
Nel mondo dello sviluppo, git è un elemento imprescindibile che ci permette di gestire il codice in maniera sicura e collaborativa, permettendo di apportare modifiche allo stesso senza causare problemi ad ambienti di produzione.
Il codice principale è presente nel branch main. Possiamo creare poi dei branch diversi, a partire dal main, sui quali apportare delle modifiche, che verranno salvate sugli stessi attraverso dei commit. Solitamente il branch main è quello collegato ai deployment che avvengono sugli ambienti di produzione. Una volta che le modifiche sono pronte per andare in produzione, a seguito di una fase di review e di una fase di test, sarà possibile effettuare una merge request del nuovo branch verso il main. A questo punto le modifiche saranno presenti nel branch main, dal quale possiamo effettuare un nuovo deployment che conterrà il codice aggiornato sull’ambiente target.

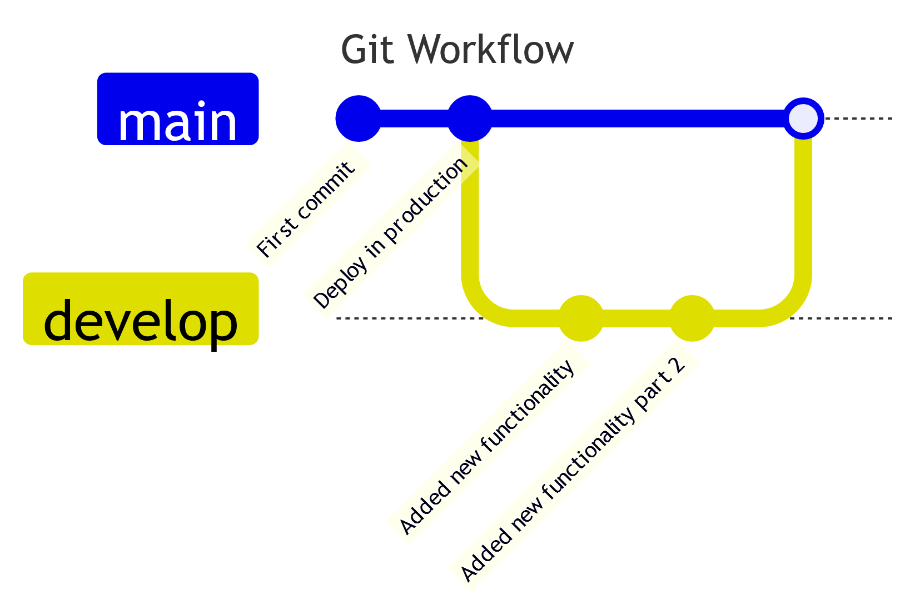
Approccio Git-like in ambito Data
Sarebbe interessante portare gli stessi concetti anche in ambito Data: prelevare i dati con la pipeline dalle sorgenti, inserirli in un branch dedicato e a seguito dell’esecuzione positiva di alcuni test effettuare il merge dei dati aggiornati sul branch principale così da poter essere acceduti in produzione. E se dovessimo accorgerci di alcune incongruenze quando ormai è stato fatto il merge? Ci comportiamo come nello sviluppo: con un rollback al commit precedente, o comunque all’ultimo momento in cui i dati erano corretti.
Proviamo dunque a vedere come raggiungere questo scopo sfruttando soluzioni open source. Come primo tassello occorrerà il sistema su cui salvare fisicamente i dati. In questo caso utilizziamo MinIO, un object storage che espone le API di S3 e altamente performante.
Per ottenere le funzionalità git-like occorrerà effettuare transazioni ACID sull’object storage, che di sua natura non offre, e questo viene fornito grazie ad un table format che attraverso la gestione dei metadati consente di garantire questa proprietà. In questo caso il table format scelto è Apache Iceberg, anch’esso open source. Un table format, tuttavia, mantiene le informazioni sulla singola tabella. Per avere una vera esperienza git-like vorremmo poter gestire più tabelle contemporaneamente. Questo viene garantito grazie ad un table repository, che riesce ad avere contezza di tutte le tabelle da gestire e che mantiene il puntatore all’ultima versione dei metadati su cui debbano avvenire scritture o letture. Ecco che corre in nostro soccorso Project Nessie, un table repository open source che offre un’esperienza git-like sui dati.
Infine, occorre uno strumento con il quale poter accedere i dati presenti nel data lakehouse e dal quale poter creare delle viste utili per gli scopi finali, come ad esempio Dremio. Andiamo dunque a vedere nel dettaglio ogni singolo layer descritto in precedenza che comporrà il Data Lakehouse con funzionalità git.
Object Storage
L’object storage è il sistema che permette di salvare grandi quantità di dati non strutturati al suo interno. Corrisponde in questo caso al data lake, ed i dati vi sono salvati sottoforma di oggetti. Il data lake offre la possibilità di immagazzinare grandi quantità di dati non strutturati, a differenza del data warehouse nel quale i dati salvati hanno una struttura ben definita. Tuttavia la caratteristica di salvare dati non strutturati può rivelarsi anche uno svantaggio in quanto le performance di ricerca sono inferiori. Inoltre, l’object storage non supporta le transazioni ACID che invece sono presenti nei database relazionali tradizionali e che permettono di effettuare delle validazioni sullo schema e sulla consistenza in fase di ingestion dei dati anziché in fase di lettura. Oltre a questo, permettono di garantire la consistenza dei dati quando vi sono più scrittori/lettori in contemporanea su una stessa tabella.
Table format
Per ovviare all’assenza delle transazioni ACID, e per far diventare il data lake, un data lakehouse, è fondamentale il table format. Esso crea un livello di astrazione sopra l’object storage che migliora le performance ed abilita le transazioni ACID direttamente sul data lake.
