
Document processing is a vital concern for many businesses. But the process itself can be highly resource-intensive. From gathering to classification, data extraction, analysis and presentation, there are many stages to processing documents and each can be resource-intensive. Traditionally these have been done manually, with human agents required to comprehend, summarise and cross-link different information sources. However, the recent rise in artificial intelligence (AI) and machine learning (ML) technologies means that this workflow can now be automated, yielding great savings in time and efficiency.
Machine learning’s applications are increasingly well-known across many domains. Text generation, image processing, automated decision making and many more applications are now commonplace. But to be effective, ML requires large datasets and significant infrastructure, which are not always feasible for smaller organisations. However, with recent advances in cloud computing and serverless architectures, ML models can provide easily accessible public resources for training, storage and processing.

For this article, we’re drawing on insights from Capgemini, a world leader in data management and processing. We’ll look at the benefits of cloud-based ML document processing, before considering how to write microservices using Python and Google Cloud. We’ll also take a closer look at how Capgemini trains ML models on textual features to give you a lead in developing your own intelligent document processing systems.

Machine learning models in the cloud
Machine learning is the process by which software applications gain the ability to reproduce processes and tasks without specific programming. However, since it uses the resources generated by previous human endeavours to learn this expertise, a large amount of data is required to produce stable and accurate patterns of behaviour. Cloud computing allows users of ML models to train and deploy systems at scale using microservice architectures. They are thereby relieved of the burden of procuring and managing their own infrastructures.
What is often referred to as AIaaS (Artificial Intelligence as a Service) has become increasingly common as a means to leverage ML solutions without massive capital investment. The pricing model of on-demand, serverless systems means that users only pay for what they need. Furthermore, inherent flexibility means that projects can scale (or contract) as required, allowing a more experimental approach that can be beneficial to innovation
Advantages of the ML cloud for document processing
In the main, document processing has traditionally been a manual task, requiring much time and effort. Facilitated by cloud and serverless infrastructures, ML models now allow organisations to streamline document processing by generating expertise from massive datasets. There are several benefits to this approach.
- Speed. Manual document processing can be a major bottleneck in business workflows. Machine learning systems reduce this dramatically.
- Accuracy. With ML applications, human mistakes are minimised, reducing the risk of costly errors that may induce financial or other liabilities.
- Scalability. If workloads increase rapidly, cloud-based ML systems can quickly scale to meet the needs, without the need for extra recruitment and staff training.
- Compliance. Automated systems make it easier to enforce compliance standards for both regulators and customers.
Using Google Cloud: apply intelligent process automation pipelines
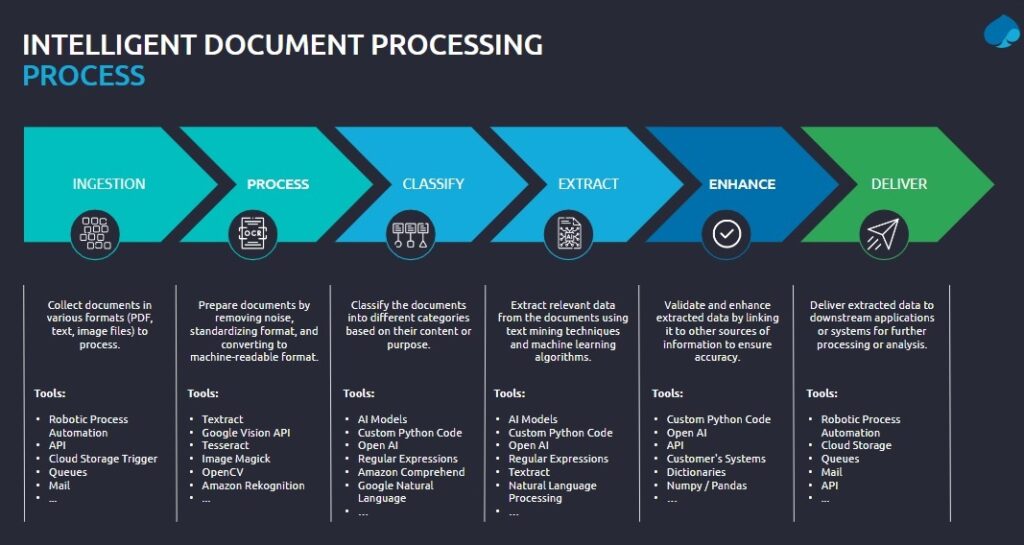
Google Cloud is a widely used platform that offers modular solutions for a range of computing tasks, not least AI and ML applications. For machine learning in particular, Google Cloud provides a flexible and scalable architecture for the training, analysis and evaluation of ML systems. Specifically, MLOps, a branch of DevOps, allows users to set up and manage ML workflows as AI Platform Pipelines. For Capgemini, this provides a suitable infrastructure for their document processing workflow, which has the following stages.
