
I modelli linguistici di grandi dimensioni (LLM), come GPT-3 e GPT-4, sono potenti strumenti di generazione del linguaggio naturale. Tuttavia, uno dei loro principali limiti è l’incapacità di accedere a informazioni aggiornate e accurate, il che può portare a risposte imprecise o “allucinate”. La Retrieval-Augmented Generation (RAG) rappresenta una soluzione a questo problema, combinando la generazione del linguaggio naturale con il recupero di informazioni da una base di conoscenza esterna. Questo approccio non solo migliora l’accuratezza delle risposte, ma consente anche di accedere a informazioni aggiornate e verificate. In questo articolo, esploreremo come creare da zero agenti LLM per RAG e come costruire un RAG personalizzato con LangChain per migliorare l’esplorazione della documentazione.

Cos’è RAG e perché è importante
RAG, o Retrieval-Augmented Generation, è un approccio che combina il recupero di informazioni con la generazione di testo. In un sistema RAG:
1. Una query viene utilizzata per recuperare documenti rilevanti da una knowledge base.
2. Questi documenti vengono quindi inseriti in un modello linguistico insieme alla query originale.
3. Il modello genera una risposta basata sia sulla query che sulle informazioni recuperate.
I vantaggi di RAG:
- ancorando le risposte nelle informazioni recuperate, RAG riduce le allucinazioni e migliora l’accuratezza dei fatti.
- la base di conoscenza può essere aggiornata regolarmente, consentendo al sistema di accedere alle informazioni attuali.
- il sistema può fornire fonti per le sue informazioni, aumentando la fiducia e consentendo il controllo dei fatti.
Comprendere gli agenti LLM
Gli agenti LLM sono ideali per affrontare problemi complessi senza una risposta semplice. Essi combinano analisi approfondita dei dati, pianificazione strategica, recupero dei dati e capacità di apprendere dalle azioni passate per risolvere problemi complessi. I componenti degli agenti LLM sono:
- Agente/cervello: il modello linguistico che elabora e comprende il linguaggio.
- Pianificazione: capacità di ragionare, suddividere i compiti e sviluppare piani specifici.
- Memorie: conserva le registrazioni delle interazioni passate e impara da esse.
- Uso dello strumento: integra varie risorse per eseguire attività.
Costruire un RAG personalizzato con LangChain per esplorare i documenti
Per cercare, esplorare, elaborare e gestire efficacemente la documentazione, possiamo creare un RAG personalizzato con LangChain che consente di recuperare e generare risposte basate su documenti specifici. LangChain, framework per facilitare lo sviluppo e l’implementazione di applicazioni di intelligenza artificiale (AI), offre una serie di librerie e moduli che permettono agli sviluppatori di integrare facilmente capacità di ricerca, elaborazione e generazione del linguaggio nei loro progetti.
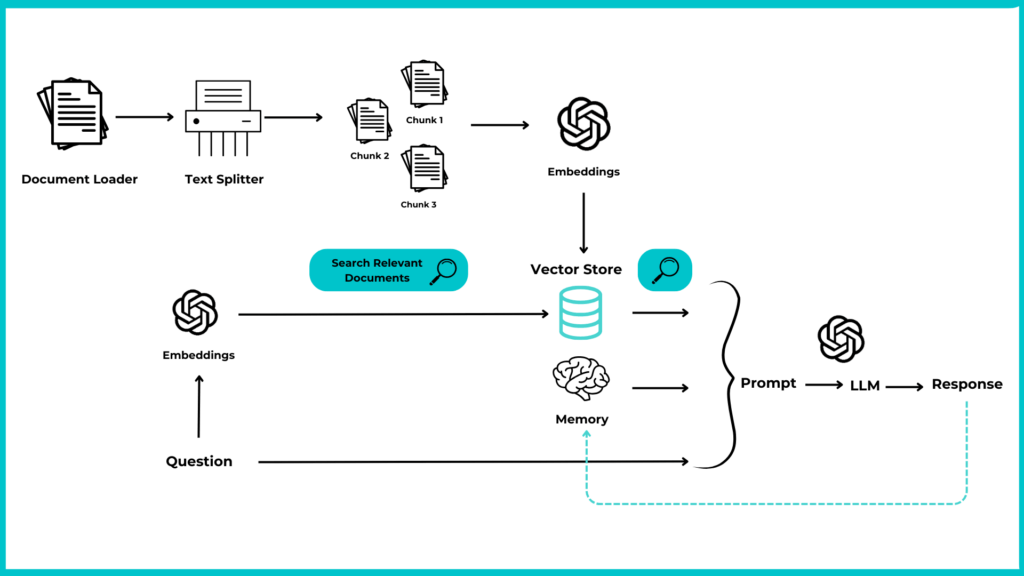
Document Loader
Per interagire con i nostri dati, è fondamentale caricarli in un formato che ne consenta l’elaborazione. A tale scopo, utilizziamo i Document Loader di LangChain, che semplificano l’accesso e la conversione dei dati provenienti da una vasta gamma di formati e fonti.
