
Chiunque abbia sostenuto una conversazione con un chat basato su LLM, da ChatGPT ai più recenti Bard e chi più ne ha più ne metta, sarà rimasto sorpreso non dalla capacità di generare frasi in una lingua umana sintatticamente corrette e semanticamente sensate, ma soprattutto dal fatto di riuscire a comprendere la nostra richiesta e provare a soddisfarla.
Abbiamo veramente l’impressione di parlare con qualcuno che si sia letto tutte le pagine Web di questo mondo e le riesca a consultare all’istante per risponderci a tono: la capacità di generare una risposta appropriata alla domanda che abbiamo fatto aumenta con la cura e la tecnica giuste per la composizione del prompt con il quale formuliamo la domanda.

Per esempio, se il nostro scopo è ottenere informazioni affidabili, come uno snippet che vogliamo integrare in un nostro software, dovremo essere precisi nel prompt e aiutare l’AI a produrre quel che vogliamo, sapendo quali sono le informazioni che ha a disposizione e che modo ha di estrarre contenuto dal nostro prompt. Viceversa, se vogliamo farla fallire o rispondere in modo “allucinato”, scriveremo dei prompt stravaganti e ambigui, magari inserendo informazioni false e quindi depistando e confondendo il nostro interlocutore.
In ogni caso è difficile non pensare che il LLM “capisca” o “comprenda” quel che stiamo chiedendo, altrimenti come farebbe a rispondere? Ma è veramente così?
Le intelligenze artificiali capiscono?
I verbi “capire”, “comprendere”, “conoscere” come pure i più impegnativi sostantivi “intelligenza” e “coscienza” che talvolta sentiamo usare riferendosi alle AI, sono in realtà emersi nelle nostre lingue per riferirsi agli esseri umani. In tempi recenti abbiamo esteso, per forza di cose, l’uso di questi termini anche ad altre creature viventi: chi ha un animale domestico ovviamente afferma che questo capisce una richiesta, comprende un comportamento, conosce i luoghi della casa, ed è largamente diffusa l’idea che cani e gatti siano intelligenti e coscienti, sebbene non come noi.
Applicare a un software queste parole può invece essere fonte di fraintendimenti. In fondo, un LLM è semplicemente un software interpolatore di distribuzioni di probabilità di parole, che per lui sono in realtà numeri: è un enorme e complesso algoritmo numerico che viene ottimizzato in modo da generare sequenze di numeri e poi parole che noi possiamo interpretare come frasi di senso compiuto che si agganciano alle nostre domande.
Il meccanismo è ben diverso da quello di ELIZA, il “bot psichiatrico” di 60 anni fa che abbiamo incontrato nell’articolo precedente “L’evoluzione dei modelli linguistici: dalle regole alle parole”: laddove quello presupponeva una base di dati di regole che erano associate a trasformazioni del testo cablate nel DB, i LLM si addestrano ruminando quantità spaventose di testi per tracciare complesse relazioni probabilistiche fra le parole e le sequenze di parole di questi testi e per produrre altrettante sequenze che poi, riconvertite da numeri nelle parole corrispondenti, compongono un testo che l’interlocutore umano interpreta.
L’idea che il significato sia proiettato dagli umani e non intrinseco nell’elaborazione delle AI possiamo farla risalire al filosofo statunitense John Searle nel 1980: quest’ultimo, personaggio per altri aspetti purtroppo controverso, ha elaborato l’idea che i programmi di AI volti a imitare il linguaggio, e le AI in generale, non siano che dei “copiaincollatori” estremamente efficienti, con una gran memoria e una gran velocità, ma pur sempre programmati per trasformare informazioni simboliche trattate, per così dire, sintatticamente, senza nessuna ulteriore informazione su un possibile significato.
Per mostrarlo, Searle immagina una “stanza cinese”: la stanza è chiusa e al suo interno c’è una persona che non conosce il cinese; come nel test di Turing, questa persona comunica con l’esterno attraverso fogli scritti o stampati.

Alla persona dentro la stanza vengono date in input sequenze di caratteri cinesi, e lei ha a disposizione delle regole che spiegano come, da una sequenza di simboli, produrne un’altra: per esempio se un tale carattere è seguito da un tal’altro carattere allora emetti questa sequenza. Supponiamo che l’insieme delle regole possa essere enorme, ma finito ovviamente, e non poniamoci limiti sul tempo a disposizione (e sulla incapacità di annoiarsi) della persona chiusa nella stanza.
