
Ottimizza le prestazioni del tuo cluster con gli strumenti e le best practices consigliate da Aruba.
L’adozione di Kubernetes come piattaforma per l’orchestrazione dei container porta numerosi benefici, ma richiede anche soluzioni avanzate per monitorare e registrare attività e performance in ambienti distribuiti.

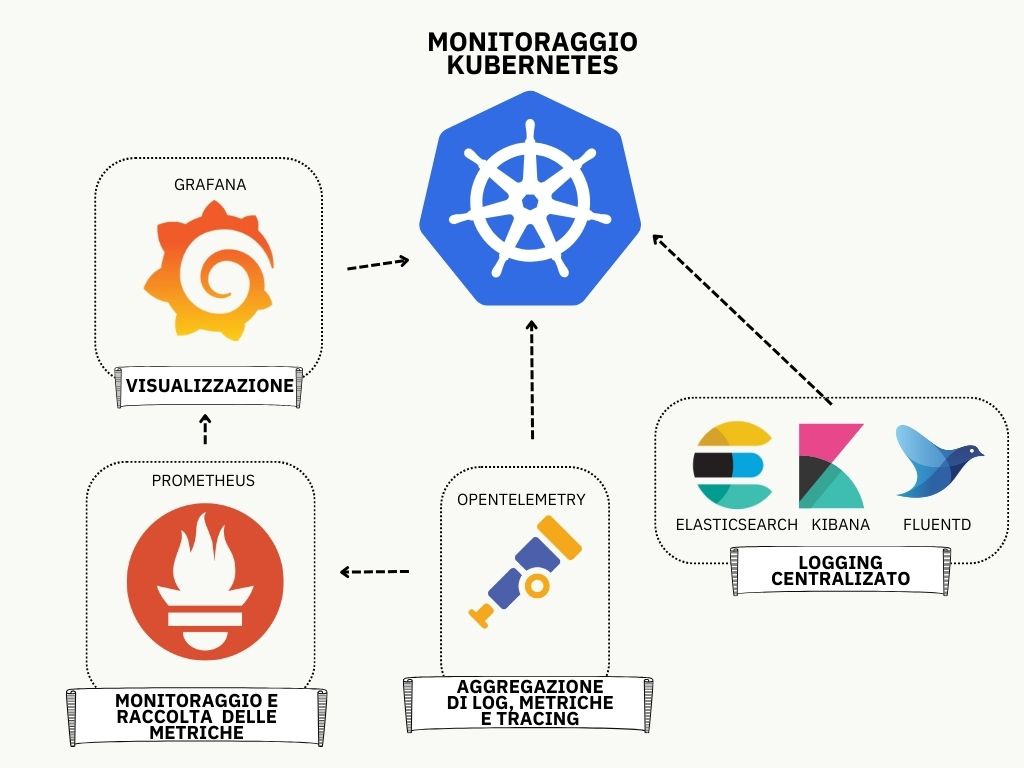
Questa guida ti mostrerà come ottenere un monitoraggio completo del tuo cluster Kubernetes, utilizzando Prometheus e la suite kube-prometheus per le metriche, OpenTelemetry per aggregare log, metriche e tracing, e altri strumenti chiave per massimizzare l’osservabilità.
1. Introduzione al monitoraggio in Kubernetes
Il monitoraggio in Kubernetes permette di raccogliere, analizzare e visualizzare dati fondamentali su prestazioni, errori e attività all’interno del cluster, offrendo informazioni essenziali per migliorare il funzionamento delle applicazioni e risolvere velocemente eventuali problemi.
Kubernetes, però, è un sistema molto dinamico: le repliche dei pod vengono create ed eliminate continuamente in base al carico di lavoro. Questo richiede un sistema di monitoraggio flessibile e scalabile, capace di:
- Adattarsi ai cambiamenti continui: Monitorare i pod, i nodi e il traffico di rete che cambiano spesso, mantenendo una visione chiara e aggiornata.
- Raccogliere metriche e log dettagliati: Andare oltre l’uso di risorse come CPU e memoria, includendo metriche più specifiche e centralizzando i log per avere un quadro completo.
- Prevenire problemi: Con il monitoraggio giusto, è possibile impostare alert e riconoscere subito comportamenti anomali o sovraccarichi, risolvendo i problemi prima che diventino gravi.
