
Machine Learning is an awesome tool and really affects our lives. But how can we be sure that a machine’s choices are fair? Let’s take a look and find out together.
Why do we care about bias?
Commonly, machines are considered almost faultless and for this reason we think that their decisions aren’t conditioned by prejudices. Unfortunately, this is completely wrong and Azzurra Ragone, Innovation Manager and previously Program Manager at Google, explained to us why in her talk at Codemotion Rome 2019.
Machine Learning algorithms, just like any other simpler algorithms, are made by people and discrimination is in human nature. Taking that into account, we can imagine why it is pretty easy for a certain belief to pass on to an Artificial Intelligence.
The question now is: should we care? Just try to imagine a situation where a life-changing decision is made by a machine. We are so used to others taking decisions for us, like a school admission, that we take for granted the fairness of their choice. But machines don’t know fairness, at least until we teach it to them.
In their book “Fairness and Machine Learning”, Solon Barocas, Moritz Hardt and Arvind Narayanan wrote:
Arbitrary, inconsistent, or faulty decision-making thus raises serious concerns because it risks limiting our ability to achieve the goals that we have set for ourselves and access the opportunities for which we are qualified.
One example is the geo-bias, a very frequent problem that originates from the western-centered world we live in. For instance, ImageNet, an image database organized by Machine Learning, has 45% of its images coming from the USA (4% of world population) while China and India (36% of world population) generate a mere 3% of images. The deficiency in culture variety leads to huge misunderstanding, like an Indian bridal dress being mistaken for a performer’s dress and so on.
This happens because a Machine Learning system works very well only if it is trained with large amounts of data. The obvious consequence is that minorities are not fairly represented by AIs.
Then how do they learn data?
The Machine Learning Loop
To describe how an AI learns, we use the Machine Learning Loop.
The process is very simple: we start from the current state of the World and, by measurement, we acquire Data. Then, a Model is produced by learning. Next, an effect is produced on Individuals by models’ actions and a successive feedback modifies the Model. Eventually, the state of the World will change and the Loop will start again.
Let’s look closer at the various steps.
Talking about measurement, we have to keep in mind that the origin of data is vital. Variables of interest, the process to transform observation into numbers, the data collection itself. Everything must be strictly defined.
However, the most critical phase, in which biases are easily introduced, is certainly the learning one. At this stage, our AI gains knowledge and information, but also prejudices and stereotypes. Using Google Translator as an example, the famous online interpreter, when translating from a gender-neutral language to English, it tends to associate doctors with men and nurses with women.
Moving on to the action segment, Machine Learning ranges from prediction to classification and each functionality can affect human life in serious ways. Bias isn’t generated in this phase but, of course, its effects take place.
Feedback is again a critical zone and it is essential to properly design the auto-correction strategy. In fact, wrong error management can lead to unexpected and, above all, unwanted results. For example, we should avoid self-fulfilling feedback loops, an event that occurs when data, discovered on the basis of predictions, is used to update the model. Case in point, a crime-predicting AI could increase security in high-crime zones, leading to a rise in minor crime detection. But this will eventually increase crime rates, causing a disproportion in security.
How do we avoid bias?
Completely eliminating bias is a very difficult task, but finding and fixing it is a realistic goal. To achieve this, first we need to analyse our AI and look for clues. Are there any missing features? Are there any unexpected values? Are data sources unbalanced? If, for any of these questions, the answer is yes, we must immediately do something.
One really useful tool in Machine Learning management is Facets. It helps explore data and gives us a clear representation of values distribution, like the quantity of samples for each gender and age, making us aware which segment is poorly trained.
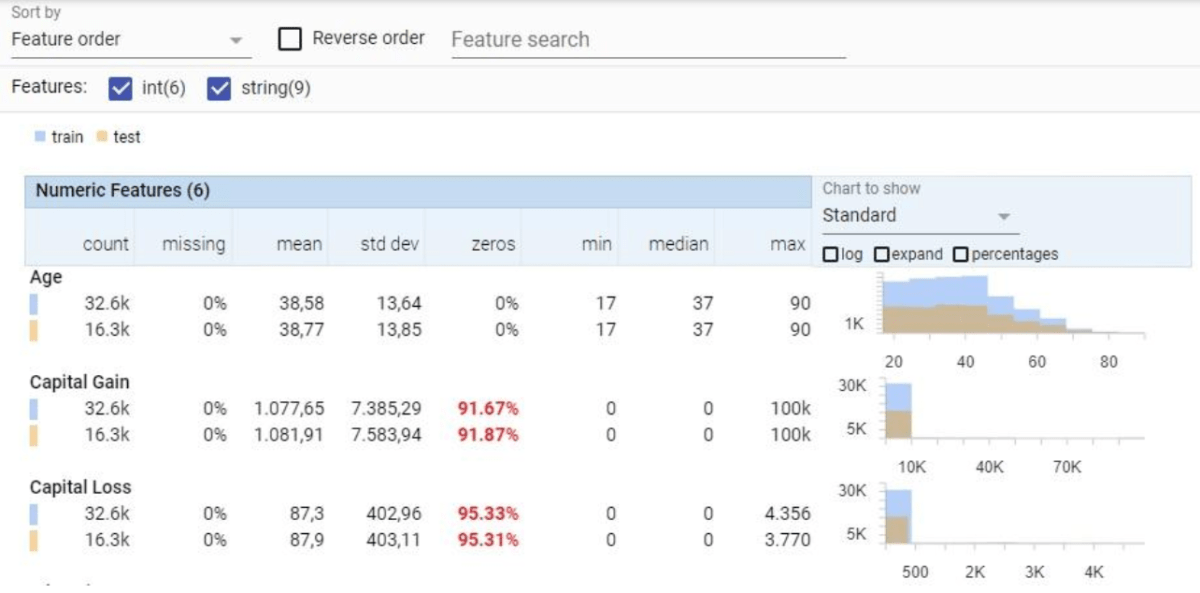
Let’s take a tumor-prediction model: evaluating it with Facets, we could notice that male patients are less likely to have a precise diagnosis than their female counterparts. How can we solve this? Just feed the model with more male patients’ data.
Another great tool to integrate Facets is What-if. It extends Facets with a more immediate visual interface and datapoint correlation. Also, it can compare different models’ performances, making very easy to choose which one is more suitable for our purpose. And last, but not least, What-if incorporates different Fairness-Testing tools that help us achieve fairness smoothly.
Finally, we have a more basic strategy to avoid bias so, let’s try it. After all, technology should be a service for all of us.
And remember, as Kate Crawford and Ryan Calo wrote in “There is a blind spot in AI research”:
AI is a cultural shift as much as a technical one. Autonomous systems are changing workplaces, streets and schools. We need to ensure that those changes are beneficial, before they are built further into the infrastructure of everyday life.



