
Spicca il volo verso il futuro dell’Intelligenza Artificiale! Preparati a capire da zero come le reti neurali artificiali (RNA) siano il cuore dell’intelligenza artificiale moderna e come queste strutture ispirate al cervello umano stiano rivoluzionando il mondo, permettendo alle macchine di apprendere pattern complessi a partire dai dati. Dal riconoscimento di immagini ai modelli di linguaggio come Transformers, tutto fa parte di questo concetto rivoluzionario.
Che cos’è una rete neurale artificiale e come funziona?

Immagina il cervello umano con i suoi miliardi di neuroni interconnessi, che lavorano in parallelo per elaborare informazioni, apprendere e prendere decisioni. Una Rete Neurale Artificiale (RNA) è un modello computazionale che imita questa architettura biologica.
Non è un cervello, ma un algoritmo di Machine Learning (Apprendimento Automatico) che impara a eseguire compiti (come riconoscere immagini o tradurre lingue) analizzando grandi quantità di dati e trovando pattern da sé, senza la necessità di essere programmato esplicitamente per ogni regola.
- Una rete neurale è un modello matematico composto da strati di nodi (neuroni artificiali).
- Ogni neurone riceve input, li moltiplica per dei pesi, somma un bias (polarizzazione) e applica una funzione di attivazione.
- L’obiettivo: approssimare funzioni che trasformino input in output utili.
Formula base di un neurone
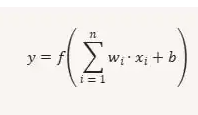
Componenti chiave di una rete neurale artificiale
Una RNA è costruita con tre elementi fondamentali:
- Neuroni (o nodi): Sono le unità di elaborazione di base, organizzate in strati. Ogni neurone riceve input, esegue un semplice calcolo e produce un output.
- Connessioni e pesi: Ogni connessione tra neuroni ha un valore numerico chiamato peso. Questo peso determina la forza o l’importanza dell’input. Un neurone somma i suoi input moltiplicati per i rispettivi pesi, e a tale somma aggiunge un valore costante chiamato bias (polarizzazione).
- Funzione di attivazione: Il risultato della somma ponderata passa attraverso una funzione matematica che decide se il neurone debba “attivarsi” (trasmettere un segnale allo strato successivo) e con quale intensità. Ciò introduce la non linearità essenziale per apprendere pattern complessi.
La struttura a strati e il flusso di informazioni
Una rete neurale tipica è organizzata in almeno tre strati:
1. Strato di Input (Input Layer): Riceve l’informazione iniziale. Ad esempio, se la rete deve riconoscere un’immagine, lo strato di input avrà un nodo per ogni pixel dell’immagine.
2. Strati Nascosti (Hidden Layers): Qui avviene la magia dell’elaborazione. Gli strati nascosti eseguono tutti i calcoli intermedi, estraendo caratteristiche e pattern complessi dai dati.
- Una rete è considerata di Apprendimento Profondo (Deep Learning) quando ha almeno due o più strati nascosti, consentendole di gestire problemi di complessità estrema.
3. Strato di Output (Output Layer): Produce il risultato finale della rete. Se il compito è classificare un’immagine come “cane” o “gatto”, lo strato di output avrà due nodi, e quello con il valore più alto sarà la previsione.
Il segreto dell’apprendimento: propagazione e aggiustamento
Come impara la rete neurale? Attraverso un processo iterativo di tentativi ed errori in due fasi principali, utilizzando dati di addestramento etichettati:
- Propagazione in avanti (forward propagation)
- I dati di addestramento entrano attraverso lo strato di input.
- L’informazione fluisce attraverso gli strati, nodo per nodo, fino allo strato di output.
- La rete produce una previsione.
- Retropropagazione (backpropagation) e ottimizzazione
- Calcolo dell’Errore: Si utilizza una funzione di perdita (o costo) per misurare la differenza o l’errore tra la previsione della rete e il risultato reale atteso (l’etichetta corretta).
- Retropropagazione: L’errore si propaga all’indietro attraverso la rete (dallo strato di output agli strati nascosti e di input).
- Aggiustamento dei Pesi: Utilizzando il calcolo dell’errore (attraverso un processo chiamato Discesa del Gradiente), la rete aggiusta i pesi e i bias di tutte le connessioni in modo che, nell’iterazione successiva, l’errore sia minore.
