
A/B testing is a well-known approach for determining which of several options will work best for your users. However, it also has some well-known issues. In this talk at Codemotion Amsterdam 2019, Claudia Vicol (head of Platform Infrastructure Data Engineering at eBay’s Marktplaats), presented an alternative approach.
eBay Marktplaats
Marktplaats is one of the largest online marketplaces in the Netherlands. Over half of the population has used it to buy or sell in the last year and they get 8.2m unique visitors a month, viewing over 1 billion adverts. Unlike the classic auction-based eBay, Marktplaats is part of eBay Classifieds.
Since they make money on every sale, it is in their interest to encourage users to make more purchases. One of the main ways to do this is the recommender system that suggests other products when you look for an item. The problem is, testing alternatives is risky – if you get it wrong, you lose money. Also, the limited screen space, particularly in the application, leads to pages becoming “sacred”, with product owners refusing to allow them to change. So, how can you test alternative recommenders efficiently?
A/B Testing
The classic approach to testing alternatives in any user-facing application is A/B testing. Here, the user base is divided into equal groups, with each group seeing a different version of the page. After a couple of weeks, you look at the data to decide which page performed best. For instance, you might split users into three groups. Each group sees a different version of the recommender. As an example, if a user looks for a new tablet, the recommenders might show other offers for that same tablet, other tablets with a similar specification, or accessories for the tablet. After two weeks, the group that made the most purchases is the “winner” (eBay measure success as the return per 1,000 clicks). This is the so-called greedy approach because it is greedily trying to maximise the return.
Sadly, there are a lot of problems with this approach:
- By definition, most of your users are being shown a suboptimal recommender for the duration of the experiment. This is a huge cost for any experiment.
- A/B testing isn’t personalised. People are randomly assigned to the groups with no effort made to categorise them.
- It isn’t repeatable. Often, the next time you run the exact same experiment, a different winner will emerge.
- It is really hard to do this across wide geographical areas.
- Only a single experiment can run at a time. This is a big drawback when there are multiple teams queuing up with new things to try.
A better way?
The solution must be to stop experimenting. Or rather, to try to minimise the impact of the experiments while maximising their efficacy. In other words, balance the exploratory phase (where you try to find the best recommender) with the exploitation phase where you actually generate sales from the recommender. This is actually a very common problem. For instance, it’s the same as the problem facing news sites when choosing the best headline for an article. The solution is to use a concept from probability theory known as the multi-armed bandit (or MAB).
Conceptually, the multi-armed bandit assumes you enter a casino. You are faced with a number of slot machines with different rules and payouts. Some machines will pay out small sums regularly, others may pay out large sums, but only rarely. You have limited resources, but you want to know how to maximise your winnings across the night. Importantly, before playing, you have no prior knowledge of the rules for each machine. If you had infinite time and money, you could easily solve this. But you only have a fixed time and limited money.
Epsilon-greedy method
The first MAB solution that Marktplaats looked at is called epsilon-greedy. Epsilon-greedy has an exploration phase where you quickly pick the most successful strategy. During this phase, people are shown a random recommender. Then there is an exploitation phase, where you show, say, 90% of users the best recommender and the other 10% are shown a random choice (where 10% = epsilon = 0.1). You can either go straight to the exploitation phase after one round, or you can be more nuanced and home in on the most successful recommender slowly, as shown below.