Questi Loader sono progettati per gestire le specificità dell’accesso ai dati da diverse sorgenti, tra cui:
- Siti web
- Database
- YouTube
- Hacker News
- Figma, Notion, o servizi come Stripe
Per ulteriori dettagli, si consiglia di consultare la documentazione ufficiale di LangChain.
UnstructuredMarkdownLoader
Per lavorare con documenti in formato Markdown, facciamo affidamento su UnstructuredMarkdownLoader. Implementiamo una classe DocumentManager per caricare efficacemente una directory contenente i documenti Markdown:
from langchain_community.document_loaders import DirectoryLoader
from langchain_community.document_loaders import UnstructuredMarkdownLoader
class DocumentManager:
def __init__(self, directory_path, glob_pattern="./*.md"):
self.directory_path = directory_path
self.glob_pattern = glob_pattern
self.documents = []
self.all_sections = []
def load_documents(self): loader = DirectoryLoader(self.directory_path,
glob=self.glob_pattern, show_progress=True,
loader_cls=UnstructuredMarkdownLoader)
self.documents = loader.load()La classe DocumentManager permette il caricamento di documenti Markdown da una directory specificata. Attraverso l’uso di DirectoryLoader e UnstructuredMarkdownLoader, la classe è in grado di:
- Accedere alla directory: individua la directory dove si trovano i documenti Markdown.
- Filtrare i file: utilizza il
glob_patternfornito (di default, tutti i file.md) per selezionare i documenti da caricare. - Caricare i documenti: importa i file filtrati per l’elaborazione successiva.
Text Splitters
I Text Splitters sono cruciali per l’elaborazione dei testi, poiché consentono di dividere documenti complessi in parti più gestibili. La sfida principale in questo processo è mantenere le relazioni semantiche tra i segmenti, evitando di perdere connessioni significative tra i blocchi.
LangChain offre diverse soluzioni per affrontare questa sfida. Nel caso di documenti in formato Markdown, utilizzeremo il MarkdownHeaderTextSplitter. Per ulteriori dettagli sulle diverse tipologie di splitter disponibili, consultate la documentazione ufficiale di LangChain.
# Class DocumentManager
from langchain.text_splitter import MarkdownHeaderTextSplitter
def split_documents(self):
headers_to_split_on = [("#", "Header 1"),
("##", "Header 2"),
("###", "Header 3"),
("####", "Header 4")]
text_splitter = MarkdownHeaderTextSplitter(headers_to_split_on=headers_to_split_on)
for doc in self.documents:
sections = text_splitter.split_text(doc.page_content)
self.all_sections.extend(sections)Code language: PHP (php)Embedding e Vector Store
Dopo aver suddiviso i documenti in frammenti più piccoli tramite il text splitting, il passo successivo consiste nel trasformare questi frammenti in una forma facilmente interrogabile e comparabile. È qui che entrano in gioco gli embedding e i database vettoriali. Utilizzando OpenAIEmbeddings, convertiamo ciascun frammento di testo in un embedding vettoriale. Gli embedding sono rappresentazioni numeriche dense che catturano la semantica del testo; frammenti con significati simili risultano in vettori simili nello spazio degli embedding. Questo consente operazioni sofisticate come la ricerca semantica e il clustering tematico.
Per memorizzare e gestire efficacemente questi embedding, utilizziamo Chroma, un database vettoriale open-source. Ho scelto Chroma per la sua semplicità di implementazione, permettendo la creazione di un vector store permanente direttamente nella cartella del progetto. Questo elimina la necessità di configurazioni complesse o dell’uso di container Docker.
Con Chroma possiamo organizzare gli embedding in modo che siano rapidamente recuperabili attraverso query basate sulla similarità. Questo approccio trasforma una collezione di testi in un database interrogabile, dove è possibile trovare documenti o frammenti rilevanti per una determinata query confrontando gli embedding della query con quelli presenti nell’archivio.
LangChain supporta vari vector store. Per una lista completa, consultate la documentazione ufficiale di LangChain.
