
Il termine Intelligenza Artificiale fu coniato nel 1956 da John McCarthy, uno dei padri fondatori di questa disciplina, ed è una operazione di marketing fenomenale, se questo brand continua ancora oggi a catturare l’attenzione di utenti e consumatori! Ma cosa intendevano McCarthy e i suoi colleghi col termine “Intelligenza Artificiale”? Abbiamo visto nell’articolo “Come l’intelligenza artificiale si comporta nell’imitazione del linguaggio” che nientemeno che Alan Turing aveva tracciato una strada per le macchine che apprendono, anche in termini di modelli linguistici. Ma quella strada forse sembrava troppo impervia e, per i suoi primi decenni di vita, l’AI ne ha presa un’altra.
McCarthy è noto per essere anche l’inventore del Lisp, il primo linguaggio di programmazione funzionale, che vive ancora oggi incarnato in Common Lisp e Clojure: l’idea del Lisp era rivoluzionaria, al punto che McCarthy lo aveva inventato non come linguaggio di programmazione ma come sistema per esprimere algoritmi con carta e penna: fu con sua sorpresa che, nel 1959, Steve Russell implementò un interprete Lisp su un computer IBM 704.
L’idea di McCarthy era che la nostra mente ragiona su simboli che manipola per generare risposte a stimoli e il Lisp, come altri linguaggi dell’epoca quali IPL, processava simboli e liste di simboli. Questa idea, che ha influenzato i primi 40 anni dell’AI, era essenzialmente incompatibile con le idee di Turing che, per ironia della sorte, nel 1936 aveva fondato la teoria della calcolabilità insieme ad Alonzo Church, l’inventore del lambda-calcolo dal quale il Lisp prendeva ispirazione!
Per realizzare questa idea, si pensò di codificare database di regole sintattiche, grammaticali e semantiche e scrivere programmi che potessero applicare le regole alle frasi che avevano in input per generare delle frasi in output. Il tipico schema di questi programmi in voga negli anni ’60 e ’70 è illustrato nella Figura 1.
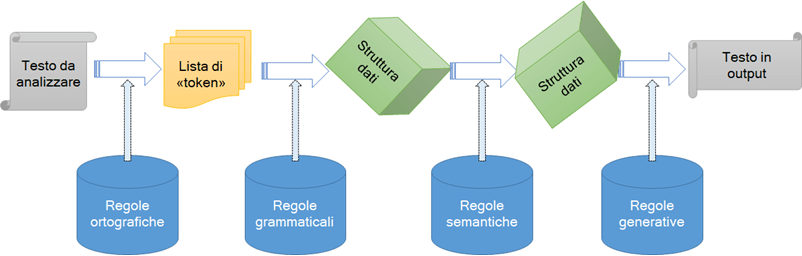
Come si vede, il funzionamento del sistema è basato su database di regole, codificate in vari modi, che vengono applicate a ogni passaggio: prima per trasformare il testo in token, poi in una struttura interna che viene manipolata e quindi riconvertita in testo per la risposta. Queste regole erano generalmente statiche, sebbene le basi di dati potessero essere incrementate nel tempo, inserendo nuove regole.
Un esempio famosissimo e molto semplice di questo schema è il programma ELIZA, scritto dal matematico Joseph Weizenbaum nel 1966. ELIZA era un chatbot che simulava uno psichiatra: ecco un brano di sessione (tradotta in italiano: le risposte del computer in maiuscolo):
Gli uomini sono tutti uguali.
IN CHE SENSO
Ci stanno sempre a infastidire per un motivo o per l’altro.
PUOI PENSARE A UN ESEMPIO SPECIFICO
Be’, il mio fidanzato mi ha fatto venire qui
IL TUO FIDANZATO TI HA FATTO VENIRE QUI
Dice che sono depressa quasi tutto il tempo.
MI SPIACE SAPERE CHE SEI DEPRESSA
È vero. Sono infelice
PENSI CHE VENIRE QUI TI AIUTERÀ A NON ESSERE INFELICE
ELIZA lavorava direttamente sulla lista dei token della frase inserita dal paziente: confrontando con un database di pattern, ELIZA trovava tutti i match della frase con i pattern che conosceva, ne sceglieva uno e operava la trasformazione associata. Per esempio, il pattern *mio padre beve* ha match con una frase che al suo interno contenga le parole “mio padre beve”. Se il match avviene, si genera una risposta “PARLAMI DI TUO PADRE” (naturalmente la tokenizzazione esclude i segni di interpunzione e normalizza le parole in modo da poter essere confrontate).
