Moonshot AI riscrive le regole dell’intelligenza artificiale con Kimi K2 Thinking: un modello open source da un trilione di parametri che sfida GPT-5 e Claude, costato meno di 5 milioni di dollari. Il 6 novembre 2025, mentre la community degli sviluppatori AI scorreva distrattamente le notifiche su Hugging Face, è apparso un rilascio che avrebbe potuto sembrare l’ennesimo modello linguistico cinese. Kimi K2 Thinking, creato dalla startup Moonshot AI supportata da Alibaba, prometteva le solite meraviglie: capacità agentiche avanzate, architettura Mixture-of-Experts, un trilione di parametri totali.
Ma quando i primi benchmark hanno iniziato a circolare, qualcosa di inaspettato è emerso dai numeri: 44,9% su Humanity’s Last Exam, battendo sia GPT-5 che Claude Sonnet 4.5. Non di poco, non per errore statistico, ma con margini che hanno costretto anche i più scettici a ricalcolare.

Per chi non mastica quotidianamente l’alfabeto degli acronimi AI, Humanity’s Last Exam è quello che accade quando gli esperti decidono di fermare la marcia trionfale dei modelli linguistici: tremila domande crowdsourced da oltre mille specialisti, progettate per essere troppo difficili anche per i sistemi più avanzati. Matematica avanzata, biologia molecolare, filosofia analitica, fisica quantistica. Il tipo di esame dove GPT-4o balbetta al 9% e anche i più recenti reasoning models faticano a superare il 30%. Kimi K2 Thinking ha superato quella soglia con una naturalezza che ricorda i film heist quando il colpo impossibile diventa routine: nessuno spettacolo, solo precisione metodica.
Ma questa non è una storia di un singolo modello eccezionale. È la cronaca di un momento in cui l’impossibile diventa la nuova normalità, e le regole economiche e geopolitiche dell’AI vengono riscritte da chi, teoricamente, doveva restare indietro.
Dentro la Macchina
Per capire cosa rende K2 Thinking diverso occorre scendere nell’architettura, dove le scelte ingegneristiche diventano dichiarazioni di intenti. Il modello è costruito su un’architettura Mixture-of-Experts con un trilione di parametri totali, ma ne attiva solo 32 miliardi per ogni token processato. È una strategia che ricorda le centrali elettriche modulari: tutta quella potenza esiste, ma viene chiamata in causa solo quando necessaria, riducendo drasticamente i costi operativi senza sacrificare le capacità.
La vera innovazione, però, è nella quantizzazione INT4 nativa. Mentre la maggior parte dei modelli viene addestrata in precisione più alta e poi compressa, K2 Thinking è stato progettato fin dall’inizio per operare in INT4, dimezzando i requisiti di memoria e raddoppiando la velocità di inferenza senza le tipiche perdite di accuratezza che affliggono la compressione post-hoc. È il tipo di scelta che privilegia l’efficienza operativa alla vanity metric dei parametri totali, una filosofia che diventerà centrale quando parliamo di costi.
L’architettura MoE di K2 distribuisce il carico su 384 esperti specializzati, contro i 256 di DeepSeek V3, permettendo una granularità maggiore nella selezione delle competenze. Ogni richiesta attiva un sottoinsieme dinamico di questi esperti, e il sistema sceglie autonomamente quali neuroni chiamare in causa in base al tipo di problema. In pratica, quando K2 deve scrivere codice Python attiva un set di esperti diverso rispetto a quando deve risolvere equazioni differenziali o tradurre sanscrito.
Ma l’elemento che distingue K2 Thinking dai suoi predecessori è il test-time scaling, una tecnica che permette al modello di “pensare più a lungo” su problemi complessi. Non è semplice trial-and-error: il sistema può allocare più cicli computazionali alle domande difficili, esplorando catene di ragionamento alternative prima di convergere su una risposta. È quello che i ricercatori chiamano “thinking mode”, ed è la ragione per cui K2 può affrontare problemi multi-step che richiederebbero normalmente supervisione umana.
Sul fronte dell’agenticità, K2 dimostra capacità che fino a qualche mese fa erano prerogativa di sistemi chiusi e costosi: può eseguire 200-300 chiamate sequenziali di tool senza intervento umano, navigando API esterne, processando dati strutturati e orchestrando workflow complessi. La finestra di contesto da 256k token permette di mantenere coerenza su conversazioni estese o documenti tecnici corposi, mentre il sistema di memoria cache riduce la latenza nelle interazioni ripetute.