Importiamo OpenAIEmbeddings e Chroma in una classe EmbeddingManager cosi da automatizzare il processo di creazione e memorizzazione degli embedding. Inizializziamo EmbeddingManager con i frammenti di testo e un path per la persistenza dei dati. Invocando il metodo create_and_persist_embeddings, ogni frammento viene trasformato in un embedding attraverso OpenAIEmbeddings e memorizzato in Chroma.
from langchain_openai import OpenAIEmbeddings
from langchain_community.vectorstores import Chroma
class EmbeddingManager:
def __init__(self, all_sections, persist_directory='db'):
self.all_sections = all_sections
self.persist_directory = persist_directory
self.vectordb = None
# Method to create and persist embeddings
def create_and_persist_embeddings(self):
# Creating an instance of OpenAIEmbeddings
embedding = OpenAIEmbeddings()
# Creating an instance of Chroma with the sections and the embeddings
self.vectordb = Chroma.from_documents(documents=self.all_sections,
embedding=embedding,
persist_directory=self.persist_directory)
# Persisting the embeddings
self.vectordb.persist()

Retriever
Il retriver rappresenta il nucleo del nostro RAG (Retrieval Augmented Generation). Questo strumento è essenziale per individuare e recuperare i documenti più rilevanti in risposta a una query specifica, sfruttando il vector store Chroma che contiene gli embedding dei documenti. La ricerca si basa sulla similarità degli embedding, confrontando quelli della query con quelli dei documenti per identificare i più pertinenti al tema della domanda.
Quando dobbiamo rispondere a domande basate sui nostri documenti, la sfida principale consiste spesso nel recuperare efficacemente le informazioni rilevanti. Un recupero inefficace può facilmente portare a risposte inesatte o incomplete.
Noi impiegheremo la Conversational Retrieval Chain. Questa catena non si limita a recuperare i documenti più pertinenti rispetto all’ultima query, ma sfrutta anche il contesto della conversazione per migliorare la qualità delle risposte fornite. Il processo si articola in tre fasi principali:
- Riformulazione della query: la catena modifica la query iniziale per includere il contesto della conversazione, consentendo al sistema di “ricordare” le richieste precedenti e di formulare risposte più precise.
- Recupero dei documenti rilevanti: utilizzando un ‘retriever’, la catena cerca documenti pertinenti alla query riformulata. Questo recupero si basa sulla similarità degli embedding, identificando i documenti che meglio corrispondono al tema della domanda.
- Generazione della risposta: infine, la catena chiede a un Large Language Model (LLM) di generare una risposta basata sui documenti recuperati e sulla query riformulata. Questo passaggio combina il contesto dei documenti rilevanti con la domanda per produrre una risposta coerente e informativa.
from langchain_openai import OpenAI
from dotenv import load_dotenv
from langchain.chains import ConversationalRetrievalChain
import os
load_dotenv()
# Set the OpenAI API key from the environment variable
os.environ["OPENAI_API_KEY"] = os.getenv("OPENAI_API_KEY")
class ConversationalRetrievalAgent:
# Initialize the ConversationalRetrievalAgent with a vector
database and a temperature for the OpenAI model
def __init__(self, vectordb, temperature=0.5):
self.vectordb = vectordb
self.llm = OpenAI(temperature=temperature)
self.chat_history = []
# Method to get the chat history as a string
def get_chat_history(self, inputs):
res = []
for human, ai in inputs:
res.append(f"Human:{human}\nAI:{ai}")
return "\n".join(res)
# Method to set up the bot
def setup_bot(self):
# Create a retriever from the vector database
retriever = self.vectordb.as_retriever(search_kwargs={"k": 4})
# Create a ConversationalRetrievalChain from the OpenAI model and the retriever
self.bot = ConversationalRetrievalChain.from_llm(
self.llm, retriever, return_source_documents=True,
get_chat_history=self.get_chat_history
)Prompt and templates
Sebbene il nostro ConversationalRetrievalChain faccia già uso della cronologia delle chat, ho scelto di implementare un ulteriore livello di personalizzazione attraverso un sistema di prompt e template personalizzabile. Questa decisione mira ad ottimizzare l’interazione con il nostro modello e di migliorare ulteriormente la pertinenza e l’accuratezza delle risposte fornite.
# Class ConversationalRetrievalAgent:
def generate_prompt(self, question):
if not self.chat_history:
# If it is the first question, use a specific template without
# previous conversation context
prompt = f"You are an assistant for question-answering tasks.
Use the following pieces of retrieved context to answer the question.
If you don't know the answer, just say that you don't know.
\nQuestion: {question}\nContext: \nAnswer:"
else:
# If it is the first question, use a specific template without
# previous conversation context
context_entries = [f"Question: {q}\nAnswer: {a}" for q, a in self.chat_history[-3:]]
context = "\n\n".join(context_entries)
prompt = f"Using the context provided by recent conversations,
answer the new question in a concise and informative.
Limit your answer to a maximum of three sentences.
\n\nContext of recent conversations:\n{context}\n\nNew question: {question}\n\Answer:"
return prompt
Code language: PHP (php)Conversazione
In fine implementeremo il metodo ask_question, all’interno del nostro ConversationalRetrievalAgent. Questo metodo incapsula il processo attraverso il quale si riceve una domanda, si elabora la richiesta, e fornisce una risposta pertinente e informata.
