
In questo articolo, scoprirete come Unipol ha affrontato l’annoso tema del dual write problem nel contesto delle Architetture distribuite. Vengono presentate implementazioni di pattern come l’Outbox Table, il Saga e l’Idempotent Consumer, già rilasciate in produzione e che, già da diversi mesi, garantiscono la protezione da messaggi e dati duplicati.
Vedrete, infine, come l’implementazione dell’sdk del tool open source OpenTelemetry permetta di rendere osservabili integrazioni tra sistemi che non lo sono “out of the box”, in particolare rendendo continuità la rilevazione delle tracce.
Introduzione all’architettura ad eventi e alle integrazioni asincrone
Nel contesto dei moderni sistemi informativi, l’adozione di un’architettura ad eventi rappresenta un passaggio cruciale per abilitare l’evoluzione verso ecosistemi distribuiti, scalabili e reattivi. Le architetture monolitiche e sincrone, tipiche di molti sistemi legacy, presentano forti limitazioni in termini di scalabilità, isolamento dei domini e resilienza agli errori. L’approccio event-driven, al contrario, propone un modello di comunicazione decentrato, basato sull’emissione e l’ascolto di eventi tra servizi autonomi.
In questo paradigma, i servizi producono eventi in risposta a cambiamenti di stato interni (ad esempio, la conferma di un ordine o la creazione di una nuova anagrafica) e altri servizi possono sottoscrivere questi eventi per reagire in modo asincrono.Questo consente di disaccoppiare i componenti, migliorando la manutenzione, la scalabilità, la tolleranza ai guasti e l’evoluzione del sistema, permettendo di aggiungere nuovi consumer senza impatti sui componenti esistenti. Inoltre, gli eventi non devono necessariamente essere processati nell’immediato: vengono accodati in broker (come Kafka, RabbitMQ, Azure Service Bus), il che consente retry e buffering naturali in caso di malfunzionamenti temporanei.
L’esperienza di Unipol mostra chiaramente come l’introduzione di pattern evoluti come Outbox Table, Saga Coreografata e Idempotent Consumer abbia abilitato il passaggio a un’architettura asincrona , superando i limiti di quelle sincrone, in particolare nel contesto di eventuali fallimenti parziali.

Cos’è il Dual Write Problem
Il “dual write problem” è un difetto strutturale che emerge quando due operazioni non sono eseguite all’interno di un’unica transazione atomica. Questo significa che esiste la concreta possibilità che una delle due riesca mentre l’altra fallisca, generando incoerenze tra lo stato dell’applicazione e le informazioni condivise con altri sistemi.
Un esempio classico è il seguente: un sistema salva su database una nuova polizza cliente e successivamente pubblica un evento OrderCreated. Se per qualche ragione (timeout, crash, errore del broker) l’evento non viene pubblicato, i sistemi a valle non riceveranno l’informazione, generando uno stato globale incoerente.
Nel mondo enterprise, dove i sistemi parlano tra loro continuamente – CRM, contabilità, logistica, customer care – l’affidabilità nella propagazione dei dati è fondamentale. Il dual write è uno dei principali nemici di questa affidabilità. Nella presentazione Unipol, il problema viene affrontato in profondità, mostrando come in un sistema distribuito il rischio di duplicati e inconsistenze sia concreto e spesso sottovalutato.
A rendere tutto più critico è la difficoltà di rilevare questi errori: un’applicazione che non pubblica un evento, o che lo pubblica due volte, non segnala necessariamente un errore immediato, ma crea un debito informativo che può emergere solo giorni dopo, ad esempio con un cliente che non riceve una notifica o con un ordine elaborato due volte. La coerenza eventuale, tanto celebrata nell’architettura distribuita, deve essere supportata da meccanismi robusti che compensino queste debolezze.
