
- What is Data Cleaning?
- Is Data Cleaning Essential?
- What are the Benefits of Data Cleaning?
- Remove Unwanted Observations
- Filter Unwanted Outliers
- Avoid Errors Like Typos
- Convert Numbers Stored as Text Into Numbers
- Deal with Missing Values
- Convert Data Types
- Get Rid of Extra Spaces
- Delete All Formatting
- Data cleaning: recap
Data is an essential part of data analytics, data security, and data science. That’s obvious. Sometimes, however, that data can get a little dirty. No, not like in a gangster film. More like where suddenly we are having to deal with ‘dirty data’ after a hold up at a data centre. When there is a mistake in the spelling, arrangement, formatting, or construction which has made that data unclear. For these reasons, every so often you need to apply data cleaning.
Data cleaning may seem like an alien concept to some. But actually, it’s a vital part of data science. Using different techniques to clean data will help with the data analysis process. It also helps improve communication with your teams and with end-users. As well as preventing any further IT issues along the line.

Unfortunately, data cleaning can take up a huge chunk of time for data scientists. Yet, as having poor or wrong data can be detrimental to a task, it’s an important thing to do. It’s not all bad, though. High-quality data that has been cleaned can make your job so much easier.
So, professionals must know techniques to perform it properly and efficiently. Then you can get on with other work. Like developing a cloud contact center. Or making amazing AI.
Of course, different types of data require different types of cleaning. But there are general approaches that make a good starting point. Here are eight techniques for essential data cleaning.
What is Data Cleaning?
Before we jump in, it’s important to know what data cleaning actually is. It’s the process of identifying and removing or fixing ‘bad’ data. This is usually inaccurate, unreliable, or unfinished data from databases or tables.
The data then needs restoring, removing, or remodelling. Sometimes, if the data is dirty or crude, it needs removing completely.
For example, say it is your job to handle the data on platforms for eCommerce sites. If the data you put out is bad, this can create problems on the site that lead to a loss in profit and reputation. Such as the wrong items being advertised next to the wrong description.
Data cleaning can be done either interactively with data cleansing tools or as batch processing through scripting. After it has been cleaned, the data needs to match up with other related datasets in operation.
Is Data Cleaning Essential?
Although it isn’t spoken about as often as it should be, data cleaning is an essential part of a data scientist’s job. Especially as more industries than ever are adopting some sort of cloud storage. As the use of data storage grows, the more likely there is to be a problem.
For example, say a company uses a hosted predictive dialer to contact clients. They will have a large volume of customer information stored as data. If the data stored is not clean – i.e., the wrong name is next to the wrong number – agents run the risk of making mistakes when contacting clients. Which can lead to a few disgruntled customers, to say the least.
This means that as a professional in the IT industry, it’s your job to make sure things run smoothly in this area. And a huge part of that involves data cleaning.
What are the Benefits of Data Cleaning?
As well as helping other companies, data cleaning makes your job as a data professional easier too. Whether you are working on deep learning or developing a site, these are just a few ways in which it will help you in your work:
- Efficiency – Cleaning data helps you perform your analysis faster. This is because having clean data means you avoid multiple errors, and your results will be more accurate. Therefore, you won’t have to re-do the whole task due to false results.
- Error Margin – Although you may be very eager to get results, if the data isn’t clean, the results won’t be accurate. That means when you present the work, the outcome may not be true. Therefore, getting used to cleaning data means that you adopt the practice of slowing down and fixing data before presenting it. Leaving less room for mistakes.
- Accuracy – As data cleaning takes up so much time, you will soon learn to be more accurate with the data entered in the first place. Of course, data cleaning will still be needed for other reasons, but doing it gets you used to being more precise in the first place.

Now that we have gone into a little extra detail about how important data cleaning is, let’s take a look at the actual techniques.
Remove Unwanted Observations
The first thing you need to do in setting up data cleaning is to remove unwanted observations. This includes removing duplicate or irrelevant observations.