Oggi ELIZA si scriverebbe in poche righe di Python, usando un DB (o anche un semplice file JSON) per contenere i pattern. Questo approccio ha anche il vantaggio di poter usare diversi DB di pattern con lo stesso programma per ottenere chatbot di tipo diverso. Ma i programmi come ELIZA, o SHRLDU (più sofisticato ma che usa gli stessi princìpi), fallivano miseramente su conversazioni generiche: per questo, nessuna di queste tecniche aprì un mercato per i chatbot. Infatti le regole per metterli in grado di sostenere una qualsiasi conversazione erano troppe per la memoria dei computer dell’epoca, per la loro velocità e soprattutto per essere scritte in dettaglio da esperti umani (linguisti, logici, psicologi, ecc.).
La crisi di questo paradigma di AI avvenne alla fine degli anni ’80, il secondo inverno dell’AI, ma i sintomi c’erano già da tempo: per esempio, già alla fine degli anni ’60 Frederick Jelinek, a capo dei progetti linguistici della IBM, aveva notato che introducendo metodi probabilistici i risultati erano molto migliori che con le descrizioni logico-linguistiche delle grammatiche tanto da dire, a un giornalista, la celebre frase: “ogni volta che licenzio un linguista le performance del riconoscitore di linguaggio migliorano”.
In effetti se in teoria la linguistica consentiva di codificare tutte le regole di una lingua, in pratica il compito era proibitivo: un po’ come voler applicare le leggi della dinamica di newtoniana a un gas; ci sono talmente tante particelle in un gas (dell’ordine di 1023) che è impossibile applicare le leggi di Newton a ciascuna particella e si è costretti a ricorrere alla meccanica statistica. Uno spostamento di paradigma analogo è avvenuto fra fine XX e inizio XXI secolo nell’AI: si è sostituito l’impero delle regole, in particolare delle regole grammaticali nei modelli linguistici, con una repubblica delle parole. Rinunciando all’approccio top-down, che parte dal generale (una grammatica universale che nessuno sa definire completamente), si è preso un approccio bottom-up, che parte dall’unica cosa che possediamo di un testo e che sia assimilabile a un dato: le parole che lo compongono nell’ordine in cui si presentano.
I modelli linguistici contemporanei sono in un certo senso l’analogo della meccanica statistica per i testi disponibili sul Web, formati da un numero sterminato di parole delle quali si vanno ad analizzare le proprietà statistiche, per esempio in quale frase è più probabile che una certa parola occorra, o quale frase è più probabile che contenga una parola data ecc.
Come scrivono Halevy, Norvig e Pereira in un celebre articolo del 2009 (The Unreasonable Effectiveness of Data):
Per applicazioni al linguaggio naturale, fidate nel fatto che la lingua umana ha già fatto evolvere le parole per i concetti importanti. Procedete legando le parole che sono già nel testo piuttosto che inventare nuovi concetti o cluster di parole.
Questi suggerimenti sono stati colti dalle ultime generazioni di modelli linguistici, a partire dagli algoritmi di word embedding che usano reti neurali (non profonde) per trasformare le parole di un corpus di testi in punti di uno spazio cartesiano di una certa dimensione (anche migliaia) per proseguire con gli attuali transformers che comprimono e decomprimono l’informazione statistica contenuta in milioni di testi, codificandola in un numero astronomico (centinaia di miliardi!) di parametri di reti neurali profonde.
Ciò che accomuna questi software è che l’addestramento di questi modelli consiste sostanzialmente nel renderli sempre più bravi a prevedere parole e sequenze di parole che possono figurare dopo o in mezzo ad altre. Un esempio semplicissimo: la frase il X miagola è facilmente “risolvibile” con X = gatto, questo in quanto la probabilità che il verbo “miagolare” sia associato a un gatto è praticamente il 100%. Invece la frase Il mio X ha Y tutta la notte richiede una analisi statistica più complessa, che potrebbe individuare coppie (X,Y) come (cane, abbaiato), (gatto, miagolato), (tacchino, gloglottato) ma anche (bambino, pianto), e così via.
Scrivere una regola generale per prevedere questi casi è quasi impossibile, mentre analizzare tantissimi testi e annotare le coppie che compaiono nel contesto di quella frase e desumere una distribuzione probabilistica congiunta per X e Y è un mero calcolo che i veloci computer moderni, riescono a fare. Questo nuovo corso dei modelli linguistici riprende le idee di Turing: non costruire sistemi con regole preconfezionate ma che imparano regole sulla base di esempi, addestrarli con algoritmi di apprendimento numerici e usare in modo essenziale procedimenti casuali.
La transizione dalla logica alla statistica, dalla regola generale deduttiva al calcolo probabilistico induttivo è stata la mossa vincente dell’AI contemporanea: tornare sulla strada indicata da Turing.



