
Scopriamo in che modo possiamo creare un’autentica chat con un assistente virtuale basata su un modello AI simile a ChatGPT senza dover dialogare con un server ma interamente all’interno del browser!
È veramente possibile farlo a costo zero interamente client-side con Javascript? Arriveremo veramente a qualcosa di “simile a ChatGPT”? Ci aspetta un futuro con assistenti virtuali offline e con un totale controllo della privacy?
Rispondiamo a queste domande con il secondo tutorial dedicato a Transformers.js dedicato alla realizzazione di un chatbot basato su un vero modello LLM preso da Huggingface.
Ricetta pratica per Chatbot basato su Intelligenza Artificiale integrato in pagina web
Requisiti
Anche questa ricetta come per la precedente è pensata per essere chiara ed accessibile!
Ad esempio, non useremo nessun bundler ma una semplice cartella /public da servire con il vostro web server preferito.
Ingredienti
Per la nostra webapp avremo bisogno di tre ingredienti principali corrispondenti ai quattro file di progetto su cui lavoreremo:
./public/
index.html
worker.js
app.js
style.css
Code language: PHP (php)UI minimalista per chat:
All’interno del nostro index.html avremo
#chat-messagesdove appariranno (con stili diversi) i messaggi dell’utente, dell’assistente virtuale e del sistema#chat-input-containerper mandare un messaggio da tastiera e con un bottone
Un web worker (caricato come modulo): conterrà il nostro modello di IA e ci permetterà di interrogarlo senza bloccare l’interfaccia utente del main thread.
La logica applicativa di una classica chat: l’utente potrà inviare i propri messaggi e altrettanto farà il modello AI.
Preparazione
Una semplice Chat
Per questo esperimento ci limiteremo ad un container per ospitare l’intera chat con al suo interno un #chat-header, #chat-messages e #chat-input-container.
Aggiungiamo quindi al nostro index.html tutto l’occorrente:
<div id="container">
<div id="chat-container">
<div id="chat-header">
<h2>My first LLM</h2>
</div>
<div id="chat-messages" class="chat-messages">
<!-- qui appariranno i messaggi -->
</div>
<div id="chat-input-container">
<input type="text" id="chat-input" placeholder="Type your message...">
<button id="send-button" disabled>Send</button>
</div>
</div>
</div>
Code language: HTML, XML (xml)Invio e ricezione messaggi
Ora aggiungiamo nella nostra app.js il sistema per inviare i messaggi scritti dall’utente nella sua casella. Ci agganceremo al loro invio per mandare il messaggio alla nostra IA… ma prima creiamo un semplice sistema di invio e ricezioni messaggi.
document.addEventListener("DOMContentLoaded", () => {
const sendButton = document.getElementById("send-button");
const chatInput = document.getElementById("chat-input");
const chatMessages = document.getElementById("chat-messages");
const disableUI = () => {
sendButton.setAttribute("disabled", true);
sendButton.innerText = "...";
};
const enableUI = () => {
sendButton.removeAttribute("disabled");
sendButton.innerText = "Send";
};
const chat = (text) => {
setTimeout(() => {
addMessage("Hello world", "assistant");
}, 1000);
};
const download = (modelURL) => {
disableUI();
setTimeout(() => {
addMessage(
'<small id="downloading-message">Downloading model...</small>',
"system"
);
}, 1000);
setTimeout(() => {
addMessage(
`<small>Model ready! More information here <a href="https://huggingface.co/${modelURL}" target="_blank">${modelURL}</a></small>`,
"system"
);
enableUI();
}, 2000);
};
const addMessage = (message, role) => {
const newMessageElement = document.createElement("div");
newMessageElement.classList.add("chat-message");
newMessageElement.classList.add(role);
newMessageElement.innerHTML = message;
chatMessages.appendChild(newMessageElement);
chatMessages.scrollTop = chatMessages.scrollHeight;
return newMessageElement;
};
const sendMessage = () => {
disableUI();
const question = chatInput.value;
addMessage(question, "user");
chat(question);
chatInput.value = "";
};
sendButton.addEventListener("click", sendMessage);
chatInput.addEventListener("keypress", (event) => {
if (event.key === "Enter") {
sendMessage();
}
});
download("HF_USER/HF_MODEL");
});
Code language: JavaScript (javascript)Con un pizzico di CSS prenderà un aspetto ed il comportamento di una classica chat!