Il dual write problem è quindi una trappola silenziosa, che va gestita con consapevolezza e strumenti appropriati. È proprio da qui che nasce l’esigenza dei pattern come Outbox, Saga e Idempotent Consumer, strumenti che vedremo nei prossimi capitoli e che, insieme all’osservabilità, rappresentano il cuore della strategia adottata da Unipol per costruire un’infrastruttura veramente resiliente.
Outbox Table Pattern: garantire transazioni atomiche
Per affrontare concretamente il problema del dual write, uno degli approcci più efficaci e consolidati è quello dell’Outbox Table Pattern. Questo pattern nasce dall’idea di spostare la responsabilità della comunicazione asincrona all’interno della stessa transazione che coinvolge la scrittura dei dati principali.
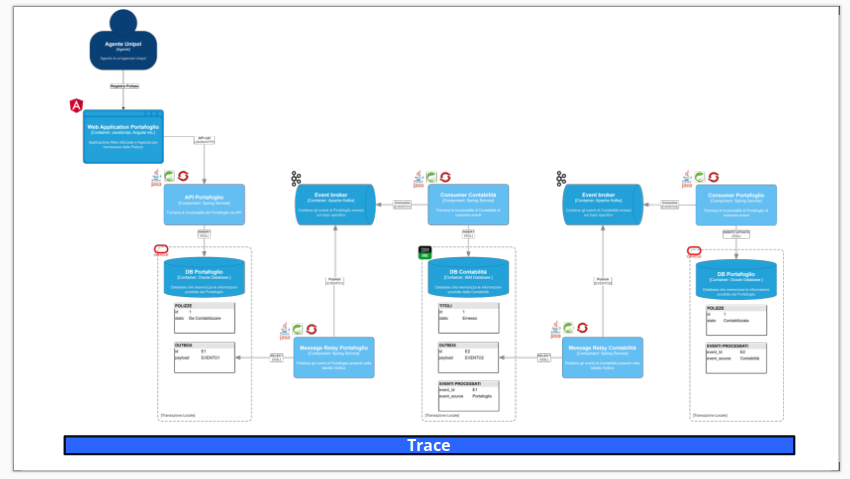
Immaginiamo un microservizio che riceve un ordine e lo salva nel proprio database. Invece di inviare direttamente un evento “ordine creato” su Kafka o su un altro message broker, il servizio scrive un messaggio all’interno di una tabella di outbox, strutturalmente simile a una coda, ma residente nello stesso database. In questo modo, sia l’ordine che l’evento vengono persistiti all’interno della stessa transazione atomica. Se qualcosa va storto, tutto viene rollbackato: ordine ed evento si annullano a vicenda, garantendo la coerenza.
Un processo separato, detto spesso message relay o publisher, si occupa di leggere periodicamente la tabella outbox e inviare i messaggi al sistema di messaggistica esterno. Una volta che il messaggio è stato correttamente inviato e ricevuto, l’entry nella tabella può essere marcata come “spedita” o rimossa.
Nel caso di Unipol, questa strategia è stata adottata per garantire la consistenza tra il dominio delle polizze e i sistemi esterni di notifica e rendicontazione. I team hanno implementato l’outbox come parte integrante del modello di dominio, sfruttando framework come MyBatis per rendere la scrittura del messaggio un’operazione quasi trasparente dal punto di vista del codice.
Una delle figure che meglio rappresenta questo pattern è una pipeline di scrittura unica con ramo secondario asincrono, e potremmo suggerire come immagine una tabella SQL con colonna “payload” affiancata a uno stream Kafka, collegati da un processore intermedio. Questa visualizzazione aiuta a comprendere che, pur essendo separata la logica di pubblicazione, la persistenza è unica e affidabile.
Outbox Table Pattern: garantire transazioni atomiche
In un mondo perfetto, ogni modifica al sistema avverrebbe in modo sincrono e atomico, garantendo che i dati siano sempre coerenti e affidabili. Tuttavia, nei sistemi distribuiti, questa garanzia è difficile da mantenere. È proprio in questo contesto che nasce l’esigenza dell’Outbox Table Pattern, una strategia capace di evitare il famigerato “dual write problem” grazie a un approccio semplice ma efficace.