Immagine tratta dal paper ufficiale su arxiv.org
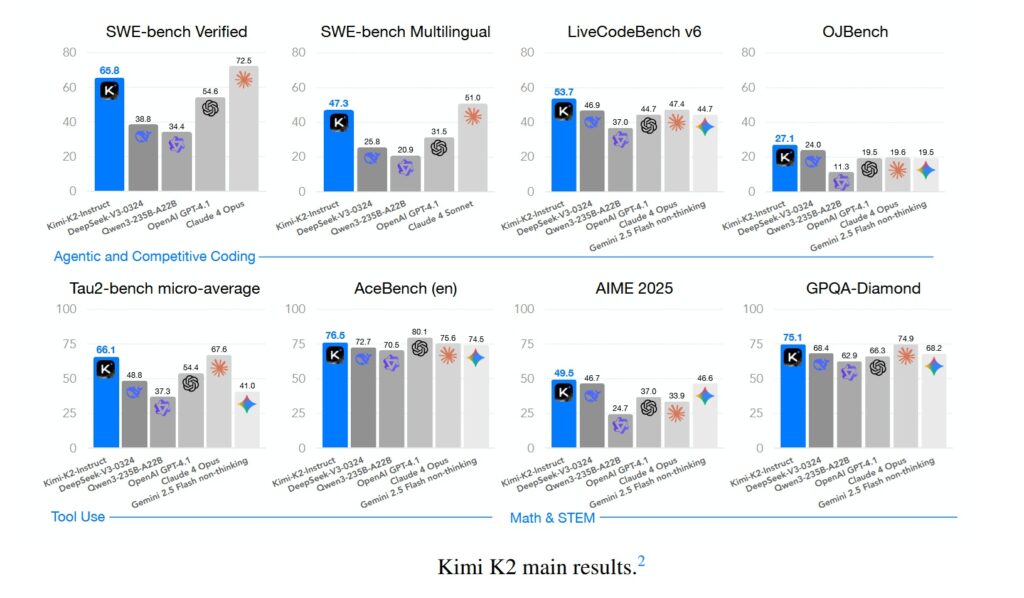
Immagine tratta dal paper ufficiale su arxiv.org
I Numeri Parlano
I benchmark sono il campo di battaglia dove le promesse vengono misurate contro la realtà. Su Humanity’s Last Exam, K2 Thinking raggiunge 44,9%, superando GPT-5 (42,1%) e Claude Sonnet 4.5 (41,7%). Ma il vero discrimine emerge quando si guarda ai task agentici: su BrowseComp, che misura la capacità di navigare web e API autonomamente, K2 ottiene 34,2% contro il 28,5% di GPT-5. Su SWE-Bench Verified, il benchmark per software engineering che richiede di risolvere bug reali in codebase open source, K2 raggiunge 65,8%, superando praticamente ogni modello non-thinking disponibile.
Non tutto brilla allo stesso modo. Su GPQA Diamond, il dataset di domande scientifiche graduate-level, K2 si ferma a 75,1%, un risultato eccellente ma non record-breaking. E quando GPT-5 viene eseguito in “heavy mode” con reasoning esteso, riesce ancora a superare K2 su alcuni task specifici di matematica pura. Ma quello che conta, nella narrativa più ampia, è che queste differenze sono marginali, e scompaiono completamente quando si considera il rapporto costo-prestazioni.
Perché qui emerge il dato che ha fatto tremare Silicon Valley: K2 Thinking costa $0,33 per milione di token in input e $1,33 in output. GPT-5 standard si attesta a $1,25/$10, mentre GPT-5 in modalità reasoning può arrivare a $50 per milione di token output. Non stiamo parlando di differenze del 20-30%, ma di un ordine di grandezza. Per un’azienda che processa decine di milioni di token al giorno, la matematica diventa brutalmente semplice.
E c’è un dettaglio tecnico che vale la pena sottolineare: tutti questi benchmark di K2 sono stati eseguiti in INT4, senza trucchi di precisione gonfiata per guadagnare punti percentuali. Alcuni laboratori rilasciano numeri impressionanti in FP16 e poi, quando il modello viene effettivamente deployato in produzione quantizzato, le prestazioni crollano. K2 è stato testato nelle stesse condizioni in cui verrebbe usato in produzione, una trasparenza che dovrebbe essere standard ma che raramente lo è.