Il table format altro non è che un metodo per strutturare ed unificare i dati presenti nell’object storage come un’unica tabella. Risponde alla domanda “quali dati ci sono nella tabella?” e lo fa grazie a come vengono organizzati e gestiti i metadati. Questo permette agli utenti ed ai tool che interagiscono con la tabella, di farlo in maniera più efficiente.
Table repository
Il catalogo di Iceberg mantiene il puntatore all’ultimo metadata file da poter utilizzare per le scritture e per le letture. Esso è relativo alla sola tabella di indagine. Il table repository è il luogo in cui vengono salvati i cataloghi Iceberg per tutte le tabelle. In questo modo, gli utenti o gli strumenti che interagiscono con le tabelle presenti nel catalogo sanno di leggere o scrivere la versione corretta.
Data access
Il Data Access funge da ponte tra gli utenti e le sorgenti dati presenti nell’infrastruttura. La sua funzione principale è quella di fornire un’interfaccia unificata per l’accesso ai dati, spesso utilizzando linguaggi standard come SQL. Questo permette agli utenti di eseguire query e analisi sui dati senza la necessità di conoscere i dettagli di implementazione delle varie sorgenti dati. Infine, il Data Access permette di gestire le autorizzazioni degli utenti in maniera granulare, garantendo l’accesso ai dati sensibili solo a coloro che hanno i permessi necessari per farlo.
Tecnologie utilizzate
Adesso che abbiamo chiarito cosa serve per abilitare l’esperienza git-like nel data lakehouse, descriveremo più nel dettaglio le tecnologie scelte per ogni singolo layer visto in precedenza.
MinIO – Object Storage
MinIO è un object storage che fornisce compatibilità alle API Amazon Web Services S3, e supporta tutte le sue funzionalità core. MinIO è nativamente è compatibile per l’installazione su Kubernetes, tuttavia può essere installato qualsiasi modo: reti pubbliche o private, bare metal, in ambienti orchestrati o infrastrutture edge.
Le funzionalità core di MinIO sono:
- Scalabilità: Minio è un sistema distribuito che può essere scalato orizzontalmente aggiungendo nodi
- Disponibilità: Al fine di garantire l’alta affidabilità, Minio replica i dati su più nodi, in modo tale da persistere i dati, anche in caso di perdita di uno o più nodi
- Sicurezza: Vengono offerte una serie di funzionalità sulla sicurezza, tra cui autenticazione, controllo degli accessi e crittografia dei dati salvati
- Velocità: MinIO è molto performante per la lettura e scrittura dei dati su S3
- Compatibilità con API S3: Viene fornita la compatibilità con il protocollo S3, il che lo rende facile da usare con applicazioni che già utilizzano questa tipologia di protocollo
Apache Iceberg – Table format
Apache Iceberg è un Table Format open source molto performante, che tramite query SQL-like permette l’analisi di grandi quantità di dati. Permette a più engine in contemporanea di operare su uno stesso dataset senza creare problemi di consistenza. Tra le caratteristiche principali sono presenti:
– Transazioni ACID: attraverso la sua architettura, Apache Iceberg abilita le transazioni ACID garantendo la concorrenza ottimistica in situazioni in cui più scrittori o lettori vogliono accedere ad una determinata risorsa.
– Dinamicità nelle partizioni: nel Data Lake, senza Iceberg, se volevamo cambiare il partizionamento di una tabella, dovevamo riscriverla interamente. Con Iceberg, invece, il partizionamento diventa dinamico e può cambiare in ogni momento.
– Hidden partitioning: Iceberg produce i valori per le partizioni e le utilizza nelle query in maniera trasparente a chi scrive o legge.
– Time travel: grazie a degli snapshot immutabili sui dati, è possibile effettuare delle query su degli snapshot antecedenti temporalmente, evitando la duplicazione dei dati.
– Version rollback: grazie alla proprietà citata sopra, è possibile anche effettuare un vero e proprio rollback su versioni precedenti dei dati.
– Evoluzione dello schema: Iceberg supporta anche i cambiamenti che possono avvenire sullo schema di una tabella.
Utilizzare un Table Format open source permette di non avere lock-in nella scelta delle tecnologie con cui interagisce. Ad esempio, Apache Iceberg è supportato da Dremio per la lettura e la scrittura dei metadati su sorgenti di tipo S3, come ad esempio MinIO. Apache Iceberg organizza i metadati in una struttura gerarchica e ciò consente agli engine con cui interagisce di apportare modifiche rapide ed efficienti alle tabelle senza ridefinire tutti i file del set di dati, garantendo così prestazioni ottimali quando si lavora su scala di Data Lake.