Duplicate observations will most likely arise during data collection. They usually happen when you scrape data or combine datasets from multiple places. They can also occur when you receive data from clients or other departments. For instance, a user may have accidentally entered their details twice. Duplicates will only increase the amount of data you have and can end up wasting time.
Irrelevant observations are ones that don’t fit with the issues you are trying to solve. For example, say you are building a virtual office phone service. You will want anything to do with phone numbers in there. But you won’t want anything to do with social media. Focussing on this point first will prevent any problems that may pop up down the line.
Make sure the data definitely is irrelevant and that you won’t need it further down the line, say for something like correlated values. Once you are sure of that, get rid of it!
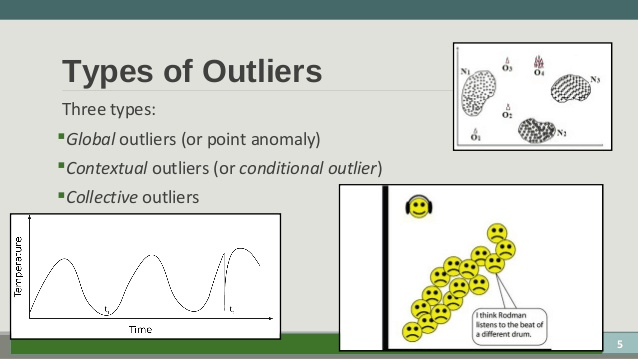
Filter Unwanted Outliers
It’s important to get rid of unwanted outliers because they can cause problems with certain models. Linear regression models, for example, are less robust to outliers than decision tree models.
Removing outliers will help with the model’s performance. But, there does have to be a legitimate reason to remove them.
Say, for example, you are creating a database of information connected to a digital handbook maker and there are lots of facts and figures in there. Just because a number may be a big number to input, it doesn’t make it an outlier. That large number may at some point become informative to your model.
However, if there is a legitimate reason that it seems like the outlier should be removed, then it is important to do so. This could be something like a suspicious measurement that is likely not to be real. Like, if someone has entered their phone number as 012873839283228343273, you know it isn’t a true value and is an outlier you can get rid of.
Avoid Errors Like Typos
Typos are easy mistakes to make. And without something like spellcheck, they can often go unnoticed. However, spelling is essential to fix, as models treat different values differently. Strings, for example, rely a lot on spelling and letter cases.
Several pieces of essential technology use algorithms and techniques that do fix typos. Mistakes can be mapped and converted into the correct spelling.
Although it may not seem like a big deal to a human, a computer doesn’t think like that. For example, there is a difference between putting in Robert and robert. The capitalization can have a significant impact.
Another example is using the US spelling ‘optimize’ and the British spelling ‘optimise’. They are the same word but spelt differently.
One more example is seen in making a mistake like spelling ‘Mike’ as ‘Mice’. They have the same number of letters but are spelt differently.
You might need to also consider the string size. You might have to change them to make sure they are kept in the same format.
It might be that your dataset requires you to have five digits only. So, if you have a digit like 3332, you will have to put a zero in front. This keeps your data uniform. You will also need to remove your whitespaces for the same reason. Removing them from strings keeps them consistent.
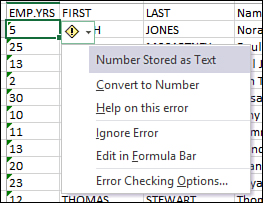
Convert Numbers Stored as Text Into Numbers
It doesn’t matter if it’s a link building article or a customer phone number, mistakes are often made when numbers are entered.
For example, an address may be entered as:
12 3 House Street, New York
or,
1A23 House Street, New York
or even,
%123 House Street, New York
This makes ‘unclean’ data, and needs to be sorted out on the back end to keep things smooth.
If there are any mistakes with numbers being entered, they need to be changed to actual readable data. All of the data here will need to be converted so the numbers are readable.
