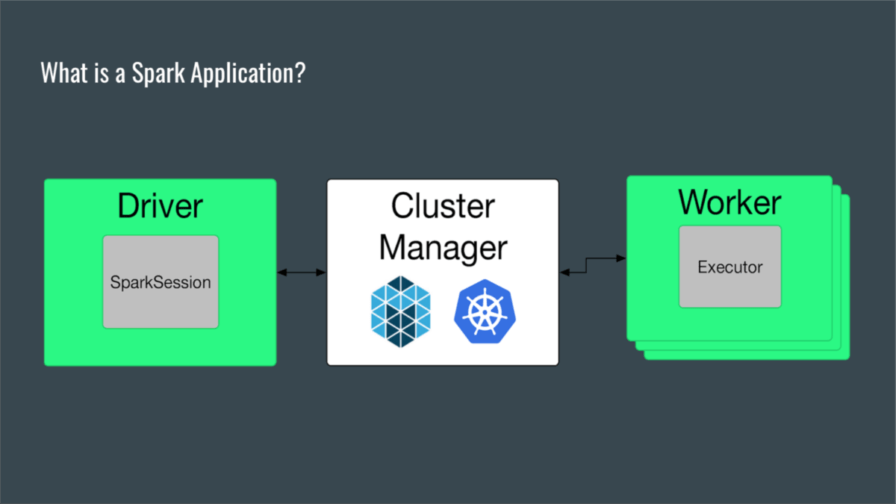
A Spark application is a self-contained computation that executes supplied code on supplied data to compute an output. The application execution involves components such as driver, session, worker and executor, but basically, a single driver process is mapped to a set of executor processes, ideally distributed over a cluster.
Applications will work, of course, over data and Sparks provides optimised data structures that can be accessed as DataFrames or DataSets. Data is internally arranged as DataSets, in a tabular format in memory – one of the peculiarities of Apache Spark is that of maximising the use of data in memory and minimising disk accesses – and partitioned to be allocated over single executors.
The processing that executors will apply to data consists of two kinds of operations: Transformations and Actions. A Transformation produces a new DataSet starting from an existing DataSet and it’s applied lazily, i.e. it will get executed when an Action will be called. Basic examples of transformation are map() and filter() functions. On the other hand, as Kelly said, Actions materialise the data, i.e. they produce an output that is not a DataSet and values produced by Actions are stored to drivers or to the external storage system. A basic example of action is count() function.
Tactics to Effective Spark Application
This is, of course, a really short introduction to Spark. Even so, there are some tips from Don Kelly for a wise approach to your first Spark application.
First of all, start thinking in SQL, then optimise. When building a Spark application, consider that structured APIs for Spark are designed to look like SQL. This means that for any performance issue you could have performing an operation on data with basic SQL, the same will also arise in Spark.
The next focus area is about data management in the application’s code. Please consider, in fact, that Spark is already optimised to perform any kind of data transformation and any attempt to perform “custom” transformation can negatively impact those Spark optimisations. So act to clean and optimise your data, but do not overwork with your code: let Spark do what it’s best suited for.
Another important aspect to be considered is the intrinsic clustered and parallel nature of actual computation, based on Spark partitions and executors. You have to prevent and avoid situations where there is one partition for many executors as well as many partitions for one executor. The best action is to tune partitions for the actual job, trying to avoid any kind of skewness, because even if Spark will do its best to guess the partition size, sometimes it could be wrong.
The final hint and notice is about the lazy nature of Spark elaboration. As Kelly pointed out, nothing is real until an action runs. So any error in your work, for example applying some mapping or filtering on data, could actually surface a long past where they occurred. Be wise and prepare some clever logging to help with any debug you could need to do later.