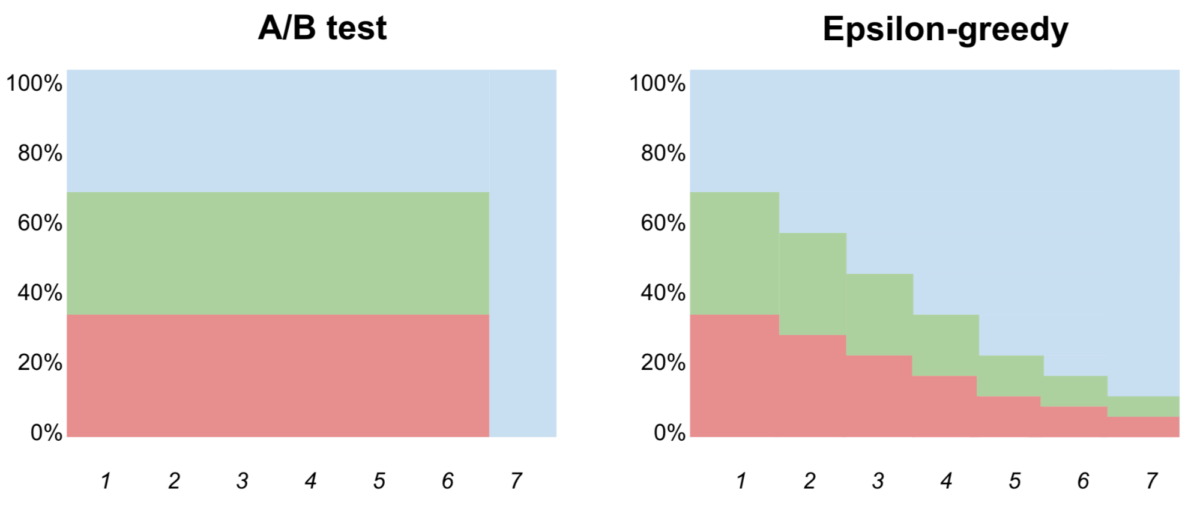
While this approach gave eBay double the revenue of the random A/B testing method, it still has drawbacks. Firstly, it still isn’t personalised. Secondly, it homes in on a different choice each time it is run.
Contextual bandits with Thompson sampling
Ultimately, Claudia’s team focused on a different approach to solving the MAB problem. Namely, Thompson sampling (so-called after William R. Thompson). Thompson sampling isn’t greedy. Instead, it uses a Bayesian approach. As Wikipedia says, it tries to choose the action that “maximizes the expected reward with respect to a randomly drawn belief”. Rather than randomly assigning users, it is able to use complex vectors of features when choosing which recommender to assign a given user. In eBay’s case, they chose the last five categories the user has visited and whether they are on a mobile or desktop.

The process chooses one of five possible recommenders, using a naive Bayesian classifier to predict which recommender will perform best for a given set of visited categories. In total there are 32 categories, so there are potentially over 200,000 combinations. Initially, the probability for each is set to 0.5 (50%). Success is when a user clicks on the recommender. Each time it runs, the probabilities are updated to favour the variant with the highest reward. Quickly the least successful variants are eliminated. After a while, you are able to generate a sorted list of the performance of each variant.
Are there any drawbacks?
One big problem with this approach is it takes twice as long to “unlearn” a choice than it does to learn. In the world of classified ads, this is a problem, since people’s behaviour changes significantly with the seasons. Another trap (which Claudia herself fell into) is if you reverse the order of the sort. That led to a brief period where people were being shown the least successful recommender! A more technical problem is that many of the probabilities soon become vanishingly small. A solution there is to use an exponential weighted moving average. Claudia also came across another problem related to how the list was being sorted. Most programming languages use a stable sort algorithm. This meant that the same choices were always favoured. Fortunately, the simple solution here is to shuffle the list first.
Conclusions and Advice
MAB is clearly a good solution, but it isn’t quite there yet. Claudia still hasn’t solved the problem of what to do when trends change. In other words, it gives good results in the short term, but not in the long term. One key issue when running multiple experiments in parallel is knowing how to measure success. How do you equate different measures such as revenue generated and number of reviews? And Claudia will never again forget which order to sort the list in!
Claudia ended by answering a couple of key questions. Firstly, how do they know when to unlearn? Having run one of their experiments continually for six months, they have seen that they definitely need to be able to unlearn. But it is easier to simply reset the experiment periodically. Another key question is related to whether they had tried doing this on historical data. The issue here is that the trends change, so historical data isn’t helpful. It would also require them to create a simulator to replay the data. Fortunately, eBay was prepared to let them develop and test this system in production.