To convert the numbers, you will need to go to the formatting box and type in “general”. Alternatively, opening up a dialogue box and then copying, pasting and multiplying from blank cells should help with that issue.
Deal with Missing Values
Missing values can’t be ignored. Knowing how to handle them will keep the data clean. You may even have the problem of having too many missing values in a column. If this happens, there may not be enough data to work with, so it might just be easier to delete the column.
However tempting it might be, missing values should not be ignored. If you want to keep end-users engaged, then every step needs to be done properly. This means putting in the extra effort and doing your best to get accurate results with all data. Which includes dealing with missing values.
Otherwise, there are ways to input missing data values. This is done by estimating what this missing data might be. Linear regression or median will help calculate this. However, it won’t be the real value, so still won’t be accurate.
Another method is to copy data from a similar dataset, but this might also record inaccurate results. So, you can always inform the algorithm that the data is unavailable or ‘missing’. You may have to select ‘0’ in some cases.
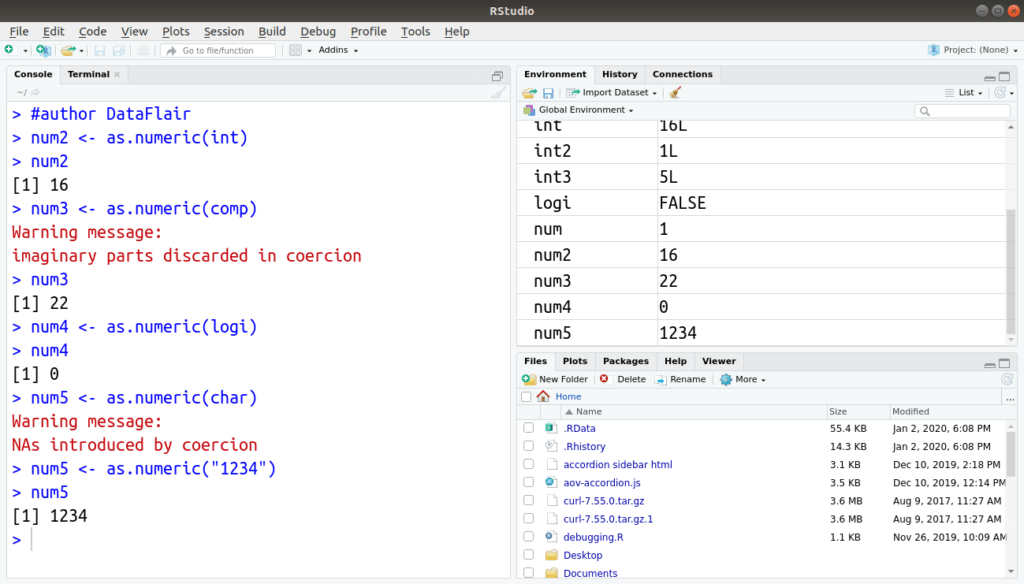
Convert Data Types
All data types must be the same across the board. A numeric can’t be a Boolean and a string can’t be numeric.
When converting data types, numeric values need to be kept as numeric values. Numerics shouldn’t be entered as strings and data that can’t be converted should be entered as N/A. Don’t forget to have the warning to say it is wrong.
Making sure that all data is converted helps anyone in the company who has to deal with the data. It even helps people like cybersecurity experts encrypt and protect data properly, if there aren’t mistakes that hackers can easily access.
Get Rid of Extra Spaces
Spaces are missing from data more often than you may think. They often come from colleagues who send over work from text files imported from a database.
Say, for example, a teammate is trying to set up a call forwarding service. They want you to collect and analyze the data. However, it looks like this:
Please call me on 0844123123
Or,
Please call me on 0844123123
Or even,
Please call me
on 0844123123
To deal with these issues, you will need to use the “trim” function.
Syntax: =TRIM(Text)
This function takes away all of the spaces and corrects the problem.
Delete All Formatting
Often, computers tend to automatically format written information. But for the sake of keeping things uniform with data, you need to clear all the formatting.
