
In questo articolo, descriveremo cos’è DataBricks e perché potremmo aver bisogno di usarlo anche con Python.
Mostreremo che in DataBricks possiamo utilizzare, tra gli altri, Python come linguaggio di programmazione. In particolare, mostreremo come sia possibile utilizzare i Notebooks che DataBricks ci fornisce allo stesso modo in cui utilizziamo i Jupyter Notebooks.

Il caso d’uso che implementeremo alla fine di questo articolo, infine, mostrerà quanto sia facile usare Python per fare analisi dei dati e/o predizioni con il Machine Learning usando i Notebooks in DataBricks.
Introduzione a DataBricks
DataBricks è una piattaforma Data Lakehouse che “combina i migliori elementi dei Datalakes e dei Data Warehouses per aiutarti a ridurre i costi e a fornirti più rapidamente soluzioni legate ai dati e all’AI“.
Il concetto di Data Lakehouse è nato solo di recente (circa nel 2020) e va oltre i concetti e le strutture di Data Warehouse e Data Lake. Vediamo come.
Il concetto e la struttura dei Data Warehouse sono nati negli anni ’80. Si tratta di un modello che ci dà la possibilità di gestire dati strutturati – ovvero: testo e numeri – in un ambiente strutturato – per semplificare e chiarire: un database che utilizza SQL.
Negli ultimi anni – circa nel 2010 -, vista la necessità di organizzare dati non strutturati – ovvero: audio, immagini, e così via – è nata l’architettura dei Data Lakes. Questa ci dà la possibilità di archiviare i dati non strutturati in un luogo unico per ulteriori analisi.
Uno dei grandi svantaggi dei Data Lake è che per creare report BI abbiamo prima bisogno di ETL per strutturare i dati. Ovvero: dobbiamo creare uno (o più!) Data Warehouse all’interno del Data Lake da cui attingiamo i dati. Solo dopo questo passaggio, possiamo analizzare i dati e creare report di BI.
Una Data Lakehouse, invece, è un nuovo sistema “che affronta i limiti dei Data Lake. Un Lake House è una architettura nuova che combina i migliori elementi dei data lake e data warehouse”.
Semplificando, i principali vantaggi dei Data Lakehouse rispetto ai Data Lake sono:
- Supporto degli strumenti di BI. Gli strumenti di BI possono essere utilizzati direttamente dai dati di origine.
- Governance dei dati. Garantiscono l’integrità dei dati attraverso la governance.
- Riduzione dei costi di archiviazione dei dati. I Data Lakehouse hanno generalmente costi di storage dei dati inferiori rispetto ai Data Lakes.
In poche parole, DataBricks è:
“Una piattaforma per i tuoi dati, governata in modo coerente e disponibile per tutte le tue analisi e per l’utilizzo dell’IA“.
Lettura consigliata: Come programmare con Python: Il linguaggio versatile che conquista tutti
Come iniziare ad utilizzare DataBricks
Per iniziare ad utilizzare DataBricks, dobbiamo prima creare un account qui. DataBricks è un servizio a pagamento, ma ci fornisce una licenza di prova di 14 giorni.
Se hai un account su un servizio cloud, come AWS o Azure, puoi usarlo: questo torna utile se hai dei dati archiviati in uno di questi servizi.
Se non ne hai uno, non è necessario crearlo. Dopo aver compilato i campi per la registrazione, infatti, puoi specificare che non hai un account su nessuno dei servizi elencati: DataBricks ti farà, allora, utilizzare il suo servizio cloud.
Il processo di registrazione è facile e veloce e, in un paio di minuti (forse, meno), sei dentro e puoi iniziare a lavorare con DataBricks. Ad esempio, puoi lanciare un nuovo Notebook o importare dati dal tuo computer locale:

La prima cosa che dobbiamo fare è caricare alcuni dati in DataBricks prima di poterli effettivamente utilizzare per i nostri scopi. Questo processo in DataBricks è chiamato “creazione di cluster” perché ti verranno assegnate alcune risorse computazionali.
Il processo può essere avviato facendo clic su “Data” nella barra laterale di sinistra:
Qui possiamo scegliere tra tre opzioni:
- Upload a file. Questo ci fa caricare un file dalla nostra macchina locale.
- S3.Questo ci fa recuperare i dati da Amazon S3: lo storage di oggetti scalabili di Amazon.
- Other Data Sources. Qui puoi scegliere tra varie fonti, tra cui Amazon Kinesis, Snowflakes e altre.
Useremo un set di dati per prevedere il prezzo delle case. Puoi scaricarlo da Kaggle qui.