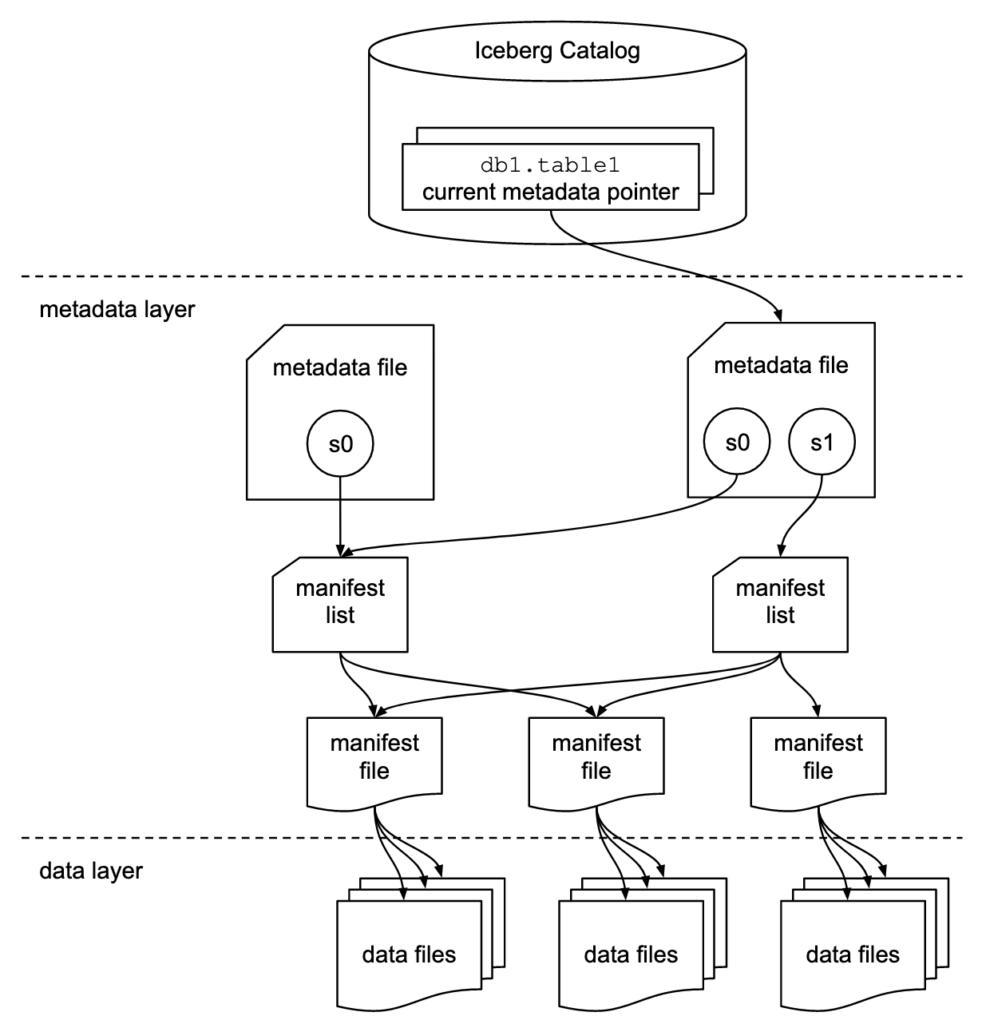
Come radice dell’albero in figura vi è l’Iceberg Catalog, che nel nostro caso è Project Nessie come vedremo successivamente, ossia il Table Repository che tiene traccia dell’attuale puntatore ai metadati. Il metadata layer è composto da tre livelli:
- Metadata file: include informazioni sullo schema della tabella, informazioni sulle partizioni, sugli snapshot e circa lo snapshot attuale.
- Manifest list: contiene una lista di manifest file assieme alle informazioni dei manifest file che hanno effettuato uno snapshot.
- Manifest file: tracciano i data file oltre che avere altri dettagli e statistiche per ogni file
Il data layer contiene i data files veri e propri. Tutta questa struttura illustrata fino ad ora, dall’Icebrg Catalog fino al Data Layer può risiedere su un Object Storage di tipo S3, come MinIO. Inoltre può interagire senza problemi con Dremio, abilitando di fatto a quello che è a tutti gli effetti un Data Lakehouse.
Project Nessie – Table Repository
Project Nessie è un catalogo transazionale open source utilizzato nei Data Lake. Oltre ad assumere il ruolo di Table Repository per le tabelle Iceberg, come visto nel paragrafo precedente, è molto utile perchè abilita le funzionalità Git-like nel Data Lake. Per questo motivo abbiamo individuato questa tecnologia come Table Repository, dato che non si limita al solo ruolo di catalogo transazionale. È possibile abilitare il versionamento non solo su una tabella alla volta come permetteva Iceberg, ma anche su più tabelle contemporaneamente. Consente, dunque, la creazione di branch sui quali apportare modifiche, mantenendo consistenti i dati e permettendo di fare un merge quando siamo certi che le modifiche effettuate siano corrette. Project Nessie, quando gestisce più versioni di una tabella in diversi branch, non applica una copia dei dati ma si limita a gestire i metadata file delle tabelle Iceberg. Un altro fattore che ci ha portato a scegliere questa tecnologia, è il fatto che è supportata da Dremio come Metadata Catalog e come storage supporta Object Storage di tipo S3 come, ad esempio, MinIO.
Alcuni dei concetti fondamentali in Project Nessie sono:
– Commit: cambiamento atomico che avviene al set dei dati ed è il cambiamento minimo possibile in Nessie. In altre parole, rappresenta uno snapshot dei dati ad un certo punto nel tempo. Nel caso in cui dovessimo effettuare dei rollback basterà puntare ad un commit precedente.
– Branches: un branch referenzia l’ultimo commit presente in una catena di commit. Branch diversi possono puntare ad uno stesso commit o a commit diversi, ed è in questo modo che Nessie gestisce la concorrenza di job verso uno stesso data set.
– Merge: è possibile inserire i cambiamenti apportati su un branch verso un altro branch target.
Dremio – Data Access
Dremio è una piattaforma che abilita le analitiche self-service su un data lakehouse. Offre un’ampia gamma di sorgenti dalle quali attingere dati e grazie alle ottimizzazioni utilizzate (Apache Arrow e Reflections tra le altre) consente di accedere velocemente ai dati presenti nel data lake. Tra le varie sorgenti presenti vi è anche proprio Project Nessie ed inoltre supporta la scrittura in Apache Iceberg. Dremio nella nostra infrastruttura, implementa lo strato di data access. E’ in grado di fornire una modalità unificata per l’interrogazione e la modellazione dei dati presenti nell’architettura, tramite linguaggio SQL. Dremio offre la possibilità anche di virtualizzare i dati, in quanto permette l’aggregazione dei dati provenienti da sorgenti diverse. Infine, si integra con diversi tool di BI come ad esempio PowerBI, Superset e Tableau.