body {
margin: 0;
font-family: system-ui;
}
a, a:visited, a:focus {
color: #ff5c00;
}
#container {
display: flex;
width: 100lvw;
height: 100lvh;
justify-content: center;
align-items: center;
background-color: #333;
}
#chat-container {
display: flex;
width: 60vw;
flex-direction: column;
max-width: 80%;
max-height: 80%;
background-color: white;
padding: 1rem;
border: 3px solid #666;
}
#chat-header {
display: flex;
justify-content: space-between;
}
#chat-header button {
color: #ff5c00;
background-color: transparent;
border: 0;
font-size: 3rem;
padding: 0;
margin: 0;
}
#chat-messages {
height: 50vh;
overflow-y: auto;
display: flex;
flex-direction: column;
}
#chat-input-container {
display: flex;
}
#chat-input {
width: 100%;
}
input[type=text], button {
font-size: 1rem;
border: 1px solid #ff5c00;
padding: 1rem;
margin: 1rem;
}
button {
background-color: #ff5c00;
color: white;
cursor: pointer;
}
button:disabled {
background-color: white;
cursor: wait;
color: #ff5c00;
border: 1px dashed #ff5c00;
}
input[type=text]:disabled {
background-color: white;
cursor: wait;
color: #ff5c00;
border: 1px dashed #ff5c00;
}
Code language: CSS (css)Avrai notato che i messaggi creati nella chat sono caratterizzati da un “ruolo”: questo ci permette di distinguere i messaggi di utente, assistente virtuale e sistema.
div.chat-message {
padding: 1rem;
margin-bottom: 1rem;
white-space: break-spaces;
width: 80%;
}
div.chat-message.user {
background-color: antiquewhite;
align-self: flex-end;
}
div.chat-message.assistant {
background-color: rgb(249, 205, 147);
align-self: flex-start;
}
div.chat-message.system {
margin: 0;
color: #666;
font-family: monospace;
padding: 0.5rem;
}
Code language: CSS (css)La parte esteriore è pronta! Non pregusti già il risultato? 🤤
Siamo pronti al vero e proprio sistema di comunicazione con il nostro modello IA!
Eseguire un modello IA all’interno di un web worker 🌶️ 🌶️ 🌶️
Siamo giunti alla parte più spicy della ricetta: la creazione di un web worker per scaricare ed eseguire il modello LLM nel browser senza bloccare il thread principale.
Non conosci i Web Worker? È un’ottima occasione per provarli!
Nel file app.js includeremo il file worker.js come modulo:
var aiWorker = new Worker('worker.js', {
type: "module"
});
Code language: JavaScript (javascript)Implementiamo le due funzioni che ci permetteranno di mandare messaggi al web worker utilizzando il metodo postMessage() andando a sostituire quelle finte:
// Per mandare messaggi alla IA
const chat = (message) => {
aiWorker.postMessage({
action: "chat",
content: message,
});
};
// Per caricare il modello IA: succede solo la prima volta
const download = (modelURL) => {
addMessage(
'<small id="downloading-message">Downloading model...</small>',
"system"
);
aiWorker.postMessage({
action: 'download',
modelURL: modelURL,
});
};
Code language: JavaScript (javascript)Per ascoltare le risposte del Web Worker dobbiamo semplicemente aggiungere un event listener che ci informerà di ogni messaggio. Attenzione l’evento è sempre message ma il contenuto che viene passato alla callback conterrà un oggetto che sarai tu a definire: in pratica puoi inventare un tuo protocollo fatto di parametri e flag!
Per questa ricetta a noi serve solo ricevere due tipi di messaggio:
- se la risposta contiene la proprietà
statusallora è il segnale che il modello è pronto (cioè la risposta al messaggio conaction: 'download'inviato da noi una volta caricatoapp.js) - altrimenti è il testo generato dal modello e contenuto nella proprietà
result
Vediamo il nostro sistema di ricezioni messaggi completo delle corrispondenti reazioni della nostra UI:
aiWorker.addEventListener("message", (event) => {
const aiResponse = event.data;
if (aiResponse.status == "ready") {
addMessage(
`<small>Model ready! More information here <a href="https://huggingface.co/${aiResponse.modelURL}" target="_blank">${aiResponse.modelURL}</a></small>`,
"system"
);
} else {
const result = aiResponse.result;
addMessage(result, 'assistant');
enableUI();
}
});
// tutto parte da questa richiesta!
download('Felladrin/onnx-Pythia-31M-Chat-v1');
Code language: JavaScript (javascript)Eh sì, hai letto bene: abbiamo un parametro modelURL! Pochi passaggi e scopriremo a cosa serve ma puoi immaginarlo 🤓
Web Worker farcito di un vero Chatbot
È tutto pronto per dare un’intelligenza al nostro assistente virtuale basato su modelli di text-generation (LLM) caricati interamente nel browser grazie a Transfomers.js!!!