Questo ciclo di Propagazione → Errore → Aggiustamento dei Pesi si ripete migliaia o milioni di volte (chiamate epoche) fino a quando l’errore è minimo e la rete ha imparato la relazione tra input e output con alta precisione.
Tipi chiave di reti e le loro applicazioni più importanti
Non tutte le reti neurali sono uguali. Le loro architetture variano per adattarsi meglio a diversi tipi di dati e problemi.
Esempio pratico da zero (Python + NumPy)
Per prima cosa, costruiamo una rete neurale manuale per classificare dati semplici:
import numpy as np
# Dati di esempio (XOR problem)
X = np.array([[0,0],[0,1],[1,0],[1,1]])
y = np.array([[0],[1],[1],[0]])
# Inizializzazione dei pesi
np.random.seed(42)
W1 = np.random.randn(2, 2) # pesi strato nascosto
b1 = np.zeros((1, 2))
W2 = np.random.randn(2, 1) # pesi strato di output
b2 = np.zeros((1, 1))
# Funzione di attivazione (sigmoid)
def sigmoid(z):
return 1 / (1 + np.exp(-z))
# Addestramento semplice
lr = 0.1
for epoch in range(10000):
# Forward
z1 = X.dot(W1) + b1
a1 = sigmoid(z1)
z2 = a1.dot(W2) + b2
a2 = sigmoid(z2)
# Backpropagation
error = y - a2
d2 = error * a2 * (1 - a2)
d1 = d2.dot(W2.T) * a1 * (1 - a1)
# Aggiornamento dei pesi
W2 += a1.T.dot(d2) * lr
b2 += np.sum(d2, axis=0, keepdims=True) * lr
W1 += X.T.dot(d1) * lr
b1 += np.sum(d1, axis=0, keepdims=True) * lr
# Previsioni
print("Previsioni finali:")
print(a2.round())Code language: PHP (php)Questo codice addestra una rete neurale da zero per risolvere il classico problema XOR, che è un esempio fondamentale nell’apprendimento automatico e nell’intelligenza artificiale che mette in evidenza le limitazioni dei modelli lineari.
Esempio con librerie moderne (PyTorch)
Ora, la stessa idea ma con PyTorch, molto più pratico:
import torch
import torch.nn as nn
import torch.optim as optim
# Dati XOR
X = torch.tensor([[0,0],[0,1],[1,0],[1,1]], dtype=torch.float32)
y = torch.tensor([[0],[1],[1],[0]], dtype=torch.float32)
# Definizione della rete
class XORNet(nn.Module):
def __init__(self):
super(XORNet, self).__init__()
self.hidden = nn.Linear(2, 2)
self.output = nn.Linear(2, 1)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
x = self.sigmoid(self.hidden(x))
x = self.sigmoid(self.output(x))
return x
# Addestramento
model = XORNet()
criterion = nn.MSELoss()
optimizer = optim.SGD(model.parameters(), lr=0.1)
for epoch in range(10000):
optimizer.zero_grad()
outputs = model(X)
loss = criterion(outputs, y)
loss.backward()
optimizer.step()
print("Previsioni finali:")
print(model(X).round().detach())
Applicazioni reali delle reti neurali artificiali
Le RNA sono il motore dell’attuale rivoluzione dell’IA, guidando innovazioni in quasi tutti i settori:
- Medicina: Rilevazione precoce di malattie (tumori, retinopatie) analizzando immagini mediche con maggiore velocità e precisione rispetto a un occhio umano.
- Finanza: Rilevazione di frodi in tempo reale analizzando pattern di transazioni atipiche e modelli di rischio predittivo.
- Tecnologia: Motori di raccomandazione di Netflix o Amazon, assistenti virtuali come Siri e Alexa e sistemi di traduzione automatica come Google Translate.
- Robotica e Automazione: Controllo di robot industriali e la presa di decisioni in veicoli autonomi.
La Rete Neurale non è magia, è matematica!
È il modo in cui riusciamo a far sì che una macchina impari dall’esperienza a un livello di complessità senza precedenti, avvicinandoci sempre di più a replicare l’incredibile capacità dell’intelligenza naturale. Comprendere i suoi fondamenti è comprendere il pilastro dell’IA moderna. Il futuro è qui, ed è connesso!



