
Legend says it was written on the back of a napkin. In 2013 Jeff Dean, Google‘s Head of AI, did some calculations and realized that if all the Android users in the world used their smartphone speech to text feature for one minute each day, they would consume more of the all compute resource than all Google data centres around the world (at that time).
Part of the reason of this situation was and is related to the evolution of computer processors and chips (Moore’s law) as well as to the exponential growth of use cases, devices and connectivity.
From here emerges the need in the present day of more specialised hardware, domain specific hardware, whether it’s related photo recognition via AI or query processing in big data land.
Google‘s TPUs are domain specific hardware for machine learning, a project started in 2013, first deployed in 2015 with TPU v1. Yufeng Guo, Developer Advocate at Google, told at Codemotion Milan 2018 about the characteristics and evolution of TPUs and how this product represents a real accelerator for machine learning.
Early days of TPU v1
The v1 is still in use, but was not released publicly. It’s basically a PCI Express slot, suited for existing hardware datacenter infrastructure, and was used for Search (search ranking, speech recognition), Translate (text, graphic and speech) and Photo (photo search) – i.e. Google products performing large ML task with a lot of users at that time.

It is an early stage product; for example it only makes predictions (a.k.a. inference), not training. However, it was the foundation of a different kind of hardware for machine learning.
In fact, although reading the specifications could be that the TPU v1 was equipped with a slow chip if compared with other available processors, the performance in terms of calculation and watts consumed tell a different story.
The starting point for the chip and board implementation is the fact that the neural networks are basically a series of multiplication and addition operations. Hence two insights: on the one hand the fact that it is possible to operate these operations by matrix calculation, on the other the fact that neural networks allow some kind of fuzzy math.
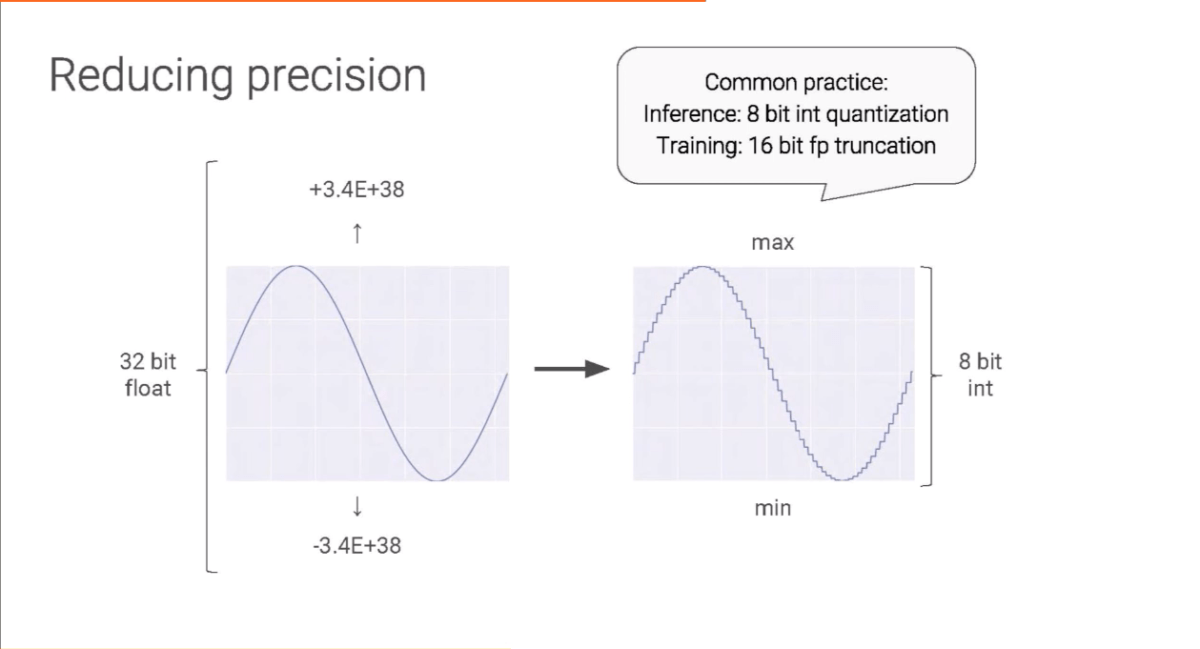
In realizing the v1 chip, the choice was to invest in a processor capable of running quickly on matrices and to reduce precision through quantization, operating on 8-bit integers instead of 32-point floating points. Moreover, operating on matrices of data – systolic arrays – reduces the reading and storing data cycles. These design choices allow, among other things, to have 25 times the number of multipliers – compared to other similar processors – in a smaller chip, with less heat produced, less silicon need.
So while the v1 runs at 700Mhz and has no threading, no multi-processing, no branch prediction, it was able to process a very large amount of data per second.
Evolving in v2 and v3 for learning
Google teams quickly iterated over it and made TPU v2 in 2017. It was a bigger board, providing four processors instead of just one, with big heatsink, and loaded into dedicated infrastructure and hardware for holding in datacentre.
TPU v2 was designed to perform both inference and learning tasks. The computations necessary for learning have different requirements than those for prediction; more precision is needed (therefore a less aggressive quantisation of data), maintaining and possibly improving the speed and space required.
So, how can you have good performance without losing the necessary precision that means the training doesn’t fall apart? It’s simple: invent a new float type, bfloat16. bfloat or brain float, allows within 16 bit the same full range of values of standard float 32 (from 1E-38 to 1E+38), by dropping the decimals.

In 2018 Google released TPU v3, with improvement on heat sink system and, of course, in performance.
Use a TPU Pod
TPU boards are used in a distributed system known as TPU Pod, that hosts 64 TPUs. All those TPUs are connected to their own dedicated host: no CPU, no main memory, no disk.

This configuration allows to use a full Pod or a subsection of a Pod as one machine. Your code for one TPU is essentially the same as for all 64 TPUs in a Pod. Dedicated compilers will take care of it. The advantage of this configuration is that you can choose how much per hour paid resources you want to allocate, reducing or increasing the time required to perform the learning phase. A learning task that could require about 10 hours running on a single TPU, goes down to 30 minutes if using half a POD.
Programming for TPU with TensorFlow framework was also made simpler by Google. The same codebase and the same API can be used when running the code on different targets (local workstation, TPU, TPU Pod), just change to the specialised estimator for TPU.

TPUs can be used effectively when there is a the need for tons of matrix operations or large models with large batch sizes. For instance, they are really good at processing images data, but you can take you own your non-image data and turn them into formats, structures that are more suitable for pushing through the TPUs.
The high optimisation of operations on TPU matrices also means that to have the best performance, it is useful to consider the actual size of the matrix in the chip. Having to process a batch of images, all of a certain size in pixels except one that it’s just one pixel bigger, it would be more efficient to cut away that extra pixel before processing the data from the TPUs.
While it’s not like using microcode for programming chips, it’s also true that this kind of domain specific hardware could require a knowledge of how it works internally to get the best from it.