Scarichiamo il file, lo scompattiamo e carichiamo il file CSV in DataBricks:
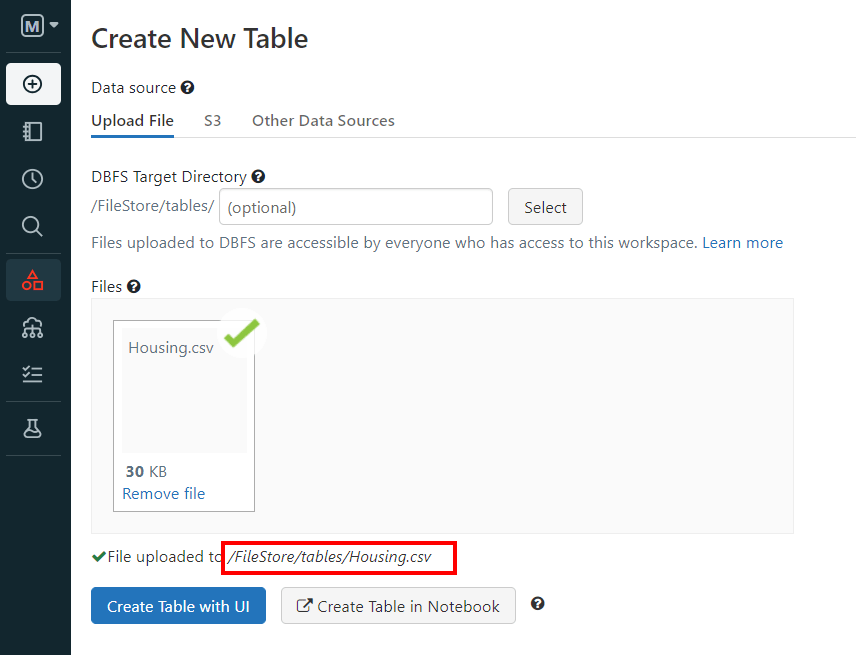
Come si può vedere, DataBricks assegna al file un path che indica la posizione in cui questo è stato salvato.
Lettura consigliata: Librerie Python per Data Science: una guida completa
Python in DataBricks
Prima di iniziare le nostre analisi, che si parli di Machine Learning o di analisi dei dati, dobbiamo creare un nuovo Notebook. Possiamo farlo dalla dashboard in questo modo:
Come possiamo vedere, il Notebook è graficamente simile ad un Jupyter Notebook o ad un Notebook di Google Colaboratory.
Se vogliamo, possiamo vedere le risorse che abbiamo a disposizione nel nostro cluster. Nella barra laterale sinistra clicchiamo su “Compute” e questo è ciò che si può vedere:
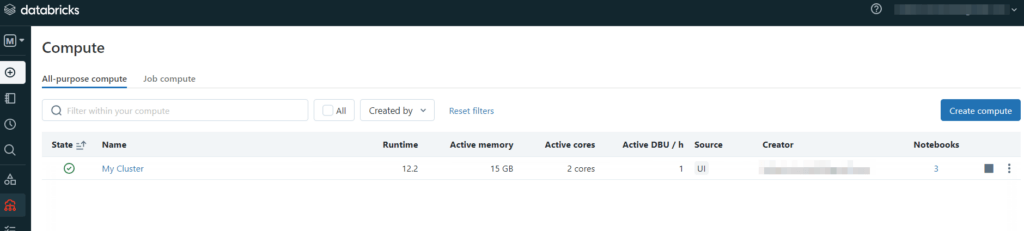
Quindi, ci è stato assegnato un cluster con 2 core attivi e 15 Gb.
Torniamo ora al nostro Notebook.
Per installare una libreria Python dobbiamo usare il magic command “%”.
La cosa importante da sapere è che DataBricks è già dotato di tutte le librerie Python più utilizzate. Quindi, per esempio, se vogliamo installare Pandas dobbiamo digitare %pip install pandas. In questo caso, DataBricks ci dirà che Pandas è già installato:
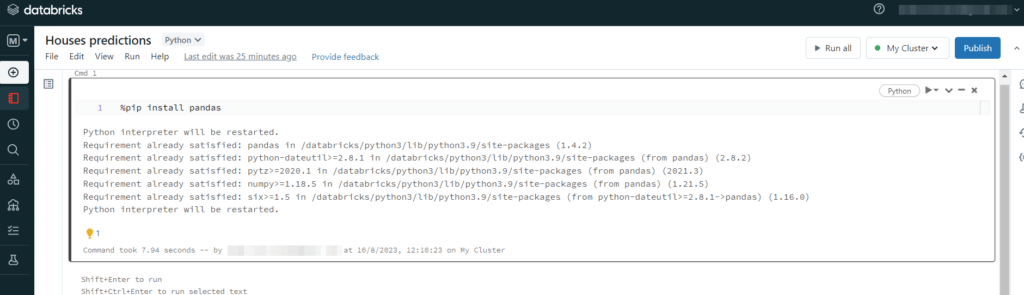
Quindi, se non abbiamo bisogno di una libreria particolare, possiamo importare i nostri dati e passare direttamente alla loro analisi.