In sintesi, monitorare in maniera efficace un cluster Kubernetes aiuta a mantenere il sistema stabile, ottimizzare le risorse e rispondere rapidamente alle necessità operative.
2. Monitoraggio delle metriche con Prometheus
Prometheus è uno strumento per il monitoraggio delle metriche in Kubernetes, che permette di analizzare il comportamento del cluster in modo approfondito. In altre parole, il suo scopo è quello di raccogliere metriche dettagliate sui componenti di Kubernetes (pod, nodi, risorse) per ottenere una visione precisa della performance del sistema.
Per poter configurare questa soluzione, è necessario in primis installare e configurare il server Prometheus e l’Operator per Kubernetes. L’Operator facilita infatti la gestione e la configurazione di Prometheus all’interno del cluster.
Per farlo, bastano tre semplici comandi: il primo serve ad aggiungere il repository di Prometheus a quelli conosciuti dal cluster Kubernetes, il secondo ad aggiornare l’elenco dei package disponibili e il terzo per installare il chart all’interno del cluster.
$ helm repo add prometheus-community https://prometheus-community.github.io/helm-charts
$ helm repo update
$ helm install [RELEASE_NAME] prometheus-community/kube-prometheus-stack
Code language: JavaScript (javascript)Poi, è necessario configurare gli exporter per raccogliere le metriche dettagliate delle risorse di sistema, come CPU, memoria e altri indicatori critici di performance. In altre parole, un exporter è un agente che recupera tramite un metodo chiamato scraping le statistiche prodotte da un’applicazione nel formato utilizzato da quel sistema (ad esempio XML) interrogando gli endpoint HTTP esposti dall’applicazione e dai servizi in esecuzione nel cluster, per poi convertire tali statistiche in metriche che Prometheus può utilizzare e quindi esporre.
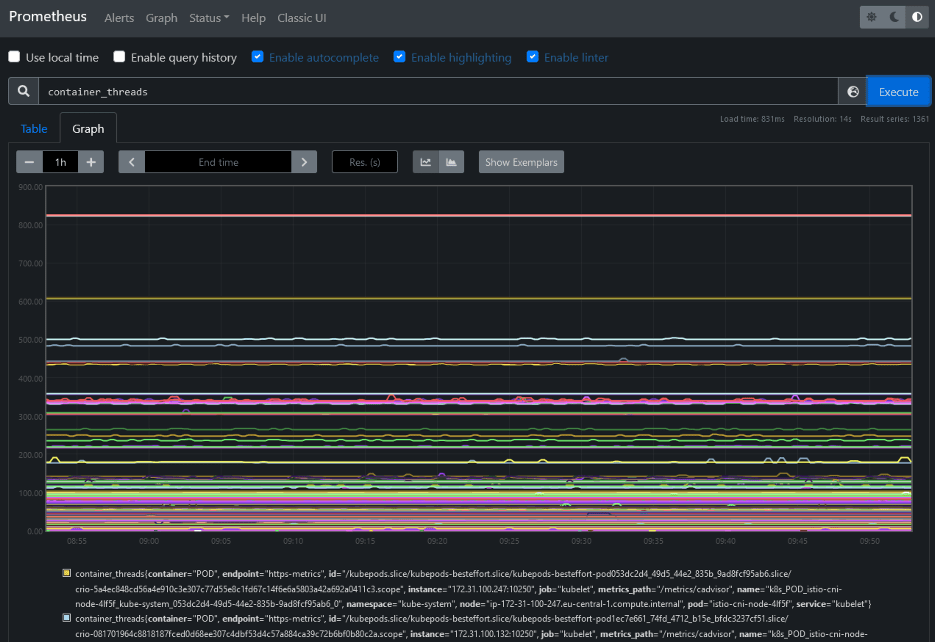
Uno dei vantaggi nell’utilizzo di Prometheus è quello di avere a disposizione dati completi e aggiornati in tempo reale, fondamentali per monitorare efficacemente un ambiente Kubernetes, senza dover interrogare i vari servizi manualmente: infatti, Prometheus può trovare automaticamente servizi e pod all’interno del cluster Kubernetes utilizzando le sue funzionalità di rilevamento dei servizi integrate. Ciò significa che quando vengono distribuiti o ridimensionati nuovi servizi, Prometheus può adattarsi per monitorarli.