Architettura finale
Riassumendo, Project Nessie sarà il catalogo per le tabelle Apache Iceberg, che ovviamente dovranno essere scritte in un data lake, MinIO nel nostro caso. Utilizzando Dremio, è possibile promuovere una sorgente Project Nessie con la quale effettuare operazioni git-like direttamente da interfaccia o tramite query SQL-like.
L’immagine seguente ci aiuta a razionalizzare le diverse tecnologie e ci fa capire la loro interazione:
Specifichiamo che il table format descritto è semplificato visto che dal metadata pointer passiamo direttamente al data layer, questo perchè l’intento dell’immagine è quella di far vedere che diverse tabelle sono gestite dal table repository e che il table format alla fine gestisce dei file raw che vengono salvati sull’object storage.
Installazione delle componenti
L’installazione delle componenti utilizzate per questo tutorial è molto semplice. Ad esempio, facciamo riferimento ad una installazione on-prem utilizzando i pacchetti precompilati e un servizio standalone.
Per l’installazione di MinIO per un ambiente di test, è possibile effettuarne una Single Node Single Drive, seguendo gli step definiti nella guida ufficiale.
Per quanto riguarda l’installazione di Project Nessie è sufficiente scaricare il servizio standalone ed eseguirlo, come specificato nella documentazione ufficiale.
Anche l’installazione di Dremio è molto semplice, se utilizziamo una macchina che supporta l’installazione di pacchetti rpm basta seguire questa documentazione, altrimenti è possibile utilizzare i Tarball.