- Ingestion. An automated process gathers documents in various formats, using cloud storage triggers to transfer them for processing.
- Process. Documents are prepared by conversion to standard machine-readable formats using tools like Textract, Google Vision API and ImageMagick.
- Classify. Using AI natural language processing (NLP) and custom Python code, documents are read and categorised by content or purpose.
- Extract. NLP, AI models and custom code are used to mine the texts for relevant data.
- Enhance. The extracted data is validated and enhanced by linking it to other sources with further AI processes, as well as customer systems and data dictionaries.
Deliver. Data is delivered to downstream applications via cloud storage for further processing and analysis.
Writing Microservices in Python
To leverage the power and flexibility of serverless cloud solutions, many are now utilising microservice architectures. Microservices allow you to structure your ML application as a series of loosely coupled services. Using lightweight protocols, a microservice infrastructure can easily scale to meet application needs in terms of both capacity and complexity. In particular, given the massive infrastructural demands of machine learning applications, microservices provide the entry point for data-rich training, analysis and storage requirements.
Python is a great choice for developing your microservices architecture. Its adaptability, readability and wide support make it one of the quickest and easiest ways to code ML systems. Another useful component of your microservices toolkit is Docker, which you can use to manage containers for your services. With Python, you can code encapsulated software packages for each component of your workflow and deploy them as microservices using Docker containers.
In terms of deployment options, Google Cloud offers an excellent cloud-native serverless architecture. Google Kubernetes Engine (GKE) provides a managed container service with automated management. That means you need have no ongoing configuration or monitoring requirements, and little expertise in the way of cluster operations. However, GKE also gives you full control over all aspects of your infrastructure should you want it.
An alternative is Google Cloud Run, a fully-managed serverless platform that supports stateless microservices without the need for more complex Kubernetes features. The combination of CloudRun and Google Workflow provides a powerful serverless architecture that makes it easy to orchestrate microservices. By leveraging the strengths of both services, it is possible to build complex workflows for automating business processe”.
Training ML models on textual features
Like any machine learning system, Capgemini’s solution requires a lot of data for its training. For document processing, ML models process relevant forms of textual data to identify patterns for statistical norms. However, legacy documents come in many different formats, many of which are not immediately suitable for digital ingestion. Having identified suitable documents then, the next vital stage is to recover text using OCR technologies and convert it to suitable formats. Tools for this process include Textract, Google Vision API, Tesseract, ImageMagick, OpenCV, Amazon Rekognition and others. Capgemini is has also recently started to use Large Language Models (such as GPT and BERT) for classification and entity extraction operations.
From here, the machine learning model depends on the goal in question. These break down into two main categories: document type classification and information extraction. For the first of these, Capgemini uses machine learning models such as random forest, xgboost or naive bayes for classifying document types, using TF-IDF (Term Frequency-Inverse Document Frequency). This statistical algorithm determines the importance of particular words in a text or collection of texts. In summary, TF-IDF is a measure of the frequency of a term, mitigated by the frequency of its broader use. By identifying the terms that are most significant to any given text, the calculation gives a useful initial assessment of a document’s purpose. Armed with this identification, more efficient and accurate information extractions can be made at the following stage.
Information extraction proceeds using a convolutional neural network (CNN). CNNs are widely used in image processing as well as NLP to detect recurring patterns in their input sources. Their fundamental mechanism is image-based: convolution here refers to the combination of multiple image layers to determine what are effectively ‘average’ shapes. This technique is thus useful for detecting regularities across a number of documents and can form a model for indications such as checkbox ticks as well as rather more complex features.
The results
In action, Capgemini’s serverless cloud machine learning systems have shown themselves to be successful in several ways.
- Easier management. For starters, orchestrated architectures like Google Workflows have proved easier to configure and administer when compared with more conventional choreographed architectures. The process needs little manual intervention or custom code writing, thus mitigating operational complexity and attendant errors.
- Reduced costs. Serverless architectures have removed the need for upfront commitment to expensive fixed hardware solutions. Smart process automation projects typically have variable input demands, needing to scale or contract according to demand. Serverless solutions mean operational costs are reduced, as only the resources that are actually used are paid for.
- Process monitoring. The implementation of process monitoring and retry mechanisms has been an invaluable means to address potential issues during implementation. Pipeline troubleshooting is simplified and automatic alerts notify developers of any potential problems, resulting in better-performing and more stable services.
Manual intervention massively reduced. The combination of Python and ML models for document classification and extraction has achieved accuracy levels of over 95%. These automation pipelines have thus removed almost entirely the need for manual intervention, improving efficiency and reducing costs.