Dando un’occhiata molto in superficie all’architettura, Prometheus ha tre componenti principali: un server, che raccoglie e memorizza le metriche, un server HTTP, il quale interagisce con il primo per estrarre le metriche salvate e un Alertmanager, che gestisce gli avvisi in base alle metriche raccolte da Prometheus. Solitamente poi, viene abbinato a Grafana, un tool che permette di mostrare queste metriche attraverso delle dashboard.
3. Visualizzazione delle metriche con Grafana
Una volta configurato Prometheus, installare Grafana ti permette di visualizzare i dati raccolti in dashboard personalizzate, semplificando l’analisi delle prestazioni.
Lo scopo è quello di offrire una visualizzazione intuitiva dei dati raccolti da Prometheus, con dashboard personalizzabili per monitorare in modo visivo le performance e lo stato del cluster.Per poter integrare Grafana e Prometheus, è necessario intanto installarlo, e i passaggi sono molto simili a quelli visti in precedenza: aggiungiamo il repository di Grafana all’interno del catalogo Helm del cluster, aggiorniamo e poi, a differenza di prima, creiamo un namespace chiamato monitoring (o come preferisci!) ad hoc per poter installare Grafana in maniera isolata rispetto ai restanti componenti. Una volta fatto, procediamo con l’ultimo comando, che installa Grafana all’interno del namespace appena creato:
$ helm repo add grafana https://grafana.github.io/helm-charts
$ helm repo update
$ kubectl create namespace monitoring
$ helm install [RELEASE_NAME] grafana/grafana --namespace monitoring
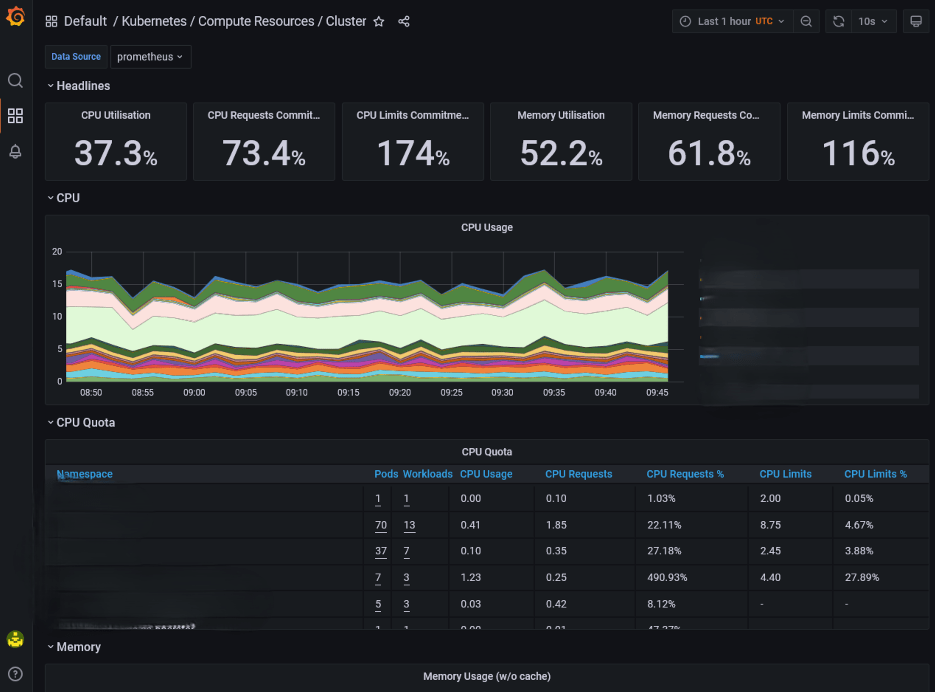
Code language: PHP (php)Una volta che l’installazione sarà completa, potrai configurare Prometheus come fonte dati (chiamato anche data source, nel gergo di questa tecnologia) e utilizzare Grafana per creare dashboard specifiche per monitorare sia l’infrastruttura (risorse di sistema, errori) sia le applicazioni, aggregando dati di performance per una visione d’insieme.Grafana consente infatti di comprendere e analizzare le metriche in modo semplice e immediato, ottimizzando così l’osservabilità del cluster, tramite delle dashboard interattive che, sfruttando dei widget, possono dare una visualizzazione chiara di ciò che avviene all’interno del cluster.