Su LiveCodeBench v6, che testa la capacità di scrivere codice per problemi nuovi mai visti durante il training, K2 raggiunge 53,7%. Su AIME 2025, l’esame di matematica avanzata per studenti americani, ottiene 49,5%. Su OJBench, un benchmark cinese per competitive programming, arriva a 27,1%. Numeri che individualmente potrebbero sembrare tecnicismi, ma che aggregati disegnano il profilo di un sistema che ha superato la soglia della utilità pratica su una gamma molto ampia di applicazioni reali.
Immagine tratta dal paper ufficiale su arxiv.org
La Voce Critica
Nathan Lambert non è il tipo che si lascia impressionare facilmente. Ricercatore AI all’Allen Institute for AI e autore della newsletter Interconnects, Lambert ha dedicato anni ad analizzare il gap tra hype e realtà nel settore. Quando ha scritto della sua analisi su K2 Thinking, ha posto una domanda che taglia come un bisturi: “What does it mean when a DeepSeek moment becomes routine?”
Quando DeepSeek V3 è stato rilasciato a fine 2024 con un costo di training di 5,6 milioni di dollari, l’industria ha avuto un sussulto collettivo. Era l’anomalia che confermava la regola: sì, è possibile costruire modelli competitivi con budget ridicoli, ma resta un’eccezione. Ora, dieci mesi dopo, abbiamo Moonshot con K2, Qwen che macina rilasci, e una dozzina di altri laboratori cinesi che pubblicano modelli open source ogni due settimane. I server di Kimi sono già saturi, segno che non stiamo parlando di tech demo ma di sistemi che gli sviluppatori deployano effettivamente in produzione.
Lambert individua cinque dinamiche critiche, e la prima è la più semplice ma devastante: i laboratori cinesi rilasciano più velocemente. Molto più velocemente. Mentre Anthropic può impiegare mesi per portare un modello dal lab alla produzione, e OpenAI si posiziona da qualche parte nel mezzo, i laboratori cinesi spremono quel ciclo in settimane. Quando il ritmo del progresso è alto, essere più rapidi ti fa sembrare migliore. Lambert stima il gap di performance grezza tra closed e open a circa quattro-sei mesi, ma poi pone la domanda retorica: se questi modelli closed non sono pubblicamente disponibili, contano davvero?
Il secondo punto tocca qualcosa di più sfumato: i laboratori cinesi stanno dominando sui benchmark chiave, ma esistono “long-tail behaviors” per cui non hanno feedback loops. Lambert nota che Qwen, nell’ultimo anno, è passato da essere conosciuto per “benchmaxing” (ottimizzare ossessivamente i benchmark) a produrre modelli genuinamente fantastici che, casualmente, hanno anche punteggi insani. DeepSeek e Kimi hanno quello che Lambert chiama “good taste”, una qualità difficile da quantificare ma immediata da percepire quando usi i modelli. Ma rimangono comportamenti utente comuni, specialmente quelli occidentali, su cui le aziende americane hanno anni di dati interni e i laboratori cinesi no. Questi intangibili contano per la retention degli utenti, anche se non appaiono su Humanity’s Last Exam.
È qui che Lambert riconosce un dettaglio tecnico spesso trascurato: K2 Thinking è stato addestrato nativamente in INT4 durante il post-training, probabilmente per rendere lo scaling del reinforcement learning più efficiente su sequenze lunghe. E tutti i benchmark riportati sono in INT4, non in precisione gonfiata. È il modo onesto di fare confronti, nota Lambert, perché è così che il modello verrà effettivamente servito.
Il terzo punto è geopolitico e inesorabile: all’inizio del 2025, la maggior parte delle persone che seguivano l’AI conosceva zero laboratori cinesi. Ora, verso la fine dell’anno, DeepSeek, Qwen e Kimi stanno diventando nomi comuni. Hanno tutti stagioni di rilasci migliori e punti di forza diversi. E la lista continuerà a crescere: Lambert cita Z.ai, Meituan, Ant Ling come possibili aggiunte per il 2026. Alcuni di questi laboratori hanno iniziato i loro sforzi sui foundation models dopo DeepSeek, e in sei mesi hanno raggiunto il ballpark della frontier open. La domanda ora è se possano offrire qualcosa in una nicchia della frontier che abbia domanda reale da parte degli utenti.