Ovviamente Searle aveva in mente le AI della sua epoca che, come abbiamo visto nel precedente articolo [link], erano pattern matcher di regole cui erano associate delle azioni. Ma, a ben vedere, un LLM prende in input sequenze di parole e, usando un algoritmo dato dalla rete neurale complesso a piacere con centinaia di miliardi di parametri, le rielabora in una sequenza di output. Infatti c’è chi sostiene che ChatGPT sia null’altro che una stanza cinese (https://arxiv.org/abs/2304.12411).
Ora, la persona nella stanza cinese che compie questa faticosa e lunghissima operazione di copiaincolla basata su regole, per quanto complesse e intricate, certamente non conosce il cinese, si limita appunto a manipolare sequenze di simboli che per lui non hanno significato alcuno, a priori non potrebbe nemmeno sapere che corrispondono a dei suoni!
Ma, dall’esterno, una persona che legga il cinese e che veda introdurre un testo, per esempio una domanda, all’interno della stanza, poi ne veda uscire la risposta e leggendola comprenda l’attinenza della risposta rispetto alla domanda, penserebbe che all’interno della stanza c’è effettivamente qualcuno che parla, anzi che scrive in cinese.
Searle ha proposto questo “esperimento mentale” per mostrare come il test di Turing, del quale abbiamo parlato nel nostro primo articolo, dal titolo “Come l’intelligenza artificiale si comporta nell’imitazione del linguaggio“, non fornisca un criterio adeguato per affermare che una AI comprende un testo, ma solo che è in grado di manipolare simboli che hanno un significato solo per noi che li leggiamo.
Negli anni ’80 l’esperimento della camera cinese ha dato luogo a infuocati dibattiti fra informatici, psicologi e filosofi a proposito della possibilità o impossibilità della cosiddetta AI forte, cioè una AI che sappia comportarsi come un essere umano in una generica situazione e non in un campo specifico (a differenza dei sistemi esperti allora in voga, per esempio).
Possiamo ripetere per i LLM questi stessi interrogativi: per capire meglio se siano o meno una stanza cinese, o che senso abbia considerarli come tali, chiediamoci da dove viene l’apparente capacità di comprendere il linguaggio che essi hanno. Intanto ricordiamo la struttura macroscopica (assai semplificata) di un transformer, l’algoritmo che “predice” una sequenza di parole che ne segua un’altra in modo che questa predizione incontri l’aspettativa di chi leggerà l’output:
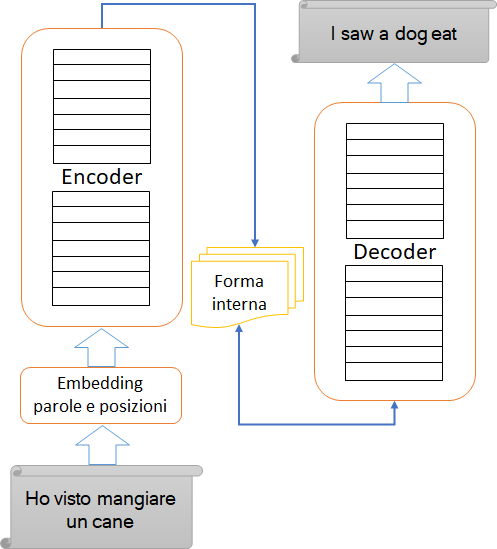
In sostanza questo algoritmo utilizza due reti neurali profonde: la prima per codificare le informazioni desunte dal testo (dalle parole e dalle loro posizioni nel testo, tradotte in numeri) in una forma interna che è una sorta di “zip” dei possibili esiti che il messaggio di input può implicare; la seconda rete profonda decodifica questa forma interna “zippata” in una sequenza che darà luogo al messaggio di output: nel caso della figura vediamo una rete addestrata a tradurre da una lingua all’altra.
Quindi che vuol dire che un LLM comprende? Che comprime! Il che non deve stupirci: la compressione è una forma di comprensione, perché quando comprimiamo una sequenza di dati, in modo da non perdere le informazioni che contengono (per intenderci ottenendo un file zip e non un file jpeg), ignoriamo tutte le ridondanze di quei dati lasciando solo le informazioni minime contenuti in essi che consentano di ricostruirli completamente.
Insomma, forse non ha senso dire che una AI comprende un testo ma possiamo dire che lo comprime, che riesce a trovare l’informazione minima nel nostro input e da essa ricostruire un output che la contenga e che elabori una risposta, per noi sensata, a partire da questa informazione.
Anche se forse non è il meccanismo che usa la nostra mente, il risultato è compatibile con la nostra aspettativa di significato: in questo forse sta l’essenza delle AI, non dobbiamo antropomorfizzarle, pensarle simili a noi solo perché producono risultati per noi intelligibili, ma presupporre che la loro comprensione e la loro conoscenza siano del tutto diverse dalle nostre e forse necessitino parole nuove per poter essere descritte in modo corretto.