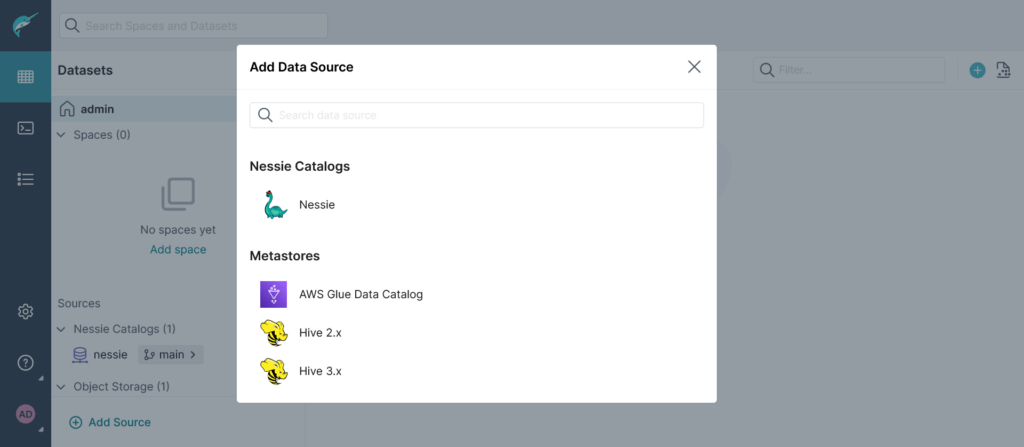
Promuovere una sorgente Project Nessie
Da interfaccia, cliccando su Sources è possibile scegliere la sorgente da utilizzare, in questo caso useremo il Nessie:
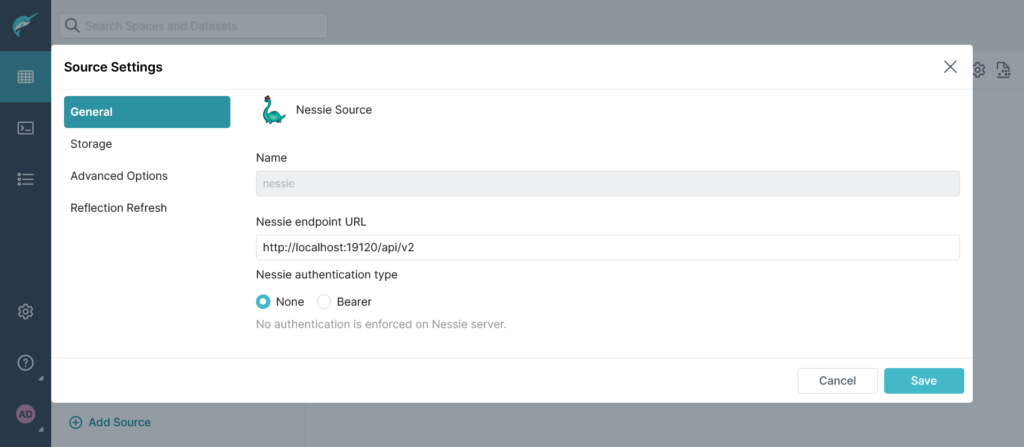
Tra le varie configurazioni, dovremmo settare un nome e l’endpoint sul quale è in ascolto, oltre un eventuale metodo di autenticazione:
Dovremmo specificare poi lo storage da utilizzare, come anticipato utilizzeremo MinIO per cui dovremmo specificare il bucket, l’access key e la secret key:
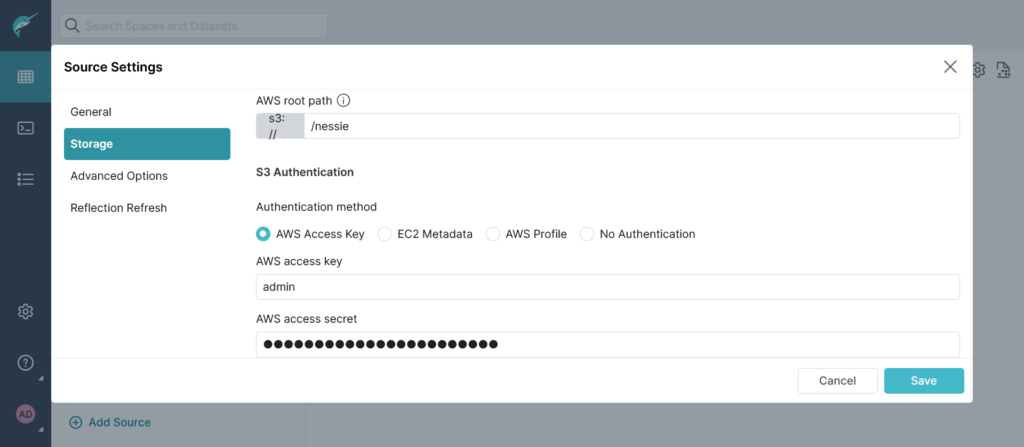
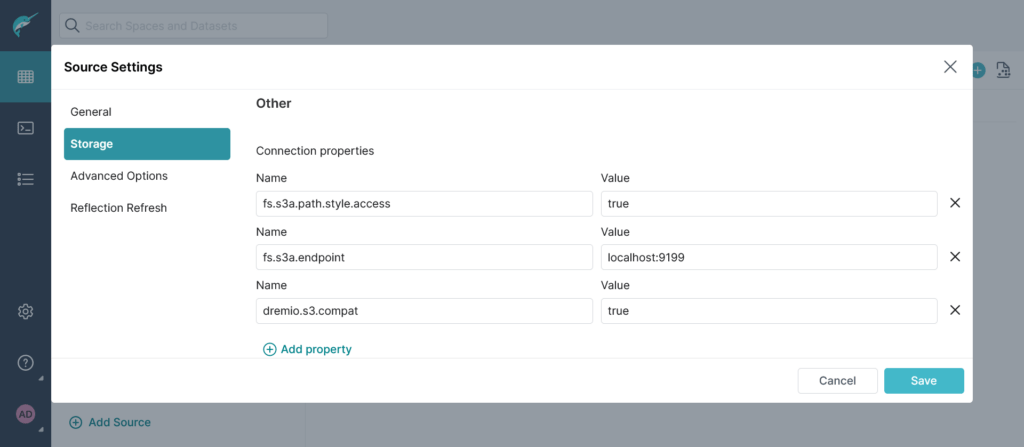
Allo stesso modo di come avviene se dovessimo promuovere come sorgente MinIO, dobbiamo specificare anche l’endpoint ed altre proprietà:
Creazione di una tabella Iceberg
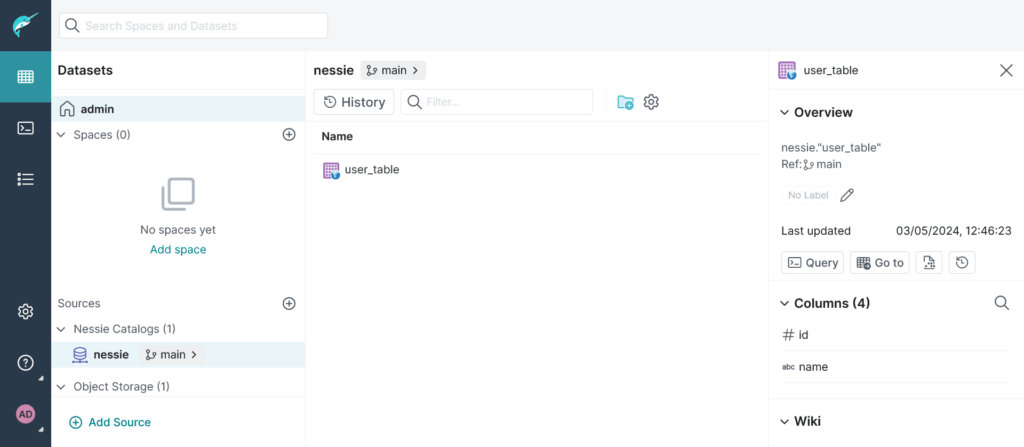
Vi è la possibilità di creare una tabella Iceberg specificando il catalogo creato, il cui nome in questo esempio sarà nessie:
create table nessie.user_table (id integer, name varchar, surname varchar, address varchar)Code language: CSS (css)A questo punto verrà creata una tabella vuota all’interno di Project Nessie ed è possibile visualizzare lo schema della stessa:
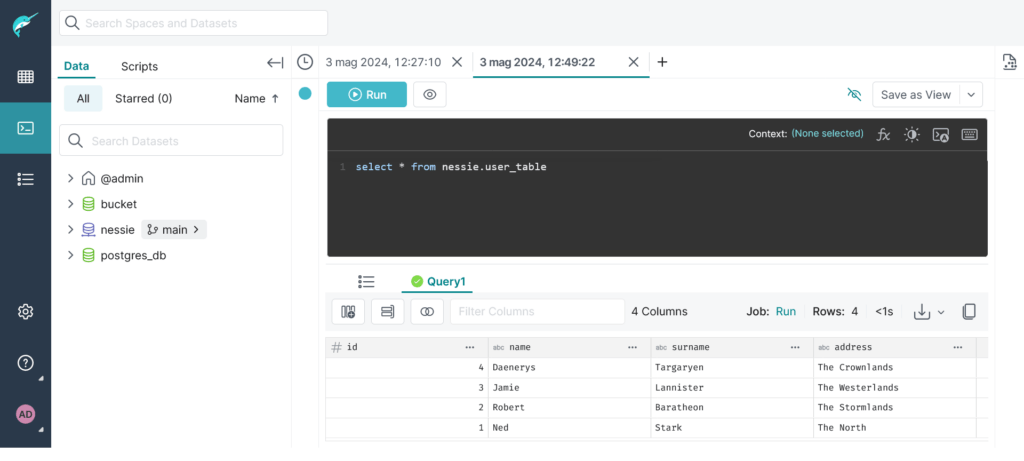
A questo punto, dal query engine di Dremio, potremmo inserire dei record all’interno della tabella:
INSERT INTO nessie.user_table VALUES (1, 'Ned', 'Stark', 'The North');