Esempio di Dashboard su Grafana
4. Aggregazione di log, metriche e tracing con OpenTelemetry
Oltre a quanto descritto prima, esiste OpenTelemetry: si tratta di un tool per l’osservabilità avanzata in Kubernetes, poiché permette di raccogliere log, metriche e tracing in un’unica soluzione integrata.
L’obiettivo è proprio l’aggregazione di metriche e log per una visione unificata del sistema, facilitando una gestione centralizzata e semplificando la diagnosi dei problemi.
Per configurarlo, possiamo affidarci sempre ad Helm e, indovina un po’? Ci basta eseguire i soliti passaggi, anche se l’architettura di questo strumento è leggermente più complessa: per questo, oltre ad aggiungere il repository, dovremo prima andare a valutare quale configurazione faccia più al caso nostro, sfruttando il file values.yaml. Un esempio di partenza è quello presente nella documentazione: https://opentelemetry.io/docs/kubernetes/getting-started
Quando avremo pronto il file, potremo eseguire il secondo comando, che procede con l’installazione del DaemonSet all’interno del cluster:
$ helm repo add open-telemetry https://open-telemetry.github.io/opentelemetry-helm-charts
$ helm install otel-collector open-telemetry/opentelemetry-collector –values [MY_FILE]
Quando l’installazione sarà completata, dovrai procedere alla configurazione di Prometheus come receiver dei dati raccolti da OpenTelemetry per poterli visualizzare nelle tue dashboard su Grafana!
5. Logging centralizzato con la stack EFK (Elasticsearch, Fluentd, Kibana)
Per una gestione avanzata dei log, la stack EFK permette di centralizzare e analizzare i log provenienti dai vari componenti del cluster, così da facilitare la risoluzione dei problemi e l’analisi approfondita degli eventi.
Questa combo permette di raccogliere i log del cluster, indicizzarli e gestirli in modo centralizzato, migliorando l’osservabilità e la capacità di diagnosi. Sarà infatti FluentD a raccogliere i log grazie ad un DaemonSet che prenderà tutti i vari output dai Pod del cluster, li invierà ad ElasticSearch per indicizzarli e persisterli e poi questi verranno messi a disposizione per essere visualizzati e filtrati tramite Kibana, che offre una dashboard web interattiva.
La configurazione non è complessa, ma richiede qualche passaggio in più: bisogna infatti installare e configurare Elasticsearch per l’archiviazione dei log, Fluentd per la raccolta e la distribuzione dei log e Kibana per la visualizzazione dei dati. Per vedere quali sono gli step necessari, puoi seguire la documentazione ufficiale che trovi in questa pagina.
Perché usare questo stack? Con EFK, puoi ottenere una gestione dei log affidabile e automatizzata, adottando strategie come la compressione dei log, nonché la ricerca e la visualizzazione degli stessi, per garantire un’archiviazione ed una gestione ottimale anche in produzione.
Conclusioni
Implementare un sistema di monitoraggio avanzato in Kubernetes, utilizzando Prometheus, Grafana, OpenTelemetry e lo stack EFK, offre una serie di benefici fondamentali per la gestione e l’ottimizzazione del cluster:
- Maggiore affidabilità e stabilità: Monitorando in tempo reale ogni componente, puoi identificare e risolvere rapidamente anomalie e problemi, garantendo una maggiore stabilità operativa.
- Riduzione dei tempi di diagnosi: Con strumenti avanzati di tracing e logging, è possibile individuare velocemente i colli di bottiglia e le cause degli errori, riducendo i tempi di risoluzione e minimizzando l’impatto sui servizi.
- Ottimizzazione delle risorse: Grazie alla visibilità sulle risorse utilizzate (come CPU e memoria), puoi rivedere l’allocazione delle risorse, riducendo i costi e migliorando l’efficienza del sistema.
- Miglioramento continuo delle prestazioni: Il monitoraggio costante permette di individuare trend e inefficienze, permettendo miglioramenti incrementali e continui per le applicazioni e i servizi.
- Facilità di scaling: Un monitoraggio avanzato fornisce una base solida per pianificare e gestire il scaling del cluster, adattandosi facilmente a carichi di lavoro variabili e mantenendo le performance sotto controllo.
Adottare questi strumenti di monitoraggio ti offre una visione approfondita delle prestazioni, della stabilità e dei flussi applicativi del tuo cluster Kubernetes, garantendo un ambiente ottimizzato e resiliente.