This is really great when dealing with something like a vanity number for customers who want specialist contact information. This is because they don’t use generic numbers, so although the computer may format their information, it will need to be unformatted to keep their information separate and special.
There is a way you can delete all formatting. This is done by selecting all the data. Then go to Home –> Clear –> Clear Formats.
Data cleaning: recap
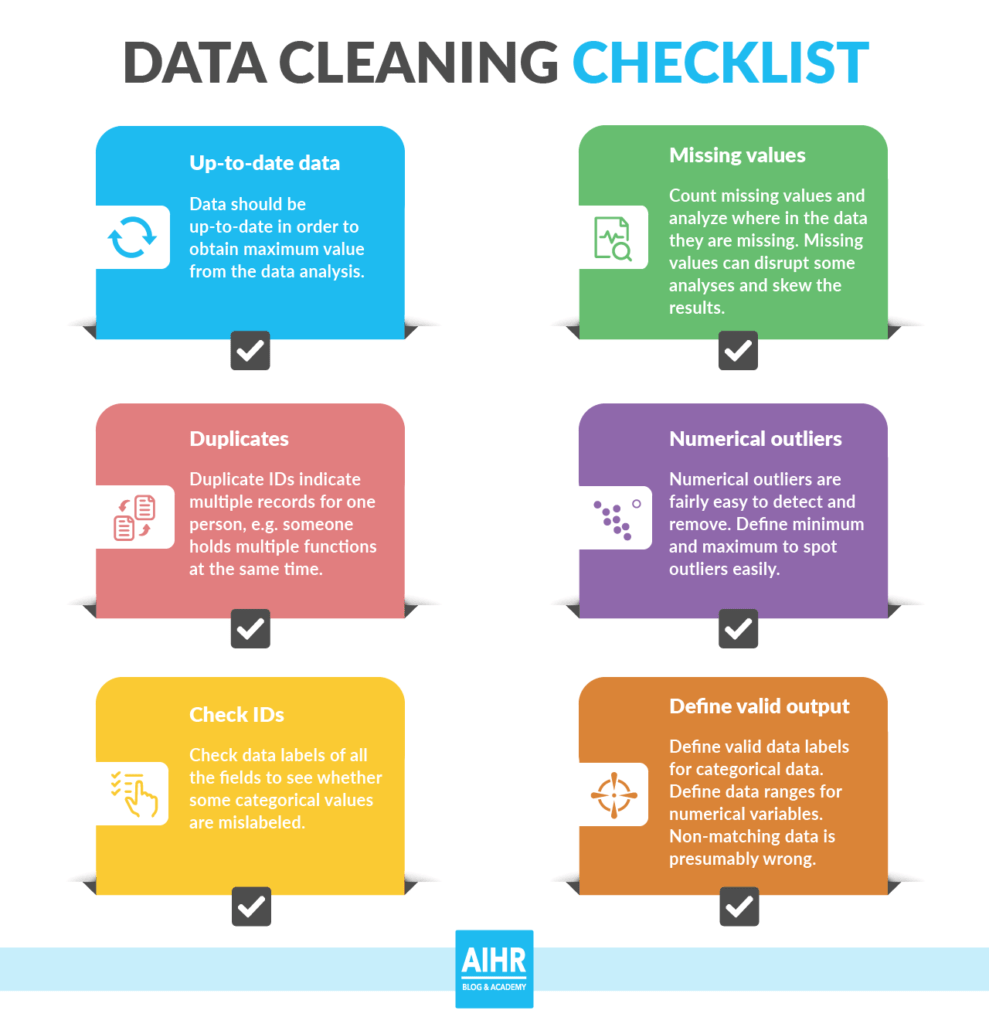
Knowing how to do data cleaning properly is all part of being a great data scientist. Getting data cleaning correct prevents any issues from occurring in the future. Data cleaning helps you to do your job properly and, in turn, allows you to do the best job you can to help companies move forward with their goals.