La logica dietro l’Outbox
Il cuore del pattern consiste nel separare i dati da scrivere nei sistemi esterni (come un broker di messaggi) all’interno di una tabella speciale chiamata outbox, che vive nello stesso database transazionale dell’entità da aggiornare. Così facendo, si evita di scrivere direttamente su un sistema esterno (ad esempio Kafka o RabbitMQ) all’interno della stessa transazione del database principale, eliminando alla radice il rischio di inconsistenze dovute a errori parziali.
Durante una transazione, l’applicazione salva sia i dati di business sia il messaggio da inviare all’esterno all’interno della tabella outbox. Solo dopo che la transazione è stata confermata, un componente separato – il message relayer – legge i messaggi dalla tabella e li pubblica nel sistema esterno.
Un esempio concreto da Unipol
Nel caso di Unipol, questo pattern è stato adottato per sincronizzare eventi tra sistemi eterogenei, riducendo il rischio di eventi fantasma o perdite di messaggi nei processi core, ad esempio durante la generazione di contratti assicurativi o la notifica di eventi verso sistemi documentali. L’approccio ha permesso non solo di migliorare l’affidabilità, ma anche di incrementare la visibilità delle operazioni effettuate, sfruttando audit trail e strumenti di osservabilità come Dynatrace.

Saga Pattern: l’esecuzione ordinata di operazioni distribuite
Un altro tassello fondamentale nella gestione affidabile dei processi distribuiti è il Saga Pattern, utilizzato per coordinare transazioni distribuite in assenza di un vero e proprio two-phase commit. Quando un flusso di business si estende su più microservizi, è necessario garantire che ogni step venga eseguito nel giusto ordine, gestendo anche gli eventuali fallimenti intermedi.
Cos’è una ‘saga’?
Una saga è composta da una sequenza di operazioni locali, ciascuna delle quali può essere compensata da un’operazione inversa. In caso di errore, si avvia un processo di rollback parziale attraverso compensating transactions che annullano le modifiche già eseguite.
Le saga possono essere coreografate, dove i partecipanti si coordinano tramite eventi, oppure orchestrate, dove un servizio centrale controlla l’intero flusso. In contesti di alta resilienza, la coreografia è spesso preferita per evitare colli di bottiglia e single point of failure.
L’esperienza di Unipol
In scenari come la gestione di polizze multicanale o la notifica di cambiamento stato, Unipol ha adottato saghe coreografate per mantenere consistenza e tracciabilità, soprattutto in flussi critici dove l’ordine delle operazioni è fondamentale ma deve essere mantenuto in ambienti eterogenei.
Questa architettura ha dimostrato di essere particolarmente robusta in condizioni di carico elevato o in presenza di integrazioni asincrone con terze parti, dove le latenze possono variare significativamente.
Idempotent Consumer Pattern: protezione contro i messaggi duplicati
Anche con l’adozione di buone pratiche, il rischio di ricevere più volte lo stesso messaggio è sempre presente. È qui che entra in gioco il Idempotent Consumer Pattern, una strategia che permette a un sistema di elaborare lo stesso messaggio più volte senza effetti collaterali.
Perché l’idempotenza è fondamentale
In un sistema distribuito, la duplicazione dei messaggi può avvenire per molteplici motivi: retry automatici, errori di rete, o crash temporanei del consumer. Se non gestiti correttamente, questi duplicati possono portare a errori logici come la duplicazione di ordini, la sovrascrittura di dati o l’attivazione ripetuta di operazioni.
Per rendere un consumer idempotente, è comune salvare un identificatore univoco per ogni messaggio elaborato e controllare la presenza dello stesso prima di applicare qualsiasi cambiamento. In alternativa, alcune architetture optano per operazioni “safe by design”, che non hanno effetti collaterali anche se ripetute.