INSERT INTO nessie.user_table VALUES (2, 'Robert', 'Baratheon', 'The Stormlands');
INSERT INTO nessie.user_table VALUES (3, 'Jamie', 'Lannister', 'The Westerlands');
INSERT INTO nessie.user_table VALUES (4, 'Daenerys', 'Targaryen', 'The Crownlands');Code language: JavaScript (javascript)
Possiamo quindi visualizzarli su Dremio:
Creazione di un nuovo branch
A questo punto, proviamo a creare un nuovo branch con una query SQL-like sempre da Dremio:
CREATE BRANCH "scrittura_user_table" IN nessie;Code language: JavaScript (javascript)E da UI possiamo vedere che effettivamente il branch è stato creato correttamente:
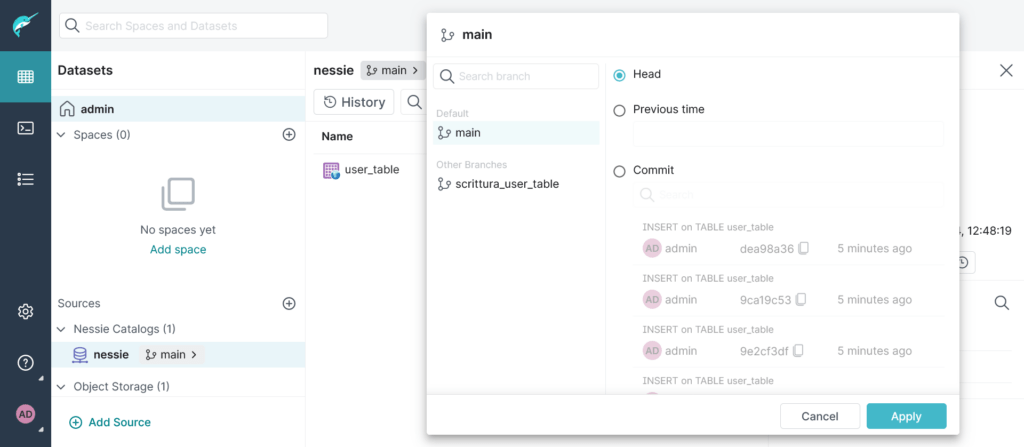
Adesso proviamo a scrivere dei nuovi record sul nuovo branch. Il branch può essere indicato in fase di inserimento delle nuove righe:
INSERT INTO nessie.user_table AT BRANCH "scrittura_user_table" VALUES (5, 'Tony', 'Soprano', 'New Jersey');
INSERT INTO nessie.user_table AT BRANCH "scrittura_user_table" VALUES (6, 'Don', 'Draper', 'New York');Code language: JavaScript (javascript)A questo punto possiamo notare la differenza tra i due branch:
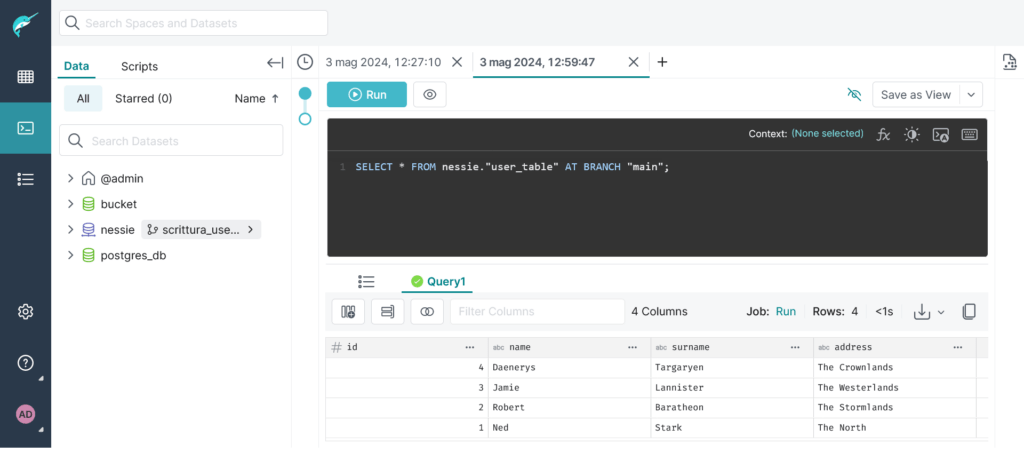
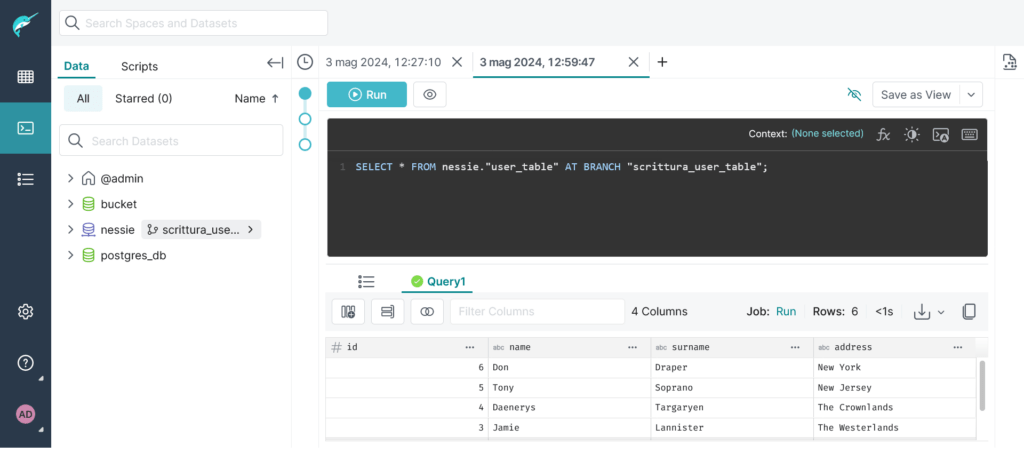
Operazione di merge in un branch
Possiamo dunque effettuare una merge del branch creato verso il main:
MERGE BRANCH "scrittura_user_table" INTO "main" IN nessie;Code language: JavaScript (javascript)E a questo punto effettuando una query sul main branch vedremo che i risultati sono presenti:
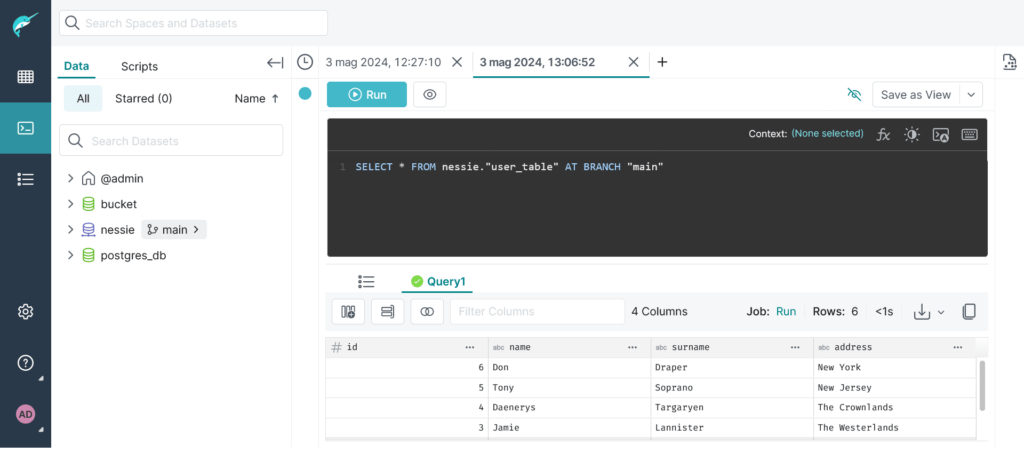