# Class ConversationalRetrievalAgent
def ask_question(self, query):
prompt = self.generate_prompt(query)
result = self.bot.invoke({"question": prompt, "chat_history": self.chat_history})
self.chat_history.append((query, result["answer"]))
return result["answer"]Code language: PHP (php)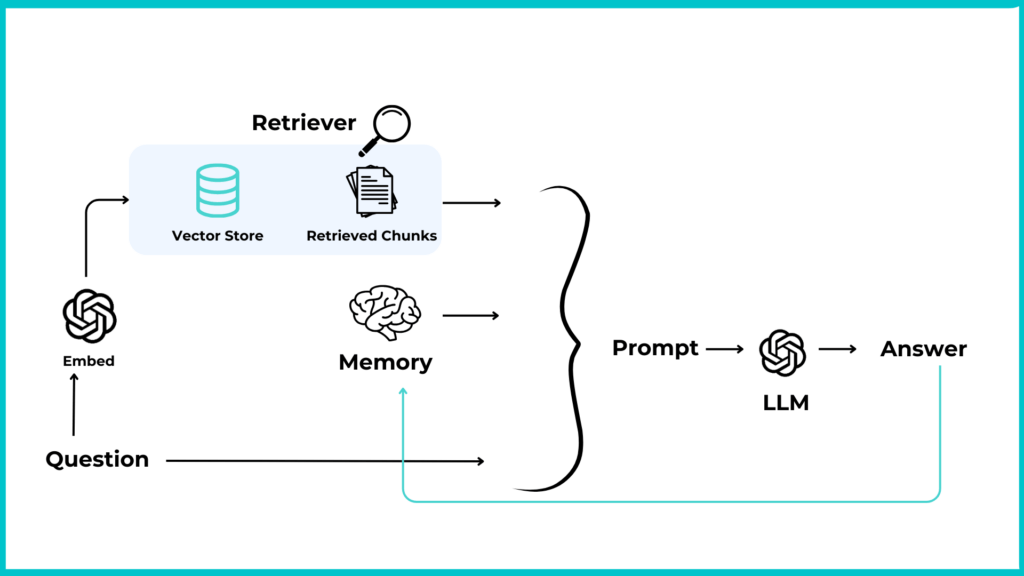
Orchestrazione del sistema RAG
Ora creeremo un orchestratore con LangChain per il nostro sistema RAG personalizzato, collegando i componenti fondamentali in un flusso operativo coeso:
- Inizializzazione del DocumentManager: questo componente carica e suddivide i documenti Markdown presenti nella directory specificata.
- Utilizzo dell’EmbeddingManager: questo modulo prende i frammenti di testo generati e crea rappresentazioni vettoriali (embeddings) per ciascuno, memorizzandole in un database vettoriale.
- Attivazione del ConversationalRetrievalAgent: questo agente utilizza gli embeddings per alimentare una catena di recupero conversazionale, consentendo di rispondere a domande specifiche sfruttando il contesto fornito dai documenti.
from DocumentManager import DocumentManager
from EmbeddingManager import EmbeddingManager
from ConversationalRetrievalAgent import ConversationalRetrievalAgent
def main():
# Initialising and loading documents
doc_manager = DocumentManager('./marckdown_folder')
doc_manager.load_documents()
doc_manager.split_documents()
# Creation and persistence of embeddings
embed_manager = EmbeddingManager(doc_manager.all_sections)
embed_manager.create_and_persist_embeddings()
# Setup and use of conversation bots
bot = ConversationalRetrievalAgent(embed_manager.vectordb)
bot.setup_bot()
print(bot.ask_question("Question one"))
print(bot.ask_question("Question two"))
print(bot.ask_question("Question three"))
if __name__ == "__main__":
main()Code language: PHP (php)RAG e LangChain: Conclusioni
Costruire agenti LLM per RAG è un processo che va dall’implementazione di semplici pipeline di recupero e generazione alla creazione di sofisticati agenti multi-funzione. Utilizzando tecniche RAG con LangChain, è possibile migliorare notevolmente l’accuratezza e la pertinenza delle risposte generate. L’approccio modulare consente di espandere e ottimizzare continuamente il sistema, adattandolo a esigenze sempre nuove e complesse. Con LangChain, possiamo creare RAG personalizzati per migliorare l’esplorazione della documentazione, fornendo risposte accurate e basate su fonti verificabili.
Andrea Nuzzo – Software Developer @Seacom
Seacom – Società Benefit appartenente al gruppo ITWay e co – fondatore di RIOS (Rete Italiana Open Source), è un’azienda specializzata in consulenza e formazione su prodotti open source per aziende di livello Enterprise, enti e pubbliche amministrazioni.
Scopri di più su Seacom su: https://seacom.it