Il quarto aspetto riguarda le capacità agentiche interleaved: K2 Thinking può eseguire centinaia di chiamate sequential di tool, una caratteristica che è diventata standard nei modelli closed come o3 e Grok 4. Tecnicamente non è rivoluzionario, emerge naturalmente durante il training RL specialmente quando il modello deve cercare informazioni per rispondere correttamente. Ma è la prima volta che questa capacità appare in un modello open con questa robustezza, e i provider che hostano open weights dovranno lavorare duramente per supportarla precisamente. Lambert spera che esista domanda utente sufficiente per far maturare l’industria nel serving di tool-use models open.
Il quinto punto è il più preoccupante per i laboratori americani: la pressione è reale. C’è pressione sui prezzi e aspettative che devono gestire. La differenziazione e la narrazione su perché i loro servizi closed siano migliori deve evolversi rapidamente, allontanandosi dai benchmark che ora anche l’open source domina. Lambert aveva anticipato questo nel suo post estivo “Some Thoughts on What Comes Next”, suggerendo che i rilasci futuri assomiglieranno sempre più a quello di Claude 4, dove i guadagni sui benchmark sono marginali ma quelli nel mondo reale sono sostanziali. Questa transizione richiederà molta più nuance per capire se il ritmo del progresso stia continuando, specialmente quando i critici dell’AI sfrutteranno il plateau delle evaluations per sostenere che l’AI non funziona più.
La domanda finale di Lambert è ingannevolmente semplice: i canali di distribuzione esistenti, i prodotti e la capacità di serving sono sufficienti per mantenere stabile il valore di tutte le principali compagnie AI statunitensi? Lambert pensa che siano al sicuro, ma i modelli e le compagnie cinesi stanno prendendo fette più grandi della torta AI in crescita. Non sarà una maggioranza in termini di revenue, ma può essere una maggioranza in mindshare, specialmente nei mercati internazionali.
Quello che Lambert non dice esplicitamente, ma che emerge tra le righe, è che stiamo assistendo non a una competizione ma a una biforcazione. Due ecosistemi paralleli che si rafforzano reciprocamente all’interno, ma che comunicano sempre meno tra loro. E quando la domanda passa da “chi è più avanti” a “chi conta per quale mercato”, le risposte diventano inquietantemente geopolitiche.
Geopolitica degli Algoritmi
Per capire il contesto più ampio di K2 Thinking occorre guardare oltre Moonshot. La Cina ha sei grandi laboratori AI che i media specializzati hanno iniziato a chiamare informalmente “AI Tigers”: DeepSeek, Moonshot, Alibaba (con Qwen), Baidu (con Ernie), ByteDance (con VolcEngine), e Tencent (con Hunyuan). Ognuno rilascia modelli maggiori ogni due-tre mesi, creando una cadenza che tiene l’industria globale in costante tensione.
I controlli sulle esportazioni americane di chip avanzati, pensati per rallentare lo sviluppo AI cinese, hanno avuto un effetto paradossale. DeepSeek V3 è stato addestrato su Nvidia H800, una versione depotenziata dell’H100 che gli USA hanno bannato per la Cina nel 2022. Il ban successivo ha colpito anche gli H800 nel 2023, ma ormai la strada era tracciata: i laboratori cinesi hanno imparato a estrarre prestazioni frontier da hardware subottimale attraverso ottimizzazioni software aggressive.
Il costo di training è il dato che continua a dominare la narrativa. K2 Thinking ha richiesto meno di 5 milioni di dollari, secondo le stime ufficiali. DeepSeek V3 era costato 5,6 milioni. Per confronto, GPT-4 aveva richiesto oltre 100 milioni di dollari nel 2023, e i rumor su GPT-5 parlano di budget nell’ordine dei miliardi. Emad Mostaque, ex CEO di Stability AI, ha twittato che con i chip Nvidia Blackwell di nuova generazione basterebbero 3 milioni di dollari per addestrare un modello competitivo con i frontier models attuali.
Questi numeri hanno implicazioni dirette sul mercato. Aziende come Airbnb hanno già pubblicamente dichiarato di usare Qwen per alcune applicazioni interne, privilegiando il rapporto costo-prestazioni rispetto al brand recognition. E mentre OpenAI e Anthropic difendono i loro pricing sostenendo che i costi operativi rimangono alti, la realtà è che il mercato sta scoprendo che “abbastanza buono e dieci volte più economico” batte “perfetto ma proibitivo” nella maggior parte dei casi d’uso reali.