Per prima cosa carichiamo l’ultima versione di Transfomers.js direttamente da un servizio CDN. Attenzione! 🔥 Non scottarti: possiamo caricare questa o altre librerie in questo modo esclusivamente perché abbiamo caricato il Web Worker con l’ozione type: "module" 🙂↕️
import {
pipeline,
env,
} from "https://cdn.jsdelivr.net/npm/@xenova/transformers@2.17.1";
env.allowLocalModels = false; //useremo modelli in remoto!
Code language: JavaScript (javascript)Ora non ci resta che implementare la nostra pipeline come negli esempi della documentazione ufficiale ma all’interno del web worker e quando lo chiede la app!
La funzione downloadModel scaricherà i file del modello da Huggingface e creerà finalmente il nostro generator che è una text-generation pipeline
Sicuramente avrai notato async e await! Quando scarichiamo il modello il Web Worker aspetterà il completamento del download e poi avviserà la nostra app che tutto è pronto con self.postMessage() con la proprietà status: "ready" (che è proprio quello che sta aspettando la nostra logica applicativa per attivare la UI e quindi poter usare la chat)
var generator;
const downloadModel = async (modelURL) => {
generator = await pipeline("text-generation", modelURL);
self.postMessage({
status: "ready",
task: "text-generation",
modelURL: modelURL,
});
};
Code language: JavaScript (javascript)Qui è dove avviene la magia dei modelli text-generation e la loro capacità di sembrare “intelligenti”: che emozione!
const generateResponse = async (content) => {
// i modelli di text-generation per chatbot prendono come input una chat
const messages = [
{
role: "system",
content: "You are a highly knowledgeable and friendly assistant.",
},
{
role: "user",
content: content,
},
];
// I messaggi della chat con i loro ruoli vengono dati in pasto ad uno
// speciale tokenizer specifico di quel modello che lo trasformerà in vettori (embedding)
const textInput = generator.tokenizer.apply_chat_template(messages, {
tokenize: false,
add_generation_prompt: true,
});
// la pipeline in azione! È qui che possiamo passare tanti parametri per cambiare il risultato della generazione del testo
const output = await generator(textInput, {
max_new_tokens: 64,
do_sample: true,
});
// la conversazione ci viene restituita in un formato specifico del modello
// ma approfondendo la scheda su Huggingface troveremo tutte le informazioni
// e potremo estrarre il contenuto dell'ultima risposta.
// Al momento non c'è ancora consenso su come deve essere un chat template ma per estrarre l'ultima frase (quindi la risposta della IA) basta tagliare quello che segue all'ultima occorrenza della stringa `"assistant\n"` ad esempio in questo modo
const conversation = output[0].generated_text;
const start = conversation.lastIndexOf("assistant\n");
const lastMessage = conversation
.substr(start)
.replace("assistant\n", "");
// tutto pronto per mandare la risposta generata dalla IA
self.postMessage({
result: lastMessage,
});
};
Code language: JavaScript (javascript)Non ci resta che ammalgamare il Web Worker con richieste della nostra app.js.
Avevamo preparato tutto in precedenza per mandare due messaggi action: 'download' e action: 'chat' e qui non facciamo altro che riceverli e reagire di conseguenza!