Il branch sorgente non è stato eliminato, ed è possibile avere una lista di tutti i commit effettuati:
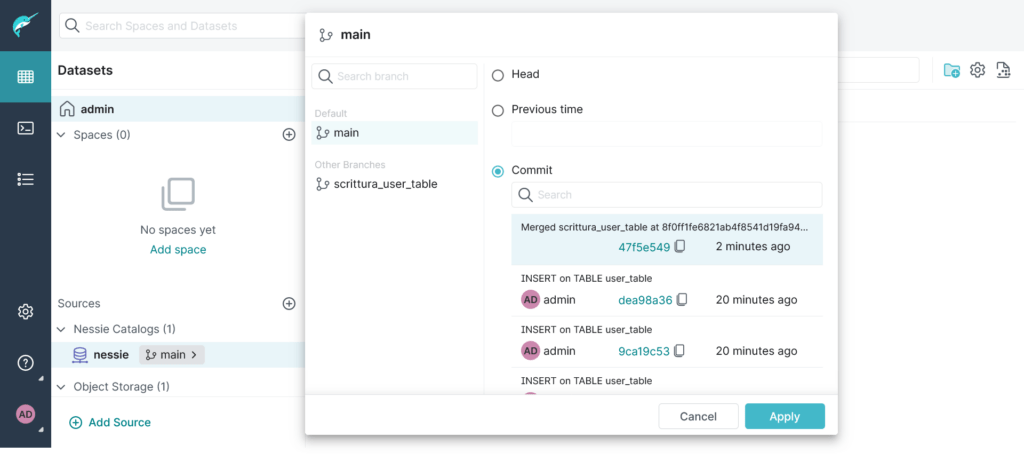
Rollback ad una versione precedente
A questo punto, ci siamo resi conto che le nuove righe aggiunte non sono consistenti. Possiamo fare dunque rollback alla versione precedente (specificando un commit oppure un istante nel tempo). In questo caso decido di tornare al commit precedente, prendendo l’identificativo direttamente da interfaccia:
ALTER BRANCH "main" ASSIGN COMMIT
"dea98a368953af01c9bc0b42398851e1851966bc791926debae2ff883eeb671f" IN nessie;Code language: JavaScript (javascript)
Ed effettuando una query è possibile notare che siamo tornati alla situazione di partenza:
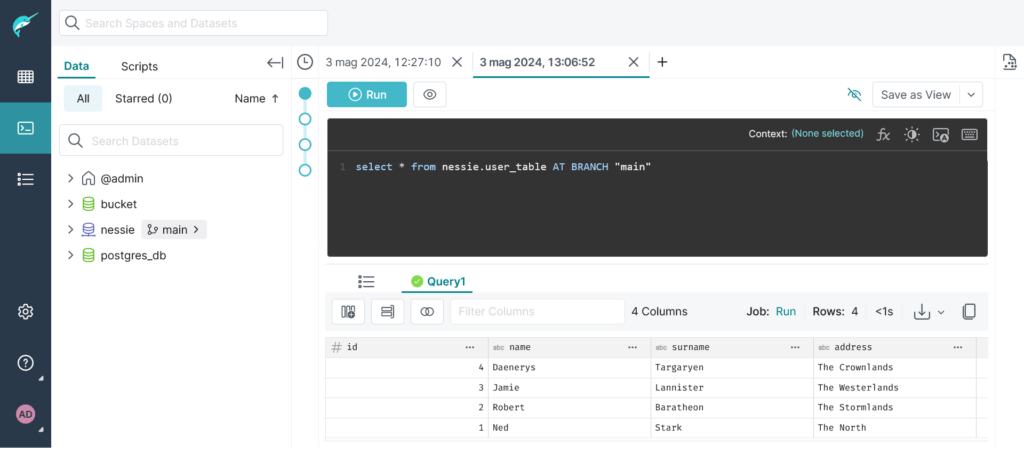
Rollback Apache Iceberg VS Rollback Project Nessie
In realtà, è possibile effettuare il rollback anche di una singola tabella Iceberg specificando o uno snapshot ID o un timestamp. Ad esempio, con il comando seguente, saremmo tornati alla versione delle ore 12.50 che non conteneva le nuove righe aggiunte:
ROLLBACK TABLE nessie.user_table TO TIMESTAMP '2024-05-03 12:50:00'Code language: JavaScript (javascript)Mentre il rollback con Apache Iceberg è relativo alle singole tabelle, quello eseguibile con Project Nessie spostando il puntatore ad un commit precedente, è relativo a tutte le tabelle presenti nel catalogo, ripristinando quindi il contenuto di tutte le tabelle che avevano subìto delle modifiche.