L’approccio di Unipol
Unipol ha adottato un sistema di deduplica per gli eventi più critici, salvando il message ID in tabelle di log e ignorando messaggi già elaborati. Questa tecnica si è dimostrata fondamentale per garantire l’integrità nei flussi di notifica e nella propagazione di eventi interni tra sistemi legacy e moderni.

Osservabilità con OpenTelemetry e Dynatrace
Quando si progettano architetture distribuite complesse, implementare i pattern corretti non basta. Per garantire affidabilità, bisogna vedere cosa succede nel sistema, anticipare i problemi, identificare colli di bottiglia e analizzare i flussi in modo trasparente. È qui che l’osservabilità gioca un ruolo chiave, permettendo di correlare eventi, transazioni e performance attraverso l’intera infrastruttura.
L’osservabilità come componente architetturale
In sistemi che adottano pattern come Outbox o Saga, il tracciamento di un singolo evento che attraversa servizi diversi può diventare complesso. Per questo, Unipol ha integrato strumenti come OpenTelemetry, un framework open-source per la raccolta di metriche, log e tracce distribuite, e Dynatrace, una piattaforma di monitoraggio avanzata con funzionalità di AIOps e tracciamento automatico delle dipendenze.
OpenTelemetry permette di standardizzare la raccolta dei dati da applicazioni e servizi, mentre Dynatrace si occupa della visualizzazione, della correlazione automatica e dell’analisi predittiva. Insieme, questi strumenti offrono una visione in tempo reale delle performance del sistema, rilevando anomalie, ritardi nei flussi delle saghe o tentativi ripetuti di elaborare eventi duplicati.
L’applicazione in Unipol
Nei flussi core come quelli di generazione documentale o di notifica eventi verso i partner, Unipol ha utilizzato tracing distribuito per mappare ogni step dell’elaborazione. Questo ha consentito di isolare rapidamente le cause di latenza, verificare se un outbox non veniva processato o se un servizio compensativo non si attivava correttamente. La sinergia tra metadati semantici raccolti da OpenTelemetry e l’intelligenza artificiale di Dynatrace ha permesso di costruire un sistema non solo osservabile, ma anche capace di autodiagnosi e interventi proattivi.
Conclusioni: lezioni apprese e prospettive future
L’esperienza di Unipol dimostra che affrontare il dual write problem è una sfida concreta, ma anche una grande opportunità per migliorare l’affidabilità dei sistemi distribuiti. Attraverso l’adozione di pattern architetturali robusti e strumenti di osservabilità, è possibile costruire piattaforme resilienti, scalabili e trasparenti.
L’Outbox Table Pattern ha permesso di isolare la logica transazionale dalla comunicazione asincrona, riducendo il rischio di inconsistenze nei messaggi inviati. Il Saga Pattern, applicato in versione coreografata, ha favorito la gestione di processi distribuiti con un grado elevato di flessibilità e recuperabilità. L’approccio idempotente ha offerto un’ulteriore barriera contro i problemi derivanti da retry o duplicazioni, rendendo i consumer più sicuri e prevedibili.
Ma è grazie all’introduzione di OpenTelemetry e Dynatrace che queste soluzioni hanno potuto esprimere tutto il loro potenziale. Solo con una visibilità profonda e continua dei sistemi è possibile garantire un funzionamento fluido e tempestivamente correggere le anomalie.

Angelo Manzione
Head of Enterprise & Cloud Solution Architecture presso Gruppo Unipol

Iacopo Talevi
Integration and Observability Architect presso Unipol Assicurazioni S.p.A.
As Integration Architect, I lead the introduction of an enterprise event streaming platform at Unipol, for which I am the Product Owner and I manage all aspects (vision, roadmap, architectural decision, development, support, etc). In addition, I design and support integration solutions that bridge modern architectures with legacy systems.