self.addEventListener("message", (event) => {
const userRequest = event.data;
if (userRequest.action == "download") {
const modelURL = userRequest.modelURL;
downloadModel(modelURL);
} else if (userRequest.action == "chat") {
const content = userRequest.content;
generateResponse(content);
}
});
Code language: PHP (php)Risultato finale
La prima conversazione con il nostro chatbot sarà, a dir poco, allucinante 🤨 🦄🛸🦄
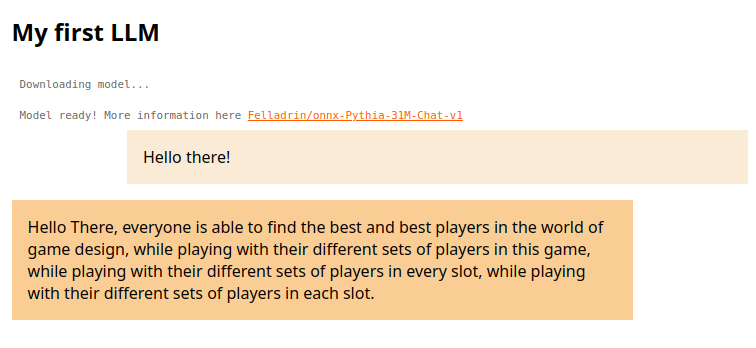
Ma prima di guardare il bicchiere mezzo vuoto farmati a riflettere: hai un modo per dialogare con un modello di intelligenza artificiale!!!
Sì, il nostro chatbot sembra un po’ tonto in questa sua prima incarnazione! 😹
Ma vediamo cosa sta succedendo prima di puntare il dito! 🫶 🤖
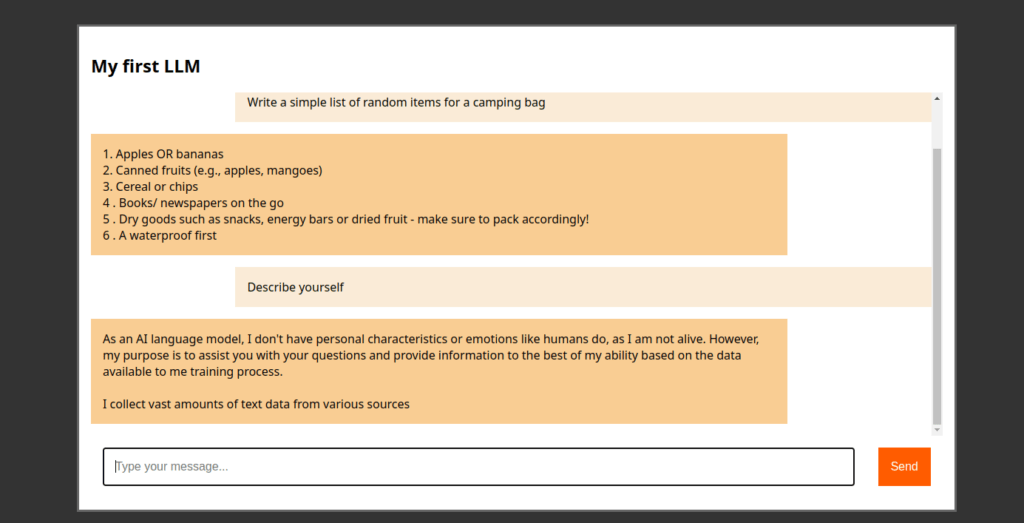
Differenti modelli capiscono meglio quello che diciamo
Il modello che abbiamo caricato in questo tutorial è piccolissimo, poche decine di megabyte: questo è stato utile per poter completare la nostra app ma evidentemente non è in grado di servire a molto.
Potremmo intervenire su alcuni parametri nella generazione. Ad esempio potremmo fornire una penalità alla ripetizione o chiedere di generare frasi più lunghe:
const output = await generator(textInput, {
max_new_tokens: 1024, // valori alti possono rallentare la risposta
repetition_penalty: 1.2, // penalizziamo la ripetizione delle stesse parole
do_sample: true,
});
Code language: JavaScript (javascript)La vera soluzione è utilizzare modelli più grandi come ad esempio:
Il secondo pesa la bellezza di 480Mb ma… finalmente iniziamo a vedere il potenziale di questa tecnologia!