La licenza Modified MIT sotto cui K2 Thinking viene rilasciato merita una nota. È tecnicamente open source, permette uso commerciale e modifiche, ma include clausole che limitano l’uso del nome “Moonshot” e “Kimi” in prodotti derivati. È un compromesso tra apertura genuina e protezione del brand, una strategia che i laboratori cinesi stanno perfezionando per massimizzare l’adozione senza rinunciare al controllo narrativo.
Chi vince e chi perde in questo scenario? Gli sviluppatori vincono, acquisendo accesso a tecnologie che fino a ieri costavano decine di migliaia di dollari al mese in API calls. Le startup vincono, potendo competere con incumbents che basavano il loro moat sull’accesso privilegiato a modelli proprietari. I laboratori open source occidentali perdono rilevanza, schiacciati tra la velocità cinese e la qualità (presunta) dei closed models americani. E gli stessi colossi americani si trovano in una posizione delicata: continuare con la strategia closed rischia di renderli irrilevanti nel lungo termine, ma aprire completamente significherebbe cannibalizzare i flussi di revenue che finanziano la R&D.
Il vero perdente, forse, è l’idea stessa di un ecosistema AI globale unificato. Stiamo assistendo alla cristallizzazione di sfere di influenza tecnologica parallele, ognuna con i propri standard, dataset, bias e valori. E quando Lambert chiede se questo sia democratizzazione o frammentazione, la risposta onesta è: probabilmente entrambe, simultaneamente.
Futuro Prossimo
K2 Thinking non è un tech demo rilasciato per fare rumore e poi dimenticato. I server di Moonshot sono attualmente saturi, con tempi di attesa che nei picchi superano i dieci minuti per ottenere una risposta. È il tipo di problema che le startup sognano di avere: troppa domanda, non abbastanza capacità. Ma segnala qualcosa di più profondo: gli sviluppatori stanno effettivamente deployando questi modelli in produzione, non solo testandoli per curiosità.
L’impatto più immediato è sulla dinamica cliente-fornitore nell’AI. Per anni, il rapporto di potere era sbilanciato: se volevi capacità frontier, dovevi accettare i termini di OpenAI o Anthropic, inclusi pricing, rate limits, policy sui dati. Con K2 e i suoi simili, il calcolo cambia. Un’azienda può scaricare i pesi, deployare on-premise o su cloud di propria scelta, e avere controllo completo su latenza, privacy e costi operativi. Non è perfetto per tutti i casi d’uso, ma per una fetta significativa del mercato è più che sufficiente.
Le domande aperte rimangono numerose. La multimodalità nativa, ad esempio: K2 Thinking è ancora primariamente text-based, mentre GPT-4 e Claude possono processare immagini, audio, video in modo integrato. I reasoning traces, quelle catene di pensiero esplicite che modelli come o1 e R1 mostrano, in K2 sono meno trasparenti, rendendo più difficile il debugging quando il modello sbaglia. E la questione della sostenibilità long-term: può Moonshot, con una frazione delle risorse di OpenAI, mantenere questo ritmo di innovazione?
Ma forse la domanda più interessante è quella che Lambert lascia implicitamente aperta: cosa succede quando l’impossibile diventa routine? Quando K2 Thinking è stato rilasciato, molti hanno reagito con entusiasmo. Il prossimo modello cinese che batterà i benchmark avrà meno copertura mediatica. Il successivo ancora meno. Non perché siano meno impressionanti tecnicamente, ma perché la curva dell’aspettativa si sarà spostata.
Siamo a quel punto del film heist dove i protagonisti hanno perfezionato il colpo al punto che sembra quasi noioso. Entrare nel caveau, bypassare i sistemi, uscire puliti. Nessun dramma, solo esecuzione. È il momento più pericoloso, quello dove l’overconfidence porta agli errori. E nel contesto dell’AI, gli errori non significano fallire un benchmark, ma distribuire sistemi che prenderanno decisioni critiche senza che abbiamo completamente compreso come o perché.
K2 Thinking è un risultato tecnico notevole. Ma la sua vera importanza potrebbe essere quella di marcare il momento in cui abbiamo smesso di essere stupiti, e abbiamo iniziato ad assumere che questo livello di capacità sia il nuovo baseline. E quando l’eccezionale diventa ordinario, è lì che iniziano i veri problemi interessanti.