DataBricks ci aiuta anche ad accelerare il processo relativo al caricamento dei dati ed alla loro successiva analisi. In particolare, DataBricks può creare direttamente un nuovo Notebook ed aggiungere i dati al nostro cluster quando li importiamo.
Supponiamo, quindi, di voler analizzare i dati relativi alle case, come abbiamo detto prima. Questa volta il nome del file è houses.csv. Possiamo eseguire il processo cliccando su “Create a table in a Notebook”:
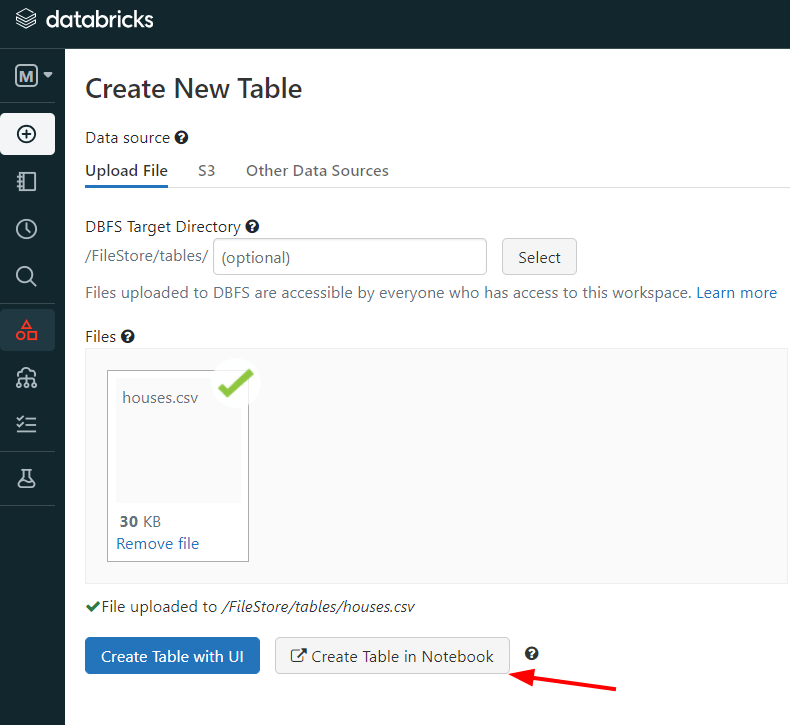
Quindi, DataBricks crea per noi un Notebook già pronto all’uso:
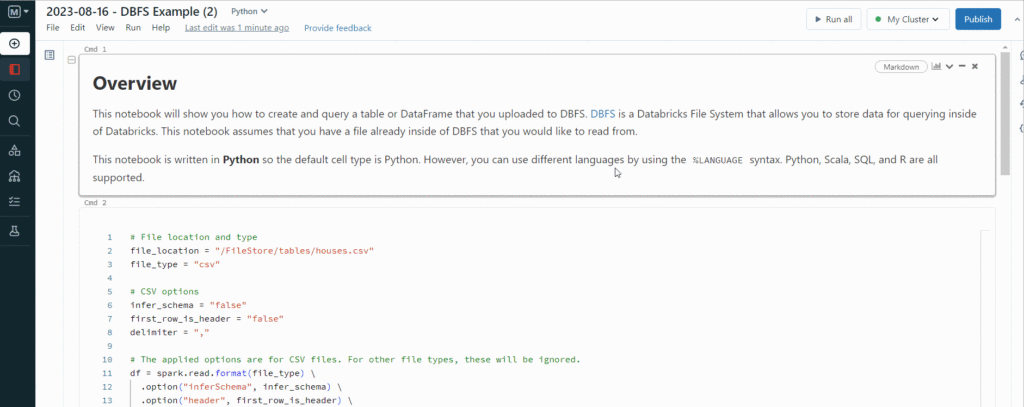
Quindi, DataBricks ha creato un Notebook pronto all’uso con la prima cella che è scritta in Spark. In questo modo, come si può vedere, appena la eseguiamo, questa ci mostra i dati che abbiamo caricato.
Analisi dei dati e Machine Learning con Python in DataBricks
Adesso vogliamo fare alcune predizioni con il Machine Learning utilizzando DataBricks.
Per semplicità, possiamo utilizzare il set di dati “Diabetes” fornito da sklearn.