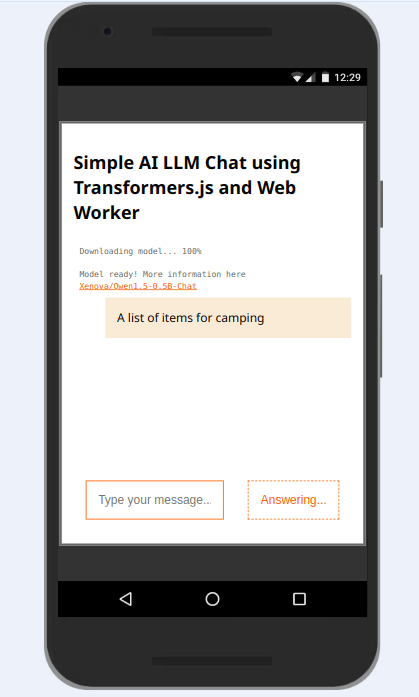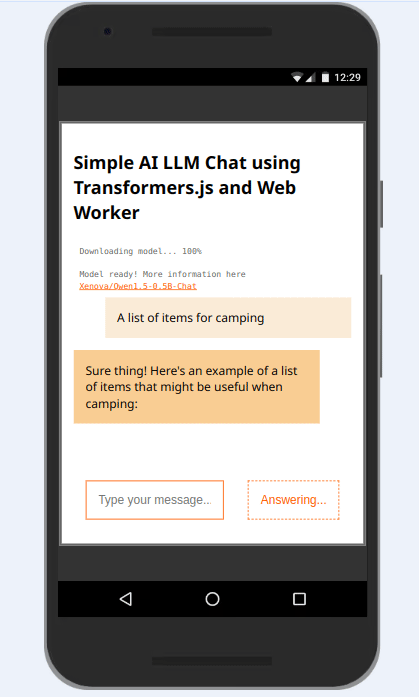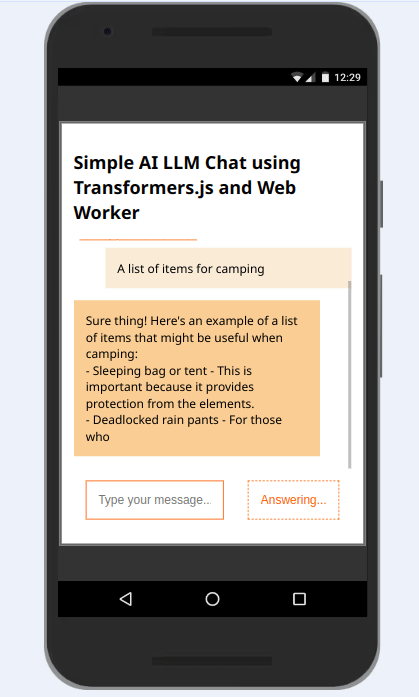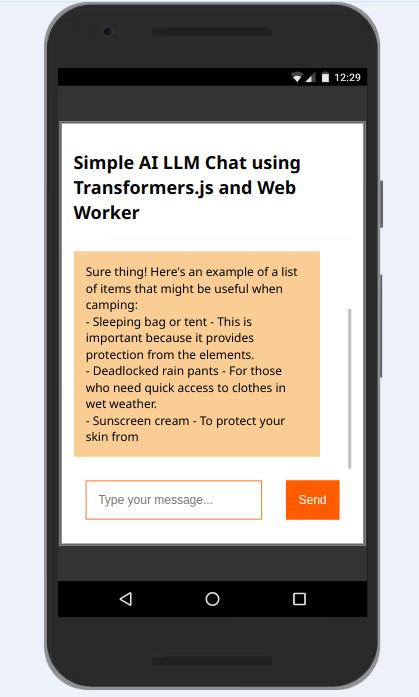
Prossimi esperimenti suggeriti
In questo tutorial hai potuto assaggiare la creazione di un chatbot basato su LLM: abbiamo approfondito l’uso di Web Worker API, osservato la differenza tra alcuni modelli con 31M, 248M e 0.5B parametri e siamo arrivati ad un assistente virtuale che inizia a dismostrare un pochino di intelligenza.
Ora puoi continuare la tua esplorazione! Ad esempio potresti provare una delle seguenti sfide:
- Rileggi il primo tutorial di questa serie su Transformers.js e scopri come implementare una User Experience molto più fluida… dove i messaggi si scrivono parola per parola
- Hai imparato a fare una chat che dialoga con un modello IA usando un Web Worker… perché non provare a creare un endpoint in Python ed implementare una tua API per dialogare con modelli a 7-8B invece di 0.5B?
- Qualcuno ha detto “Tutorial su come implementare un NPC con questa ricetta”?
- Continua l’esplorazione di altri task automatizzabili con modelli di Computer Vision o Speech Recognition sempre con Transformers.js: basta cercare su Huggingface i modelli dell’autore della libreria per avere un’ampia gamma di modelli da provare!
Ti è piaciuto questo tutorial-ricetta?
A noi piace molto creare questi contenuti e siamo sempre a caccia di argomenti e sfide nuove.
Quindi perché non fai un salto nella nostra community Telegram e proponi un argomento?