Come descritto anche in precedenza, dunque, la differenza sta nel fatto che con Apache Iceberg è possibile gestire il versionamento di una singola tabella, mentre con Project Nessie è possibile gestirlo di più tabelle contemporaneamente.
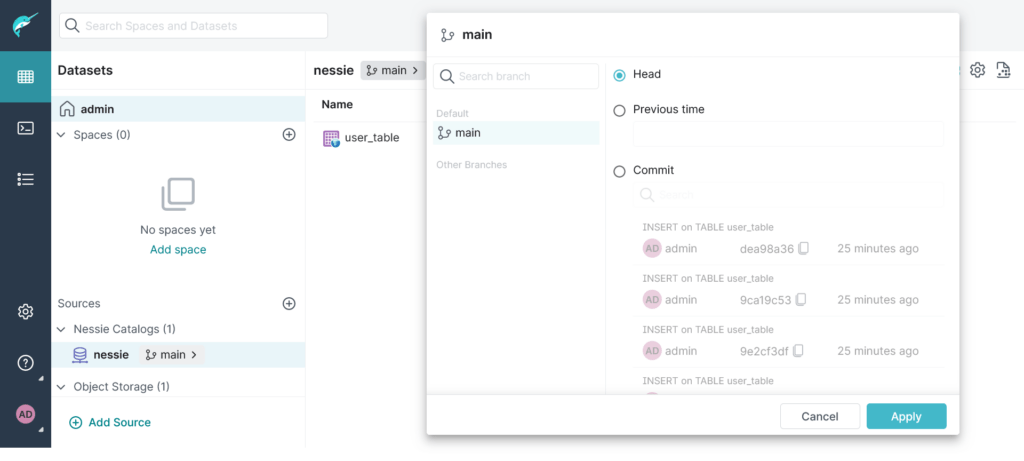
Eliminazione di un branch
Per evitare ulteriori danni, è possibile anche eliminare il branch nuovo che avevamo creato:
DROP BRANCH "scrittura_user_table" FORCE IN nessie;Code language: JavaScript (javascript)Effettivamente anche da UI non è più presente:
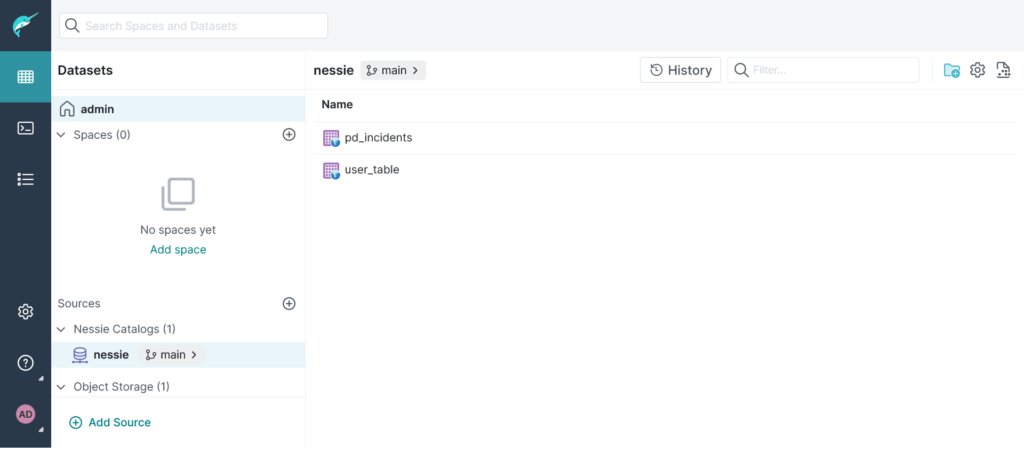
Creazione tabella Iceberg a partire da una VDS
Vi sono molti modi per creare una tabella Iceberg, partendo da un CSV o da un JSON, oppure anche a partire da una VDS. Ad esempio, per creare una tabella Iceberg nel catalogo Nessie a partire da una VDS, nella query dovremmo specificare il catalogo, il nome della tabella e il nome della VDS da cui essa ha origine:
create table nessie."pd_incidents" as select * from "@admin"."police_incidents";Code language: JavaScript (javascript)
A questo punto è disponibile nel catalogo Nessie e può subire le medesime operazioni viste in precedenza:

Lorenzo Pasco – Data Engineer @Seacom
Seacom – Società Benefit appartenente al gruppo ITWay e co – fondatore di RIOS (Rete Italiana Open Source), è un’azienda specializzata in consulenza e formazione su prodotti open source per aziende di livello Enterprise, enti e pubbliche amministrazioni.
Scopri di più su Seacom su: https://seacom.it