Apriamo un nuovo Notebook in DataBricks come abbiamo mostrato in precedenza e importiamo tutte le librerie di cui abbiamo bisogno:
import pandas as pd
import numpy as np
# Plotting
import seaborn as sns
import matplotlib.pyplot as plt
# Images dimensions
plt.figure(figsize=(10, 7))
# Sklearn
from sklearn.datasets import load_diabetes #importing data
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import train_test_split
from sklearn import linear_model
from sklearn import metrics
Code language: PHP (php)Adesso, visualizziamo i nostri dati:
# Import dataset
diab = load_diabetes()
# Definine feature and label
X = diab['data']
y = diab['target']
# Create dataframe from X
df = pd.DataFrame(X, columns=["age","sex","bmi","bp", "tc", "ldl", "hdl","tch", "ltg", "glu"])
# Add 'progression' from y
df['progression'] = diab['target']
# Show head
df.head()
Code language: PHP (php)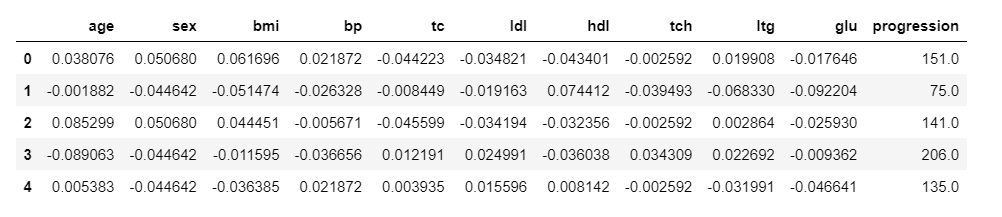
Come prima cosa diciamo che non c’è stato bisogno di installare nessuna delle librerie importate sopra: sono tutte già installate in DataBricks.
Ora, vediamo se ci sono features altamente correlate con una matrice di correlazione come la seguente:
# Apply mask
mask = np.triu(np.ones_like(df.corr()))
# Show correlation matrix
dataplot = sns.heatmap(df.corr(), annot=True, fmt='.2f', mask=mask)Code language: PHP (php)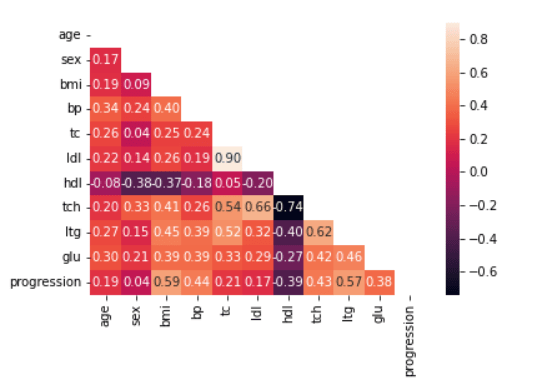
Adesso, dividiamo il set di dati nel train e test sets, facciamo il fit con un modello di regressione lineare, e calcoliamo R2:
# Define features
X = df.iloc[:,:-1]
# Define label
y = df['progression']
# Split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2,random_state=42)
# Fit lin. regr. the model
reg = LinearRegression().fit(X_train, y_train)
# Make predictions
y_test_pred = reg.predict(X_test)
y_train_pred = reg.predict(X_train)
# R^2 on both sets
print(f'Coeff. of determination on train set:{reg.score(X_train, y_train): .2f}')
print(f'Coeff. of determination on test set:{reg.score(X_test, y_test): .2f}') Code language: PHP (php)Otteniamo:
Coeff. of determination on train set: 0.53
Coeff. of determination on test set: 0.45
Code language: JavaScript (javascript)Quindi, i risultati di R2 non sono molto convincenti e dovremmo provare altri modelli di Machine Learning per risolvere questo problema.
Ad ogni modo, qui abbiamo dimostrato che un Notebook in DataBricks può essere utilizzato esattamente come qualsiasi altro Notebook.
Conclusioni
In questo articolo abbiamo descritto l’importanza di DataBricks come Lakehouse che, tra le varie cose, ci consente anche di gestire complicati flussi di lavoro con il ML.
Ad ogni modo, abbiamo anche mostrato come utilizzare i Notebooks in DataBricks con Python. Inoltre, abbiamo anche inoltre visto che DataBricks ha già installate tutte le librerie Python più utilizzate, semplificandoci il lavoro.
Come abbiamo detto, possiamo utilizzare i Notebooks in DataBricks allo stesso modo in cui utilizziamo i Jupyter Notebooks, ma con il vantaggio di poter gestire flussi di lavoro complicati ed enormi quantità di dati, nonché dati non strutturati, a seconda del problema che stiamo risolvendo.
In conclusione, alcuni dei motivi per cui potremmo utilizzare DataBricks sono quando abbiamo bisogno di:
- Affrontare l’elaborazione e l’analisi dei dati su larga scala.
- Un ambiente collaborativo in cui data scientist, analisti e ingegneri possano lavorare insieme.
- Creare pipeline di Machine Learning end-to-end.
- Analizzare ed elaborare dati in tempo reale.
- Sfruttare le funzionalità di Apache Spark senza gestirne l’infrastruttura sottostante.

